卷积神经网络有效地利用词序进行文本分类(2015年)
code:https://github.com/tensorflow/models/tree/master/research/sentiment_analysis(但是这份代码只是简单实现了parallel CNN,并没有实现seqCNN和bowCNN,聊胜于无)
摘要
卷积神经网络(CNN)是可以利用数据的内部结构(例如图像数据的2D结构)的神经网络。 本文研究CNN的文本分类,以利用文本数据的一维结构(即单词顺序)进行准确预测。 与其像通常那样将低维单词向量用作输入,不如将CNN直接应用于高维文本数据,直接学习嵌入小文本区域的嵌入矩阵以用于分类。 除了将CNN从图像直接转换为文本之外,还提出了一种简单而新颖的变体,该变体在卷积层中采用了词袋转换。 还探索了组合多个卷积层的扩展,以提高准确性。 实验证明了我们的方法与最新技术方法相比的有效性。
1.介绍
文本分类是自动为以自然语言编写的文档分配预定义类别的任务。 不同的文本分类任务处理不同类型的文档,例如主题分类以检测讨论的主题(例如,体育,政治),垃圾邮件检测以及确定产品或电影评论中通常具有的情感的情感分类 。文本分类的一种标准方法是通过词袋矢量(即表示哪些单词出现在文档中但不保留单词顺序的矢量)表示文档,并使用诸如SVM的分类模型。
已经注意到,由词袋向量引起的词序的损失在情感分类上是一个尤为严重的问题。 一种简单的补救方法是,除了使用uni-gram外,还使用bi-gram。 但是,一般来说,在文本分类中使用n > 1的n-gram词并不总是有效的。 例如,关于主题分类,仅添加短语或n-gram无效。
为了从文本分类中的单词顺序中受益,我们采用了不同的方法,该方法采用了卷积神经网络。 CNN是一种神经网络,可以通过卷积层利用数据的内部结构(例如图像数据的2D结构),其中每个计算单元都对输入数据的较小区域(例如大图像的小方块)做出响应 。 我们将CNN应用于文本分类,以利用文档数据的1D结构(单词顺序),以便卷积层中的每个单元都响应文档的一小部分区域(单词序列)。
在文本上,由于Collobert等人(2011年)在令牌级应用程序(例如POS标记)方面的工作,CNN已用于实体搜索,句子建模,单词嵌入学习,产品特征挖掘等系统中。 值得注意的是,在许多有关文本的CNN研究中,网络的第一层通过查表将句子中的单词转换为词向量。词向量既可以作为CNN训练的一部分进行训练,也可以固定为通过某种其他方法(例如word2vec)从其他大型语料库中获得的向量。 后者是半监督学习的一种形式,我们将在其他地方进行学习。 我们对CNN本身的有效性感兴趣,而无需借助其他资源; 因此,如果要进行字向量查找,则应将字向量作为网络训练的一部分进行训练。
但是,出现一个问题,在纯监督环境中查找单词向量是否真的对文本分类有用。卷积层的本质是将固定大小(例如,大小为3的“am so happy”)的文本区域转换为特征向量,如稍后所述。从这个意义上讲,词向量学习层是区域大小为1的卷积层的一种特殊情况。如果bi-gram比uni-gram更具区分性,为什么1这个尺寸合适呢?因此,我们采用了不同的方法。我们将CNN直接应用于高维one-hot向量;即,我们无需进行词嵌入学习,即可直接学习文本区域的嵌入。通过在GPU上高效处理高维稀疏数据来解决计算问题(正常的CNN网络是无法高效处理稀疏数据的),从而使这种方法成为可能,并且它具有通过快速训练/预测来提高准确性并简化系统的优点(需要调整的超参数更少) 。
我们研究了CNN在文本分类上的有效性,并解释了CNN为什么适合该任务。 测试了两种类型的CNN:seq-CNN是CNN从图像到文本的直接改编,而bow-CNN是CNN的一种简单但新的变体,在卷积层中采用了词袋转换。 实验表明,在情感分类上,seq-CNN的表现优于bow-CNN,在主题分类上则相反,而优胜者的表现通常优于传统的基于bag-of-n-gram矢量的方法,以及之前复杂的文本CNN模型 。 特别是,据我们所知,这是成功使用词序来改善主题分类性能的第一部作品。 结合了多个卷积层的简单扩展(从而结合了多种类型的文本区域嵌入)可带来进一步的改进。 通过经验分析,我们将证明当传统方法失败时,CNN可以有效利用高阶n元语法。
2.CNN用于文本分类
我们首先回顾一下CNN在图像数据中的应用,然后讨论CNN在文档分类任务中的应用,以介绍seq-CNN和bow-CNN。
2.1CNN用于图像
略。
2.2CNN用于文本
现在考虑将CNN用于文本数据,给定文本D=(w1,w2,...),字典V。CNN需要数据的矢量表示形式保留内部位置(在这种情况下为单词顺序)作为输入。 直接表示是将每个单词视为一个像素,将D视为|D|×1的图像,拥有|V|个 通道,并将每个像素(即每个单词)表示为| V |维one-hot向量。假设V = { “don’t”, “hate”, “I”, “it”, “love” } ,D='I love it',那我们就可以得到一个文档向量:
x = [ 0 0 1 0 0 | 0 0 0 0 1 | 0 0 0 1 0 ]T.
2.2.1 seq-CNN
像在图像的卷积层中一样,我们通过像素的连接表示每个区域(每个计算单元响应),这将生成p *|V|维的区域向量,其中p是预先确定的区域大小。例如,在上面的示例文档向量x中,p = 2并且跨度为1,我们将有两个区域“ I love”和“ love it”,分别由以下向量表示:
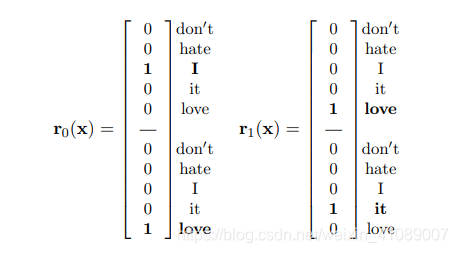
其余部分与图片相同; 文本区域向量将转换为特征向量,即卷积层将文本区域嵌入到低维向量空间中。 我们称具有这种区域表示的卷积神经网络为seq-CNN(“ seq”指保留单词序列),以将其与bow-CNN区别开来。
2.2.2 bow-CNN
但是,seq-CNN的潜在问题是,与具有3个RGB通道的图像数据不同,“通道”的数量| V | (词汇的大小)可能非常大(例如100K),如果区域大小p也很大,则可能会使每个区域向量r(x)具有很高的维数。 由于区域向量的维数决定权重向量的维数,因此具有高维区域向量意味着需要学习更多的参数。 如果p*|V| 太大,模型变得太复杂(无法获得可用的训练数据量),即使有效处理稀疏数据,训练也变得负担不起; 因此,必须通过减小词汇量| V |或区域大小p来降低维度,这可能取决于任务的性质,也可能不符合要求。
我们提供的另一种方法是执行词袋转换以使区域向量|V|维代替p*|V|维; 例如,上面的示例区域矢量将被转换为:
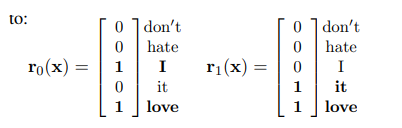
通过这种表示,我们需要学习的参数更少。 本质上,词袋卷积的表达(仅在小区域内失去单词顺序)介于seq卷积和词袋矢量之间。
2.2.3 Pooling for text
尽管图像大小在图像应用程序中是固定的,但是文档自然是可变大小的,因此,跨步固定时,卷积层的输出也是可变大小的,如图3所示。 在卷积层中,图像的标准合并(使用固定的合并区域大小和固定的跨度)将产生可变大小的输出,该输出可以传递到另一个卷积层。 为了产生固定大小的输出,这是完全连接的顶层所需的,我们固定池单元的数量,并动态确定每个数据点上的池区域大小,以便整个数据覆盖重叠。
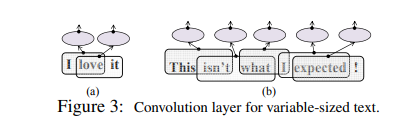
在之前的CNN文本研究中,池化通常是整个数据的最大池化(即,与整个文本关联的一个池化单元)。 (Kalchbrenner et al,2014)的动态k-max池用于句子建模,将其扩展为k个最大值,其中k是句子长度的函数,但它又遍及整个数据,并且操作限于最大池化。 我们的池化的不同之处在于,它是对图像标准池化的自然扩展,不仅可以应用最大池化,还可以应用其他类型。 通过与不同区域关联的多个池化单元,顶层可以接收位置信息(例如,如果有两个池化单元,则区分来自文档的前半部分和后半部分的特征)。 事实证明,这对主题分类很有用。
2.3 CNN和bag-of-n-grams
传统方法用一个n-gram袋矢量完全表示每个文档,然后应用分类器模型(例如SVM)。 但是,由于高阶n元语法容易受到数据稀疏性的影响,因此使用大n(例如20)不仅不可行,而且无效。 还要注意,一个n-gram袋由一个one-hot向量表示每个n-gram,而忽略了某些n-gram共享组成词的事实。 相比之下,CNN会在内部学习对预期任务有用的文本区域的嵌入(给定组成词作为输入)。 因此,特别是在bow卷积层中可以使用较大的n(例如20),这对主题分类很有用。 例如,一个对“I love”分配较大的值(而对"I hate"分配较小的值)的神经元会为“we love”分配较大的值,而对“we hate”的分配较小的值,即使在训练期间从未见过“we love”。 我们将在以后根据试验确认这些观点。
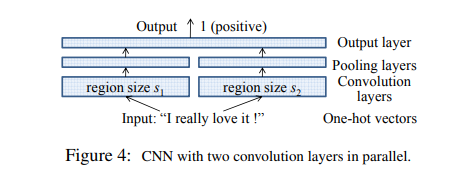
2.4 拓展:parallel CNN
我们已经用具有一对卷积和池化层的最简单的网络体系结构描述了CNN。 尽管可以通过多种方式(例如,使用更深的层)进行扩展,但在我们的实验中,我们探索了并行CNN,该并行CNN具有并行的两个或多个卷积层,如图4所示。其思想是学习多种类型的小文本区域嵌入,以便它们可以相互补充以提高模型准确性。 在这种体系结构中,具有不同区域大小(可能还有不同区域矢量表示)的多个卷积池对被赋予一个热矢量作为输入,并为每个区域生成特征矢量。 顶层将产生的特征向量的串联作为输入。
3.实验
激活函数:Relu 优化函数:SGD region size:3
Out-of-vocabulary words were represented by a zero vector。
在Bow-CNN上,为了加快计算速度,我们使用了可变区域步幅,以便采取更大的步幅,这样可以避免重复执行相同区域向量。 填充大小固定为p -1,其中p是区域大小。(The purpose is to equally treat the words at the edge and words in the middle.)
CNN with one convolution layer (seq- and bow-CNN in the table).
现在我们转向并行CNN。 在IMDB上,seq2-CNN具有两个seq-卷积层(区域大小2和3;每个1000个神经元;随后每个单位最大池),其性能优于seq-CNN。 随着神经元数量的增加(每个神经元3000个;表3),它进一步超过了表现最佳的基线,这也是先前获得的最佳监督结果。 我们假设seq2-CNN的有效性表明预测文本区域的长度是可变的。
效果最好的模型:‘seq2-bown-CNN’, 3个并行层: two seq-convolution layers (1000 neurons each) as in seq2-CNN above and one layer (20 neurons) that regards the entire document as one region and represents the region (document) by a bag-of-n-gram vector (bow3) as input to the computation unit。
特别是,由于NB-LM的良好性能,我们通过将NB权重乘以二进制向量来生成bow3向量。 第三层是一个bow卷积层,具有一个可变大小的区域,该区域采用具有n-gram词汇量的one-hot向量作为输入来学习文档嵌入。
4.结论
本文表明,CNN通过直接嵌入小的文本区域提供了一种有效地使用单词顺序进行文本分类的替代机制,这与传统的NNG方法或单词向量CNN不同。 使用并行的CNN框架,可以学习和组合几种类型的嵌入,以便它们可以相互补充以提高准确性。 使用这种方法可以达到目前情绪分类和主题分类方面的最好效果。
最近开始研究情感分类模型,按时间顺序阅读一些相关论文,这里记录一下~