前言
最近我们正式调研Zeppelin作为Flink SQL开发套件的可能性,于是clone了最新的Zeppelin v0.10-SNAPSHOT源码,自行编译并部署到了预发布环境的新Flink集群中。Flink版本为1.13.0,Hadoop版本为CDH 6.3.2自带的3.0.0。经过两天的探索,发现了一些问题,在百忙之中抽出点时间简要记录一下并不成功的troubleshooting过程。

Flink Interpreter不加载
安装好Zeppelin并配置好Flink Interpreter的各项参数之后(采用生产环境推荐的Flink on YARN + Interpreter on YARN + Isolated Per Note模式),编写Note无法执行,提示找不到FlinkInterpreter类,如下图所示。
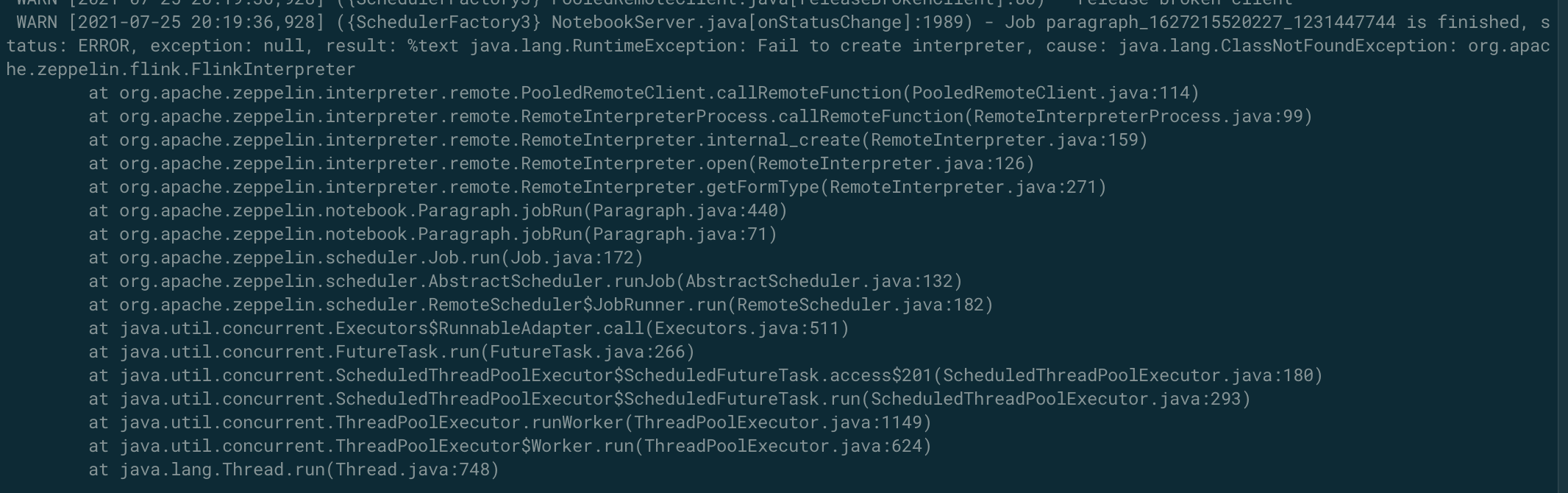
排查:
- 去${ZEPPELIN_HOME}/interpreter/flink目录下观察,可以发现名为zeppelin-flink-0.10.0-SNAPSHOT-2.11/2.12.jar的两个JAR包,并且FlinkInterpreter已经被正确地打进了JAR包里。
- 去zeppelin-env.sh中修改
ZEPPELIN_JAVA_OPTS环境变量,添加-verbose:class参数打印类加载日志,从中未发现任何以org.apache.zeppelin.flink为前缀的类被加载。 - 登录Interpreter进程所在的那台NodeManager,查看Interpreter的临时目录,结构如下图。

但是,Interpreter进程的classpath中并没有zeppelin/interpreter/flink/*,自然无法加载Interpreter了。为什么会这样?来到负责启动Interpreter的bin/interpreter.sh文件,第125行:
INTERPRETER_ID=$(basename "${INTERPRETER_DIR}")
if [[ "${INTERPRETER_ID}" != "flink" ]]; then# don't add interpreter jar for flink, FlinkInterpreterLauncher will choose the right interpreter jar based# on scala version of current FLINK_HOME.addJarInDirForIntp "${INTERPRETER_DIR}"
fi可见这里对Flink做了一个特殊的处理。根据注释的描述,FlinkInterpreterLauncher会根据用户的Flink版本选择对应Scala版本的JAR包。查看该类的源码,确实如此(有一个chooseFlinkAppJar()方法,略去)。然而继续向上追踪FlinkInterpreterLauncher的调用链,发现它并没有在任何与YARN有关的方法中被使用,也就是说上面选择JAR包的动作根本没发生。
由于我们仍然仅使用基于Scala 2.11的Flink,故可以将目录中的2.12包删掉,并修改interpreter.sh注释掉if语句,问题临时解决。更好的解决方法是将上述的选择JAR包逻辑写入YARN Launcher内,但侵入性较大,留待今后操作。
YARN Application模式无效
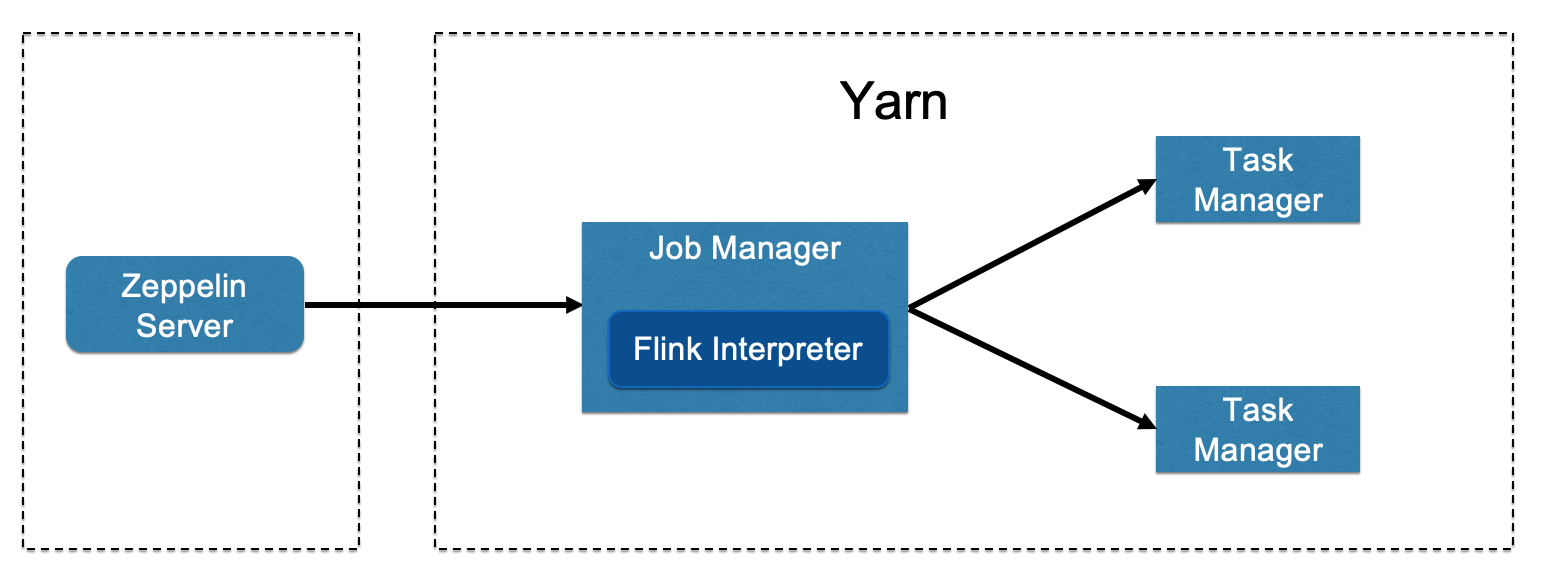
根据文档描述,YARN Application模式与普通的YARN模式相比会更节省资源,因为JobManager和Interpreter跑在一个Container内,如下图所示。
我们确认与Hadoop相关的各项参数、环境变量都设置好之后,将Note的flink.execution.mode参数改为yarn-application,运行之,报出如下异常。
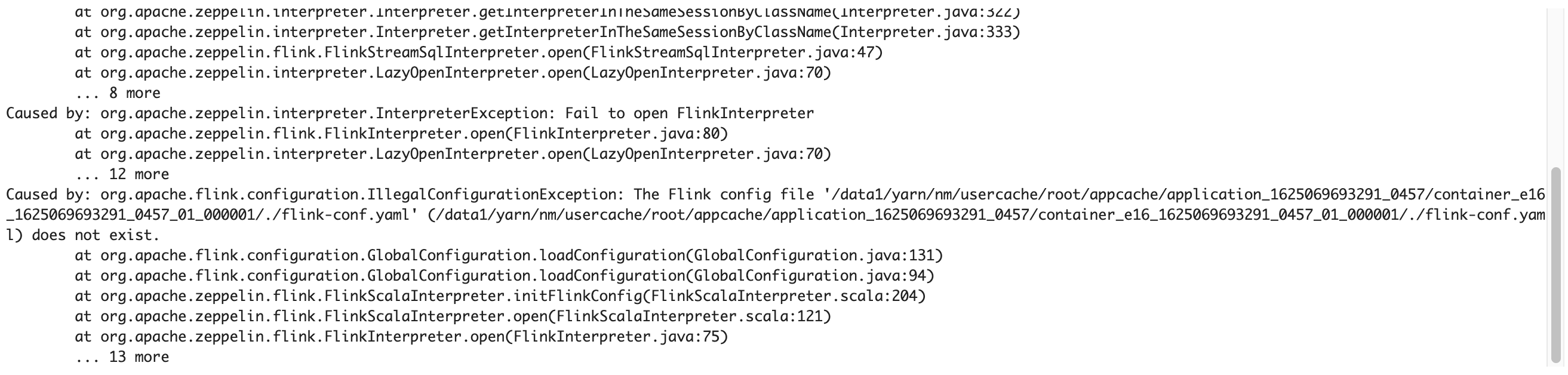
对比一下上节贴出的Interpreter临时目录结构,容易发现这里的路径是错的。来到FlinkScalaInterpreter类,将flinkHome、flinkConfDir、hiveConfDir做如下的修改。
mode = ExecutionMode.withName(properties.getProperty("flink.execution.mode", "LOCAL").replace("-", "_").toUpperCase)
if (mode == ExecutionMode.YARN_APPLICATION) {if (flinkVersion.isFlink110) {throw new Exception("yarn-application mode is only supported after Flink 1.11")}// use current yarn container working directory as FLINK_HOME, FLINK_CONF_DIR and HIVE_CONF_DIRval workingDirectory = new File(".").getAbsolutePathflinkHome = workingDirectory + "/flink"flinkConfDir = workingDirectory + "/flink/conf"hiveConfDir = workingDirectory + "/hive_conf"
}重新编译打包并替换掉原来的Interpreter包,再次执行,又报出如下异常,提示Application ID为空。

话休絮烦,直接贴出对应的源码:
val (effectiveConfig, cluster) = fetchConnectionInfo(config, configuration, flinkShims)
this.configuration = effectiveConfig
cluster match {case Some(clusterClient) =>// local mode or yarnif (mode == ExecutionMode.LOCAL) {LOGGER.info("Starting FlinkCluster in local mode")this.jmWebUrl = clusterClient.getWebInterfaceURLthis.displayedJMWebUrl = this.jmWebUrl} else if (mode == ExecutionMode.YARN) {LOGGER.info("Starting FlinkCluster in yarn mode")this.jmWebUrl = clusterClient.getWebInterfaceURLval yarnAppId = HadoopUtils.getYarnAppId(clusterClient)this.displayedJMWebUrl = getDisplayedJMWebUrl(yarnAppId)} else {throw new Exception("Starting FlinkCluster in invalid mode: " + mode)}case None =>// yarn-application modeif (mode == ExecutionMode.YARN_APPLICATION) {// get yarnAppId from env `_APP_ID`val yarnAppId = System.getenv("_APP_ID")LOGGER.info("Use FlinkCluster in yarn application mode, appId: {}", yarnAppId)this.jmWebUrl = "http://localhost:" + HadoopUtils.getFlinkRestPort(yarnAppId)this.displayedJMWebUrl = getDisplayedJMWebUrl(yarnAppId)} else {LOGGER.info("Use FlinkCluster in remote mode")this.jmWebUrl = "http://" + config.host.get + ":" + config.port.getthis.displayedJMWebUrl = getDisplayedJMWebUrl("")}
}@Internal
def fetchConnectionInfo(config: Config,flinkConfig: Configuration,flinkShims: FlinkShims): (Configuration, Option[ClusterClient[_]]) = {config.executionMode match {case ExecutionMode.LOCAL => createLocalClusterAndConfig(flinkConfig)case ExecutionMode.REMOTE => createRemoteConfig(config, flinkConfig)case ExecutionMode.YARN => createYarnClusterIfNeededAndGetConfig(config, flinkConfig, flinkShims)case ExecutionMode.YARN_APPLICATION => (flinkConfig, None)case ExecutionMode.UNDEFINED => // Wrong inputthrow new IllegalArgumentException("please specify execution mode:\n" +"[local | remote <host> <port> | yarn | yarn-application ]")}
}上面的代码有些令人迷惑:为什么YARN Application模式下没有做任何操作,只是返回了一个空的ClusterClient?另外,_APP_ID是Flink ApplicationMaster启动时设置的环境变量,这样操作一定可以拿得到么?
当然这个问题比较复杂,笔者也尚未认真研究过YARN Application模式相关的源码,需要时间来处理。但可以肯定至少在我们的环境下,需要做较大的改动才能让它正常使用。在完全解决之前,仍然采用传统YARN模式也无伤大雅。
配置Note只读权限后无法切换视图
为了保证安全,我们强制新建的Note都为私有(即Reader、Writer、Runner、Owner初始值都是用户自己),然后按需对相关同学开放权限。
一般情况下,所有人都可以读Note。但是只将Reader权限放开后,除Owner之外的人看到的都是白板。这是因为Note对只读权限者变成了report视图,只能看到结果,不展示SQL源码,如下图所示。
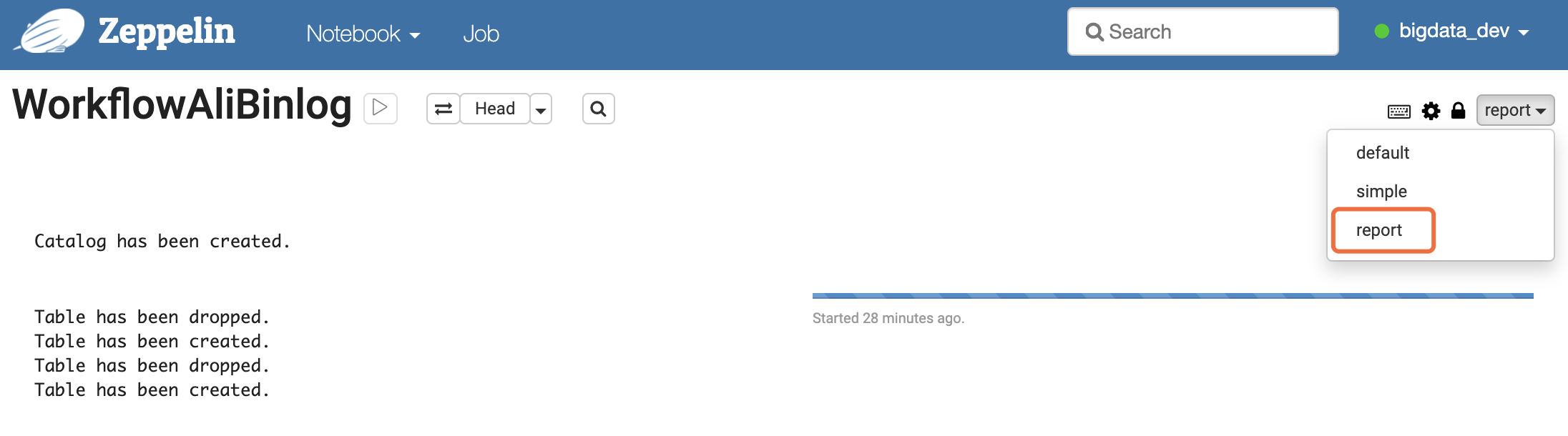
但是,如果尝试切换成default视图,就会提示需要Writer权限才可以:
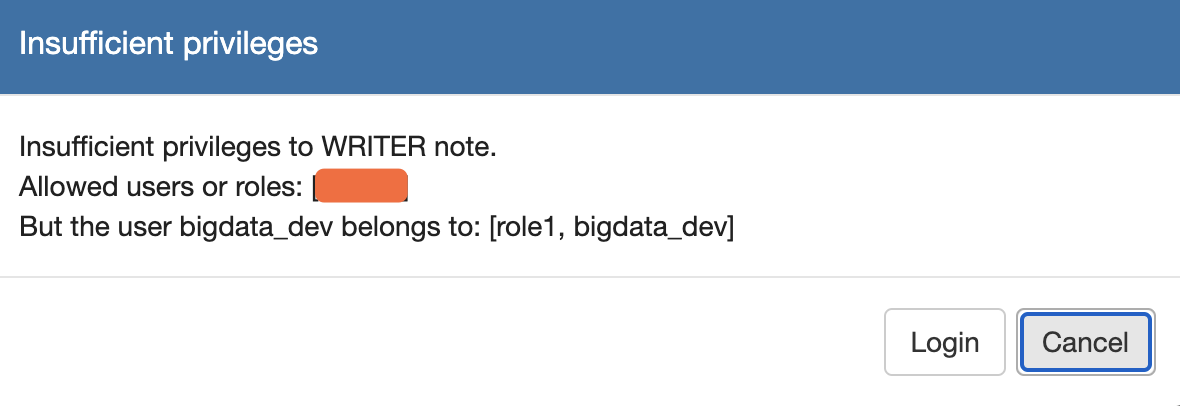
这就有些匪夷所思了。将Zeppelin日志等级设为DEBUG,重复切换视图操作,可以发现在NotebookServer的事件循环里产生了NOTE_UPDATE事件。
DEBUG [2021-07-28 19:03:52,097] ({qtp306612792-317} NotebookServer.java[onMessage]:255) - RECEIVE: NOTE_UPDATE, RECEIVE PRINCIPAL: bigdata_dev, RECEIVE TICKET: f9118802-14cd-40fc-8e60-caeb0267aac2, RECEIVE ROLES: ["role1"], RECEIVE DATA: {id=2GE65N3RS, name=WorkflowAliBinlog, config={isZeppelinNotebookCronEnable=false, looknfeel=default, personalizedMode=false}}WARN [2021-07-28 19:03:52,098] ({qtp306612792-317} SimpleServiceCallback.java[onFailure]:50) - HTTP 403 Forbidden这是因为Note的视图风格直接存储在.zpln文件内(叫做looknfeel),所以修改它就相当于修改Note了 = =
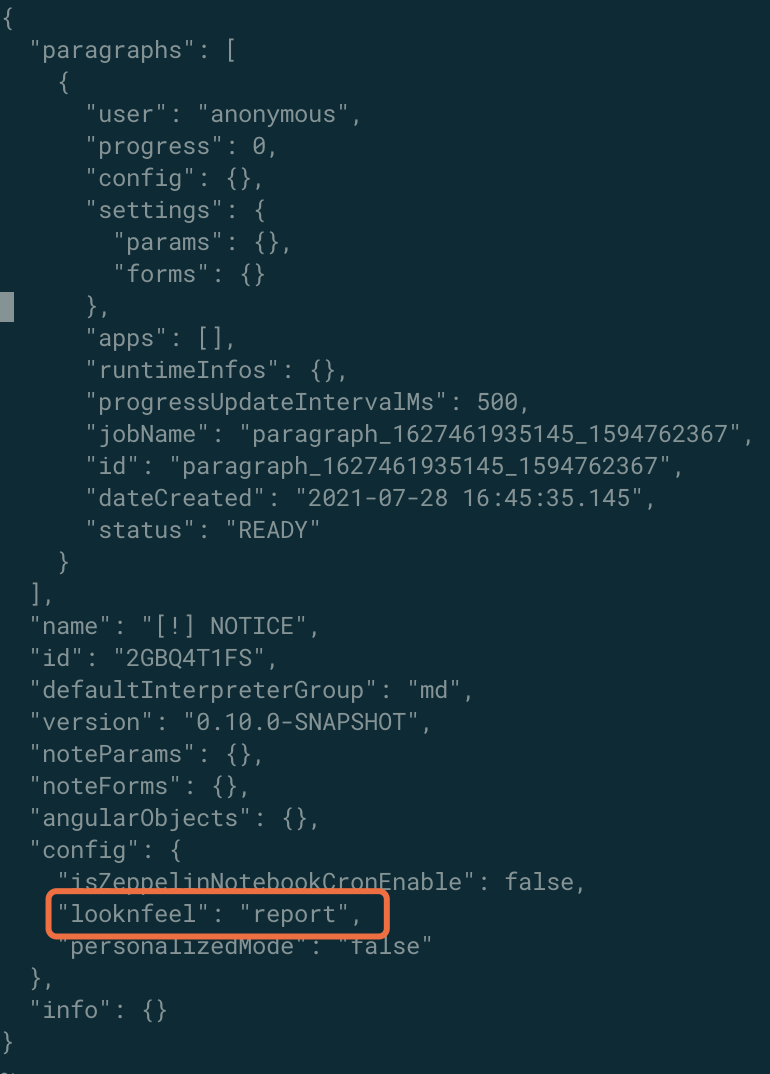
将NOTE_UPDATE的权限赋给Reader显然不现实,考虑到我们几乎不会用到simple和report视图,将simple视图作为只读的情况比较合适。
但是,来到zeppelin-web项目下之后,发现代码只读性、代码编辑器的可见性和视图之间的耦合过紧,改了数十处HTML和JS代码之后仍然未能达到想要的效果。经过试验,只读用户还是可以看到非HEAD commit的代码的,切换版本凑合也能用,此事暂时搁置。
Zeppelin日志被"Saving note"信息淹没
我们采用的Notebook Repo是GitNotebookRepo(本地)+FileSystemNotebookRepo(远程HDFS)的组合。启动了几个Flink SQL任务之后,在Zeppelin日志中看到如下格式的信息刷屏。
INFO [2021-07-30 19:32:10,160] ({pool-11-thread-16} VFSNotebookRepo.java[save]:144) - Saving note 2GDVAVC4W to etl-mq/analytics_access_log_app_2GDVAVC4W.zpln这是因为在每个Note对应作业的JobManager中,都会启动一个名为FlinkJobProgressPoller的线程,以zeppelin.flink.job.check_interval的间隔(默认1秒,我们改成了5秒)检查并更新任务的状态。如上一节所述,这些信息也都保存在.zpln文件内,所以会导致频繁写文件。并且这个线程做的事情非常多,代码如下所示。
@Override
public void run() {while (!Thread.currentThread().isInterrupted() && running.get()) {JsonNode rootNode = null;try {synchronized (running) {running.wait(checkInterval);}rootNode = Unirest.get(flinkWebUrl + "/jobs/" + jobId.toString()).asJson().getBody();JSONArray vertices = rootNode.getObject().getJSONArray("vertices");int totalTasks = 0;int finishedTasks = 0;for (int i = 0; i < vertices.length(); ++i) {JSONObject vertex = vertices.getJSONObject(i);totalTasks += vertex.getInt("parallelism");finishedTasks += vertex.getJSONObject("tasks").getInt("FINISHED");}LOGGER.debug("Total tasks:" + totalTasks);LOGGER.debug("Finished tasks:" + finishedTasks);if (finishedTasks != 0) {this.progress = finishedTasks * 100 / totalTasks;LOGGER.debug("Progress: " + this.progress);}String jobState = rootNode.getObject().getString("state");if (jobState.equalsIgnoreCase("finished")) {break;}long duration = rootNode.getObject().getLong("duration") / 1000;if (isStreamingInsertInto) {if (isFirstPoll) {StringBuilder builder = new StringBuilder("%angular ");builder.append("<h1>Duration: {
{duration}} </h1>");builder.append("\n%text ");context.out.clear(false);context.out.write(builder.toString());context.out.flush();isFirstPoll = false;}context.getAngularObjectRegistry().add("duration",toRichTimeDuration(duration),context.getNoteId(),context.getParagraphId());}// fetch checkpoints info and save the latest checkpoint into paragraph's config.rootNode = Unirest.get(flinkWebUrl + "/jobs/" + jobId.toString() + "/checkpoints").asJson().getBody();if (rootNode.getObject().has("latest")) {JSONObject latestObject = rootNode.getObject().getJSONObject("latest");if (latestObject.has("completed") && latestObject.get("completed") instanceof JSONObject) {JSONObject completedObject = latestObject.getJSONObject("completed");if (completedObject.has("external_path")) {String checkpointPath = completedObject.getString("external_path");LOGGER.debug("Latest checkpoint path: {}", checkpointPath);if (!StringUtils.isBlank(checkpointPath) && !checkpointPath.equals(latestCheckpointPath)Map<String, String> config = new HashMap<>();config.put(LATEST_CHECKPOINT_PATH, checkpointPath);context.getIntpEventClient().updateParagraphConfig(context.getNoteId(), context.getParagraphId(), config);latestCheckpointPath = checkpointPath;}}}}} catch (Exception e) {LOGGER.error("Fail to poll flink job progress via rest api", e);}}
}考虑到直接对它下手的复杂度,目前只能暂时在log4j配置中屏蔽掉VFSNotebookRepo的INFO日志输出。随着今后任务增多,会继续评估Zeppelin Server和磁盘的压力,并尽可能寻找优化的方法。
The End
其实还有个Maven Repo解析与添加Nexus私服认证方面的问题,但这个更复杂,并且与Flink无关,就不废话了。
民那周末快乐~