整个机器学习的工程化落地过程,掺杂着很多与机器学习本身不很相关,却和基础设施、其他工程领域强相关且通用的事情。比如环境搭建,框架安装适配;模型部署,训练任务监控、可视化;任务调度、多租户等。而对于机器学习工程师来说,Ta们更擅长的是算法、模型。如何让机器学习快速落地产生价值、提供通用的能力就是机器学习平台的核心。
背景
近几年来,AI和大数据(还有少了很多热度的区块链)异常火热;不止是互联网,人工智能频频跻身两会热词,各个高校也都开展AI等相关专业。如果说作为一个互联网从业者到现在都还没有听过这些词汇,出去都不好意思说自己是搞IT的。作为一名开发者,其实我们更关心的是AI工程化、落地的过程。伴随着AI,经常出现的一个词是机器学习平台。相信很多人都听过平台的概念,所谓平台,也就是提供通用的技术or业务能力,以支持其他业务(技术)快速构建。但对于机器学习平台,我想作为一个不是很了解的人听到这个词汇的时候第一时间会冒出两个问题:为什么需要机器学习平台以及机器学习平台长什么样。其实机器学习平台,就是伴随着AI工程化落地而来的概念,所以我们先从AI工程化开始。然后试图去覆盖前面提到的两个问题。
前菜
关于AI和大数据的关系。如果把AI比作火箭,那么数据就是它的燃料。这个燃料可大可小,但是在当前的绝大部分AI算法中,都是越大越好。
关于AI(Artificial Intelligence)、ML(Machine Learning)、DP(Deep Learning)之间的关系。
AI是一个抽象的概念,为的是使机器表现出人的智能(比如图像/语音识别,翻译,预测…),而ML是实现AI的一种方法,也就是除了ML,还有其他的实现AI的方法。比如说一些搜索算法(经典的A*)。而DP则是ML的子类。也即是Scope包含的关系:

回到正题,所谓AI工程化,也即是将AI从论文里的算法、研究,经过一系列的工程手段,最终集成落地到具体的应用中;或者选择合适的模型和算法,经过一些优化,使得它能解决现实世界中真实的问题,并产生我们所需要的价值。是一个从学术研究领域到工程实践领域的一个过程。正因其原本是属于研究领域的事物,其门槛也是相当较高的(即使只做工程化落地,不去做学术研究)。
最简单的一个工程化落地的例子,也就是将一个算法(比如人脸识别),根据对应算法训练出来,得到一个模型。然后将模型发布成一个服务(或者软硬件结合),供其他应用(比如说门禁系统)使用,以达到使用刷脸进出的效果(价值)。回到我们熟悉的传统应用,从代码编写到部署成一服务供其他消费者使用,看起来好像是一样的流程,这也不难嘛!可事实真的是这样吗? 我们通过一个栗子来看一个简单落地过程,到底还需要些什么。
以下内容,以DP为例。
举个栗子
假如A是T公司的机器学习工程师,有一天A接到一个新的需求: 需要开发一个能够识别汽车上面的车标的模型,且准确率(这里不讨论评估指标,暂且使用准确率)在95%以上:
然后公司随即为A提供了工作环境:一台闪闪发光的GPU服务器和一台自己的工作电脑,个人独享(可以在上面为所欲为)。
假设A需要进行对比不同的模型来完成需求,这两种模型分别是来自不同的深度学习框架:Caffe和TensorFlow。拿到GPU服务器后的第一件事就是对服务器的配置(假设显卡已经装上),显然裸机是无法完成工作的。登录机器,发现这是一台CentOS的系统,显卡是让你打游戏能飞上天的NVIDIA Tesla V100显卡。那么,有哪些配置需要做呢?
首先,需要安装对应的官方显卡驱动(野鸡驱动是不行的),Nvidia专用的并行计算框架CUDA,以及针对深度神经网络的加速库cuDNN,注意各版本匹配!吭哧吭哧半天过去了。
然后,需要检查是否有对应版本的Caffe和TensorFlow框架(还需要GPU版本的)。吭哧吭哧又是大半天,特别是Caffe的编译安装,很是酸爽。
好了,有了环境之后就可以开始算法了吧,这个时候,你发现在本机开发不是一个很好的选择,因为本机没有对应的编程环境(比如难搞的Caffe),而且没有GPU,重新搭建一套环境指不定会出啥问题,毕竟本机的系统和服务器可不一样。那就上服务器开发吧,服务器大家都知道,黑盒子没有界面。怎么办呢,于是A灵机一动,在上面安装了Jupyter lab。打开Jupyter lab的UI,美滋滋。终于可以开始实现需求了。
与此同时,你发现并没有训练所需的数据(打上了标签的图片)供你使用,经过询问后。还好公司有提供一批数据,不然就得自己动手,一张一张吭哧吭哧了。然后把训练用的数据搞到服务器上,一番数据探索、预处理,代码编写、测试和折腾,写出了第一版,终于可以开始调参训练、优化了。伴随着一声清脆的回车,模型已经开始训练。可以摸鱼去了~
But,A怎么知道模型训练的情况呢?机智的A早已把关键地方的日志进行了输出,同时配备了对应框架的可视化工具(Tensorboard),以此来观察模型的训练情况。但还有一个比较头痛的问题是,这个训练什么时候能结束,万一异常失败了咋办?A也不知道,只能在摸鱼的同时,不时地去Check训练状态。
几天过后,训练完成,找到了最合适的算法和参数,出来的模型准确度也符合预期,万事大吉。
诶,等等。如何把这个模型发布成一个可供其他service调用的RESTful API(gRPC),如何保障部署服务的实时性、安全性、扩展性、AB Testing?
革命尚未成功,同志仍需吭哧吭哧…
为什么需要一个机器学习平台?
从上面的故事中我们可以看到,整个机器学习的工程化落地过程,其实掺杂着与很多机器学习本身不是很相关,但是和基础设施、或者其他工程领域强相关而且通用的事情。比如环境搭建,框架版本适配,模型部署,训练任务监控、可视化;任务调度、多租户等。而对于机器学习工程师来说,他们更擅长的是算法、模型、数据探索等工作;相对于工程化方面的能力,他们可能并不擅长(可能也并没有兴趣…)。当然,这还只是一个精简过的故事,如果是分布式训练,数据来源于分布式存储,那它的复杂度又上了一个台阶。
从上面的栗子,其实我们可以归纳出一个较为通用的机器学习落地过程,从原始数据的准备,到最后模型的部署。基本上所有的机器学习流程都带有这些阶段,我们用一张图来可视化:
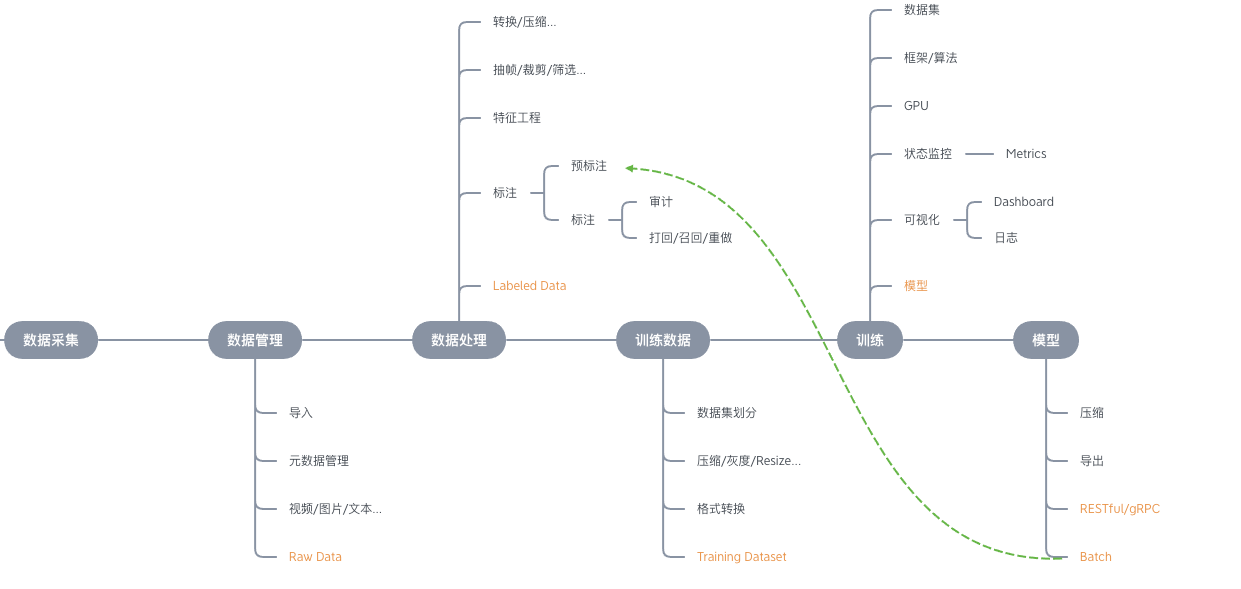
看到这一条流水线,很多人就自然而然想到了传统应用的CI/CD(持续集成、持续部署 & 持续交付)工具,比如Jenkins、GOCD。从一次代码的提交到最后产品的上线、各个环境的部署,整个过程都是可以自动化的,从而实现端到端的交付,一步到位。我们的确可以把一次机器学习过程看做是一条pipeline,里面划分了很多的stage,当然不是每个stage都是必须的,而是相对自由的组合。但传统的CI/CD工具并不能很好支持这个机器学习的pipeline(到目前为止)。
比方说,我们的训练Stage,可能需要不同的环境、框架,需要能够拥有调度的功能(GPU/CPU),感知训练状态;能够获取对应的训练数据(存储能力支持),而这些数据,一般来说都是大数据,存在于外部存储中(对象存储、HDFS、NFS…)。不能说通过传统的一个一个的下载的方式。而对于机器学习的测试,也不是写几个Case去测试算法代码,而是去测试训练出来的模型,比如评估模型的各种Metrics(准确度,精确率,召回率等)。这是传统CI/CD工具的局限性。
另一点,既然说自己解决这些基础设施的问题很麻烦,那可以交给专门的人(平台)去做啊,这个时候就自然而然想到了PaaS这个东西,它不就是专门做这个事的吗?环境、框架、资源调度,应用打包、发布,要啥有啥,给它我的代码和数据,万事大吉。
但传统的PaaS平台,仍旧有其不足性。于机器学习来说,首先,对GPU、分布式训练等有着近乎狂热的需求(也是氪金的需求)。所以对于GPU资源的管理和调度,分布式训练的部署等就显得很重要。传统的PaaS平台显然更擅长CPU、存储、无状态服务部署等,在这方面明显支持不足。同时,由于机器学习框架和环境的多样性,如何发布机器学习产出的模型。也和传统应用不一样。对于训练需要的数据准备工作而言,现有的PaaS平台更是很少有提供对应的标注工具。也就是对于机器学习整个流程的支持,传统PaaS还不足以支撑。
总结一下,CI/CD更擅长流程把控。这是我们所需要的。传统PaaS平台,擅长基础设施侧的工作。这也是我们所需要的,也就是:我全都要!!
这其实是一个PaaS平台和CI/CD的融合体,其中的一种实现,也就是机器学习平台。平台的好处,不用多说。有了平台后,这些工作(流程)就可以自动化、标准化、工程化。从而使机器学习工程师可以专注于业务开发。做他们最擅长的事。对企业而言,可以避免重复建设,统一管理资源和对接,为企业智能化发展提供基石。
在有了上面的Pipeline之后,我们就知道了作为一个机器学习平台,在整个机器学习过程中,应当具备哪些特性。
机器学习平台的特性
1.数据
对于机器学习来说,数据是非常重要的。前面也提过,就好比火箭的燃料。原始数据(图片、视频等),很好得来。当然也很好处理(格式转换、切分、resize等)。但是用于机器学习的数据(这里指标注后的数据)却不那么容易得到。一般来说,有三种渠道可以获得:
- 开源数据集
- 购买收费数据集
- 自己标注产生
再一般来说,企业内部的数据都是有专门的标注团队(或者第三方标注团队)产生的,毕竟每个企业的业务场景不一样,需要的数据也不一样。而数据,恰巧是企业的核心资产。想要从互联网上淘到自己想要的数据是非常难的(氪金除外),所以自己动手丰衣足食才是最好的选择。
而数据标注结果的标准化、规范化则有一定的难度。因为不同的算法、框架可能需要不同的数据格式。而且还需要支持不同的需求,比如基本的针对图片的目标检测、目标分类、语义分割等。同时,得具备一定扩展性和可操作性,扩展性是为了支持需求的扩展,而可操作性是为了支持不同数据格式的转换。
可以看到,对于数据,我们需要两个东西,第一是标注工具,第二是标注结果的标准化(也即是存储方式)。

那当我们要去做一件事的时候,其实最先思考的是别人有没有做过、别人是怎么做的,能不能拿来直接用,或者借鉴一下思路方便自己实现。首先我们会看有没有可以使用的开源标注工具。答案肯定是显而易见的。其实已经有很多开源的标注工具,比如针对图片标注的labelme,针对视频的cvat、vatic等。那问题来了,到底是使用开源工具还是自研?
对于开源工具来说。首先,对于集成、二次开发等难度是比较大的。其次,会有一些用户的需求无法完成,即是扩展性不高,比如说图片的3D标注,特征点标注等等。因而在有实力、有资本的情况下。自研是一种较好的选择。自研的标注工具,能更方便的拓展,改进,可以支持各种自定义的需求。与此同时,也沉淀了技术,甚至是标准!
对于数据格式的选择上,其实也是有一些规范的,比如coco/voc。在此,采取较为通用的存储格式 - coco是不错的选择,基于JOSN schema的coco格式,可读性很不错,同时可以扩展以支持更多的需求。 当然JOSN格式,也利于程序操作,方便和其他的格式进行转换。
2.数据处理
有了标注完成的数据之后,从原始标注数据到训练用的数据,中间其实还差了一些距离。比如有些算法不支持coco格式,需要做一些转换。或者是对于源数据(图片、视频)需要进一步处理(比如resize、compress等)才可以使用。有的数据(半结构化、结构化)数据需要进行特征工程等。
那么这部分对于机器学习平台来说应该是nice to have的,机器学习工程师可以自己对数据做处理,只需给到用户对应入口即可。但如果提供一些通用的处理方式给用户直接使用,会使得整个平台易用性更高、流程也更完整。比如各种开源格式之间的转换、数据的各种压缩、特征处理等。这部分有很大的扩展空间。
3.训练
除了数据,训练也就是机器学习过程的核心了。在这个点涉及更多跟基础设施有关的工作。期望的是在具备良好的可用性的同时,具备一定的自由度(扩展性)。
在训练上,就会涉及到不同的框架、不同的硬件支持、资源[计算(CPU/GPU)/存储]调度、不同任务的隔离、状态监控、数据可视化等。
对于易用性方面,需要内置一些经典的模型,以供用户可以直接使用,或者在此基础上进行二次训练使用。
灵活性方面,需要提供在线训练,类似于Jupyter lab这种支持用户自定义代码的工具,同时支持各种环境、框架,以及用户自己安装框架的功能。给予用户自由选择和使用的权利。
当然还有一个很重要的分布式训练功能,相对于前面提到的功能,这个可能更为难一点。但对于一个机器学习平台来说,随着企业规模的增大,数据量的增大;这个是必要的,早晚得上。

4.模型相关
当模型训练完成后,就会涉及到一些对模型的操作,比如模型压缩、模型度量、模型部署等。这里着重说下模型的部署。部署有很多种,但是最为常用的应该是模型的导出和发布成服务(RESTful Service/gRPC)了。
部署成一个服务,其实并不难。比如随便使用Flask或者其他Web框架包一层就可以用。但是得考虑到通用性,以及高可用、安全性、高性能,就不那么简单了。当然还有更高级的,比如模型的路由(A/B Test),模型组合等。
如何提供通用的模型部署功能,因为训练出的不同的模型需要不同的环境、框架支持,而且使用方式上也不一致。有些框架自带了Serving功能,比如TensorFlow,有些不带;这个还是差异较大的一块。
当然这个领域也有对应的开源解决方案,现在开源的较有名气的,比如说Seldon(kubeflow使用)/MLFLow。它们的解决思路其实类似,都是封装了流程,留白对应接口。用户只需要按照对应流程,使用对应工具,填充对应的空缺即可。可以理解为模板方法。如果要自研,可以借鉴它们的思路以满足自己的需要。需要考量的因素上面也提到了。
5.版本管理
模型是我们的产出,而且很明显,这个模型并不是训练好了就会一直使用,永不改变。它是在不断迭代、不断优化的,当然使用不同的版本来进行A/B Test也是很常见的需求。
在此时,针对模型(或者说是模型部署的服务)的版本管理就显得很重要了。这部分相对来说较为简单。不管是对模型本身、还是发布的服务都不是什么大问题。
6.Ops相关
这一部分其实贯穿了整个机器学习流程。比如:
- 任务调度 - 选择合适的机器或者集群去调度任务。
- 训练过程监控 - 比如任务状态、Metric变化等。
- 资源监控 - 比如GPU、CPU、存储使用情况。
- 日志可视化 - 比如任务运行的日志、平台本身的日志、用户操作的日志等。
- 当然还有多租户,一些安全性的问题,比如模型发布的服务权限管理,用户操作的权限等。
这部分都是偏技术的问题,不是特别难,但是坑比较多。基础版本做起来简单,但是做到高可用、易用性和健壮性就不会简单,毕竟这是贴近底层的一层。
7.高级特性
一些高级的功能,比如AutoML:
超参数训练,让平台能够使用不同算法自动获取超参数,比如使用常见的Random Search、Grid Search 和贝叶斯优化方法等进行调参。
模型结构搜索,这个就更高级了,需要更深厚的专业领域知识和对应的工程化能力。
当然,还有一些,比较高级的用于可视化或者降低机器学习门槛的功能。比如模型结构的可视化以及通过可视化的方式建模。这些已经有机器学习平台实现了,比如阿里的PAI。再比如能写SQL就能写AI的SQLFlow。

总结
对于一个机器学习平台。困难的核心点有如下几个:
- 到目前为止,有许多东西是没有一个统一的标准的,比如数据标注结果的存储格式。
- 有太多的框架,太多的环境,太多的版本,与之对应,不同框架最后生成的模型。也都是各不相同的,如果想要实现标准的模型压缩、发布,也是比较困难的一件事。
- 在往下,机器学习太依赖于GPU,对于GPU的管理、调度。目前来说也不是非常成熟的一件事(比如说GPU虚拟化),特别是不同的GPU也是不一样的;即便是同一厂商,比如Nvidia,对于不同型号的显卡,同一模型也不一定能正常运行。尽管现在可以通过某些手段,比如说CUDA来屏蔽不同显卡的差异性。但难免有些模型直接操作的GPU指令集,比如Caffe。
- 分布式训练。这块目前正在快速发展中,坑还是挺多,不是非常成熟,需要一一淌下。
差异性,和没有标准是痛点的来源。但随着机器学习在工程领域的发展,标准只是早晚的事。不少开源框架已经开始做起来了,解决机器学习落地的各阶段问题,并试图建立自己的标准。如何解决差异性?我觉得答案是封装和抽象,封装底层差异,对外暴露统一抽象层接口。有句话说得好,在软件工程领域,没有什么是不能通过封装抽象加一层解决的问题。如果有,那再来一层!!
以上内容,为项目上的实践,以及个人理解总结而来。
如有不对的地方,欢迎指正,万分感谢~~
文/ThoughtWorks彭青松