【深度学习】生成对抗网络 GAN
- 引言
- 算法简介
- 模型介绍
- 工作原理
引言
? ? ?生成式对抗网络(GAN, Generative Adversarial Networks)是一种深度学习模型,自从2014年Goodfellow提出了GAN以来,GAN已经成为近年来无监督学习最具前景的方法之一。
原文链接如下: Generative Adversarial Nets.
算法简介
? ? ?生成式对抗网络,它的主要目的是可以通过模型训练由输入的数据生成文字、图像、视频等数据。GAN模型主要包含两个模块:生成器(Generator)和判别器(Discriminator),我们可以将生成器与判别器看作是对抗博弈双方。下面举例来解释下GAN的基本思想。

? ? ?如上图所示,生成器与判别器的对抗过程就像假鞋工厂制造假鞋和球鞋鉴定师识别假鞋的过程。
【生成器G】相当于假鞋工厂,其目的是根据真鞋以及鉴定师的鉴定技术,去不断生成更加真实的、鉴定师难以识别的假鞋。
【判别器D】相当于鉴定师,其目的是尽可能地识别出假鞋工厂制造出来的假鞋。
这样通过假鞋工厂和鉴定师双方不断的较量,两者的较量过程:
假鞋工厂制造一些假球鞋 —> 球鞋鉴定师把假鞋识别出来 —> 假鞋工厂根据反馈改进假鞋的技术,制造新的假鞋 —> 球鞋鉴定师根据新的假鞋继续识别出来 —> …直到使得最后能达到鉴定师识别不出真假的效果(鉴定师识别真假鞋概率都为0.5)。
模型介绍
? ? ?通过上面的例子,已经可以大致明白GAN在做什么了把。接下来本文将对GAN进行展开。
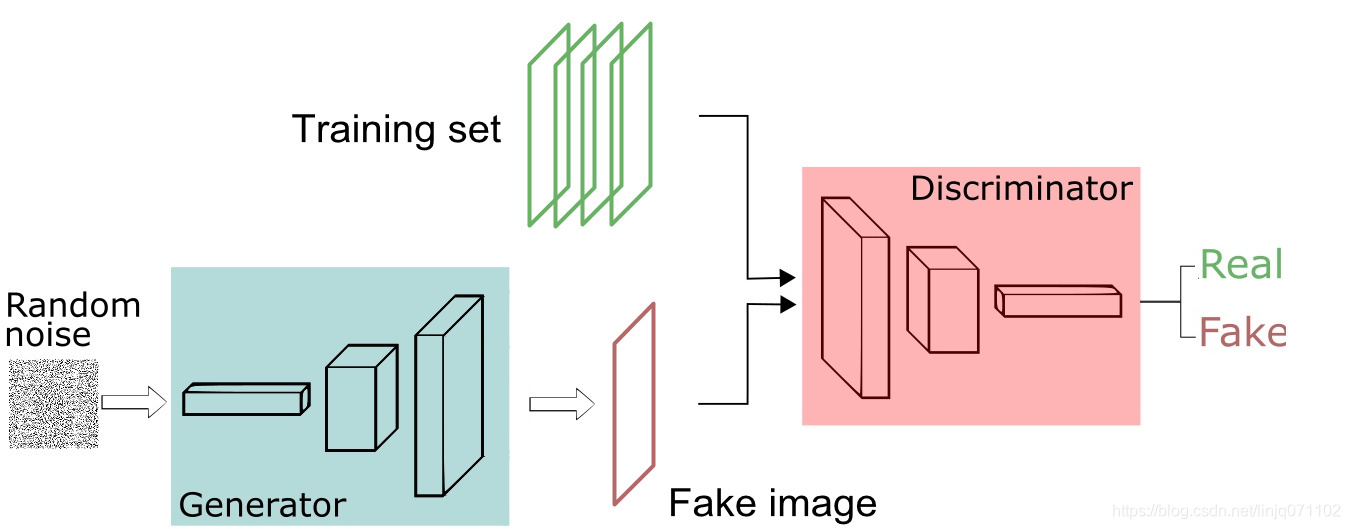
? ? ?假设现在有大量真实图片作为数据集,我们希望通过GAN生成一些能够以假乱真的图片。其主要由如下两个部分组成:
- 定义一个模型来作为生成器(Generator),生成器的输入是一个随机噪音向量,输出为真实图片大小的像素图像。
- 定义一个分类器来作为判别器(Discriminator),判别器用来判别输入的图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为图片,输出为判别图片的标签。
工作原理
? ? ?那么如果我们把刚才的假鞋工厂与球鞋鉴定师的场景映射成图片生成模型和判别模型之间的博弈,就变成了如下模式:生成器用随机噪音生成一些图片—>判别器学习区分生成的图片和真实图片—>生成器根据判别模型改进自己,生成新的图片—>…这样的博弈直到生成器与判别器无法提高自己而结束,即:判别器无法判断一张图片是由生成器生成的还是真实的。
接下来,本文将结合数学公式来描述整个博弈过程,这里任务对象为图像。假设生成器是
,其中
是一个随机噪声,而生成器将这个随机噪声转化为所需要生成的数据类型
,这里是图像;
是一个判别器,对任何输入
,
的输出是
范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。令
和
分别代表真实图像的分布与生成图像的分布,那么判别器的目标函数如下:
其中,
是指使得真实图像放入到判别器
中输出的值和整个式子值尽可能大,而
是指使得由生成器
生成的图像放入到判别器
中输出的值尽可能小,同时使得整个式子值尽可能大,这样的话就使得整体目标函数尽可能大,然后在训练时就可以根据目标函数进行梯度提升。
而生成器的目的是让判别器无法正确判别真实图片和生成器生成的图片,其目标函数为:
生成器生成的图片越真实,上式后半部分的
就越大,整个目标函数就越小,所以两者是相互对抗的。下面的Algorithm 1是GAN原文中的的一个算法流程。
 对于上面的最大最小化目标函数进行优化时,最直观的处理方式是将生成器
和判别器
进行交替迭代优化。首先,固定生成器
内的参数,来优化判别器
网络参数;然后反过来,固定判别器
中的参数,来优化生成器
网络中的参数。
对于上面的最大最小化目标函数进行优化时,最直观的处理方式是将生成器
和判别器
进行交替迭代优化。首先,固定生成器
内的参数,来优化判别器
网络参数;然后反过来,固定判别器
中的参数,来优化生成器
网络中的参数。
这里为了更好说明GAN博弈过程,我们举个例子,假设刚开始的真实样本分布、生成样本分布、判别模型分别对应左图的黑色点线、绿色实线、蓝色点线。下方的水平线是采样
的域,这里是均匀分布的。上面的水平线是
的域的一部分。向上的箭头表示映射
。

可以看出,在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成器,而优化判别器时,优化结果如图(b)所示,可以看出,这个时候判别器已经可以较好的区分生成数据和真实数据了。第三步是固定判别器,改进生成器,试图让判别器无法区分生成图片与真实图片,在这个过程中,可以看出由生成器生成的图片分布与真实图片分布更加接近,这样的迭代不断进行,直到最终收敛,生成分布和真实分布重合,此时判别器不能区分两者,即
。
?
如有错误,欢迎批评指出,谢谢!