引言
在这篇文章中,我会详细地介绍Bagging、随机森林和AdaBoost算法的实现,并比较它们之间的优缺点,并用scikit-learn分别实现了这3种算法来拟合Wine数据集。全篇文章伴随着实例,由浅入深,看过这篇文章以后,相信大家一定对ensemble的这些方法有了很清晰地了解。
Bagging
bagging能提升机器学习算法的稳定性和准确性,它可以减少模型的方差从而避免overfitting。它通常应用在决策树方法中,其实它可以应用到任何其它机器学习算法中。如果大家对决策树的算法不太理解,请大家参考这篇文章:决策树ID3、C4.5、C5.0以及CART算法之间的比较,在下面的例子中,都会涉及到决策树,希望大家能理解一下这个算法。
下面,我介绍一下bagging技术的过程:
假设我有一个大小为n的训练集D,bagging会从D中有放回的均匀地抽样,假设我用bagging生成了m个新的训练集Di,每个Di的大小为j。由于我有放回的进行抽样,那么在Di中的样本有可能是重复的。如果j=n,这种取样称为bootstrap取样。现在,我们可以用上面的m个训练集来拟合m个模型,然后结合这些模型进行预测。对于回归问题来说,我们平均这些模型的输出;对于分类问题来说,我们进行投票(voting)。bagging可以改良不稳定算法的性能,比如:人工神经网络、CART等等。下面,我举一个具体的例子说明一下bagging。
假设有一个训练集D的大小为7,我想用bagging生成3个新的训练集Di,每个Di的大小为7,结果如下表:
| 样本索引 | bagging(D1) | bagging(D2) | bagging(D3) |
|---|---|---|---|
| 1 | 2 | 7 | 3 |
| 2 | 2 | 3 | 4 |
| 3 | 1 | 2 | 3 |
| 4 | 3 | 1 | 3 |
| 5 | 5 | 1 | 6 |
| 6 | 2 | 5 | 1 |
| 7 | 6 | 4 | 1 |
那么现在我就可以用上面生成的3个新训练集来拟合模型了。
决策树是一个很流行的机器学习算法。这个算法的性能在特征值的缩放和各种转换的情况下依然保持不变,即使在包含不相关特征的前提下,它依然很健壮。然而,决策树很容易过拟合训练集。它有低的偏差,但是有很高的方差,因此它的准确性不怎么好。
bagging是早期的集成方法(ensemble method),它可以重复地构建多个决策树基于有放回地重新采样,然后集成这些决策树模型进行投票,从而得到更好地准确性。稍后,我会介绍决策森林算法,它可以比bagging更好地解决决策树overfitting的问题。这些方法虽然会增加一些模型的偏差和丢失一些可解释性,但是它们通常会使模型具有更好地性能。
下面,我用scikit-learn实现bagging来拟合Wine数据集来实战一下bagging方法。这是数据集的介绍:Wine数据集
import pandas as pd
df_wine = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # 数据集中有3个类别,这里我们只用其中的2个类别
y = df_wine['Class label'].values
X = df_wine[['Alcohol', 'Hue']].values # 为了可视化的目的,我们只选择2个特征from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import train_test_split
le = LabelEncoder()
y = le.fit_transform(y) # 把label转换为0和1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40, random_state=1) # 拆分训练集的40%作为测试集from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier(criterion='entropy', max_depth=None)
# 生成500个决策树,详细的参数建议参考官方文档
bag = BaggingClassifier(base_estimator=tree, n_estimators=500, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=1, random_state=1)# 度量单个决策树的准确性
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
# Output:Decision tree train/test accuracies 1.000/0.854# 度量bagging分类器的准确性
bag = bag.fit(X_train, y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train, y_train_pred)
bag_test = accuracy_score(y_test, y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f' % (bag_train, bag_test))
# Output:Bagging train/test accuracies 1.000/0.896
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
从上面的输出我们可以看出,Bagging分类器的效果的确要比单个决策树的效果好。下面,让我们打印出两个分类器的决策边界,看看它们之间有什么不同,代码如下:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2, sharex='col', sharey='row', figsize=(8, 3))for idx, clf, tt in zip([0, 1], [tree, bag], ['Decision Tree', 'Bagging']):clf.fit(X_train, y_train)Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)axarr[idx].contourf(xx, yy, Z, alpha=0.3)axarr[idx].scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], c='blue', marker='^')axarr[idx].scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], c='red', marker='o')axarr[idx].set_title(tt)plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
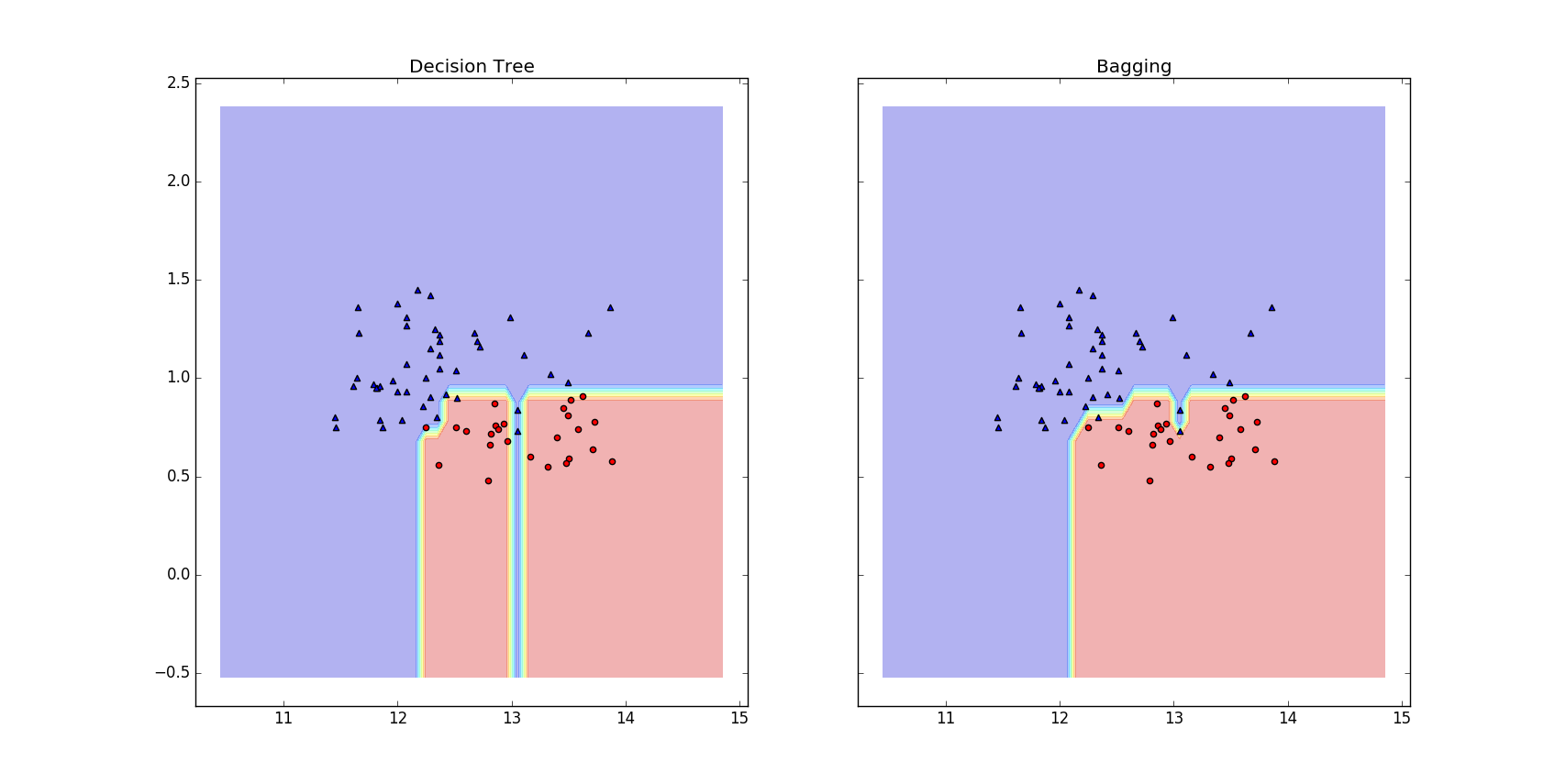
从上图我们可以看出,Bagging分类器的决策边界更加平滑。注意:bagging是不能减小模型的偏差的,因此我们要选择具有低偏差的分类器来集成,例如:没有修剪的决策树。
随机森林(random forests)
随机森林与上面Bagging方法的唯一的区别是,随机森林在生成决策树的时候用随机选择的特征。之所以这么做的原因是,如果训练集中的几个特征对输出的结果有很强的预测性,那么这些特征会被每个决策树所应用,这样会导致树之间具有相关性,这样并不会减小模型的方差。
随机森林通常可以总结为以下4个简单的步骤:
- 从原始训练集中进行bootstrap抽样
- 用步骤1中的bootstrap样本生成决策树
- 随机选择特征子集
- 用上面的特征子集来拆分树的节点
- 重复1和2两个步骤
- 集成所有生成的决策树进行预测
在上面的步骤2中,我们训练单个决策树的时候并没有用全部的特征,我们只用了特征的子集。假设我们全部的特征大小为m,那么m??√个特征子集是一个很好地选择。
随机森林并不像决策树一样有很好地解释性,这是它的一个缺点。但是,随机森林有更好地准确性,同时我们也并不需要修剪随机森林。对于随机森林来说,我们只需要选择一个参数,生成决策树的个数。通常情况下,你决策树的个数越多,性能越好,但是,你的计算开销同时也增大了。
下面,我用随机森林训练上面的Wine数据集。这次我不在只选择数据集的2个特征了,我要用全部的13个特征。而且这次的输出我用了3个类别。代码如下:
import pandas as pd
df_wine = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
y = df_wine['Class label'].values
X = df_wine.values[:, 1:]from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import train_test_split
le = LabelEncoder()
y = le.fit_transform(y) # 把label转换为0和1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40, random_state=1) # 拆分训练集的40%作为测试集from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=1000, criterion='gini', max_features='sqrt', max_depth=None, min_samples_split=2, bootstrap=True, n_jobs=1, random_state=1)
# 度量随机森林的准确性
rf = rf.fit(X_train, y_train)
y_train_pred = rf.predict(X_train)
y_test_pred = rf.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Random Forest train/test accuracies %.3f/%.3f' % (tree_train, tree_test)) # output: Random Forest train/test accuracies 1.000/0.986
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
对于上面RandomForestClassifier类的参数信息,我强烈建议大家去官网查看:RandomForestClassifier类
Boosting
声明:下面的部分内容是我从Bishop模式识别与机器学习(Pattern Recognition and Machine Learning)书中翻译下来的,如果你想对Boosting有一个更深刻的理解,我建议你读书中的14.3节。
Boosting集合多个’base’分类器从而使它的性能比任何单个base分类器都好地多。在这个小节中,我描述一个更广泛使用的boosting算法adaptive boosting(AdaBoost)。即使base分类器的性能比随机猜测稍微好一点(因此base分类器也叫做weak learners),Boosting依旧会得到一个很好地预测结果。Boosting最初的目的是解决分类问题,现在它也可以解决回归问题。
Boosting与Bagging主要的不同是:Boosting的base分类器是按顺序训练的(in sequence),训练每个base分类器时所使用的训练集是加权重的,而训练集中的每个样本的权重系数取决于前一个base分类器的性能。如果前一个base分类器错误分类地样本点,那么这个样本点在下一个base分类器训练时会有一个更大的权重。一旦训练完所有的base分类器,我们组合所有的分类器给出最终的预测结果。过程如下图:
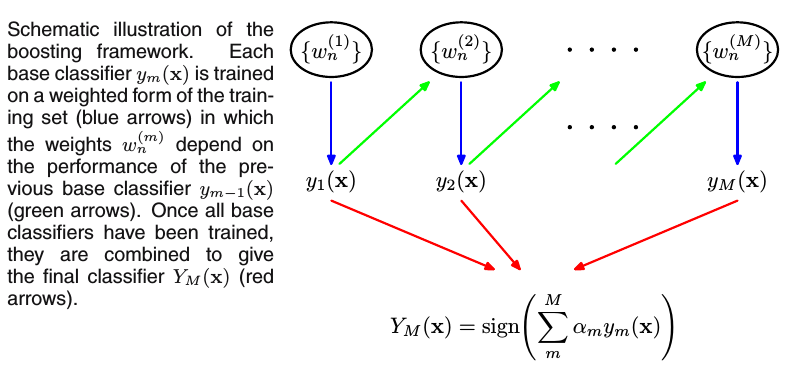
上图中,每个base分类器ym(x)用加权重的训练集来训练(蓝色箭头), 训练集的权重系数w(m)n取决于上个base分类器ym?1(x)(绿色箭头)的性能。一旦所有的base分类器训练完成,结合它们给出最终的分类器YM(x)(红色箭头)。
下面,给出一个两类别的分类问题。输入向量x1,x2,…,xN构成了训练集样本,其对应的目标变量(标签)为t1,t2,…,tN,其中tn∈{ ?1,1}。每个训练样本给一个初始化权重1N.假设我们有一个现成的程序(y(x)∈{ ?1,1})可以用加权的训练集来训练base分类器。 在算法的每次迭代中,AdaBoost用数据集来训练一个新的base分类器,其中所使用训练集的加权系数依据上个base分类器的性能不断作出调整,既错误分类的数据点在下一次分类中被赋予更大地权重系数。最终,所有训练完以后的分类器被分配不同的权重系数。AdaBoost具体的算法如下:
1、初始化数据集的权重系数{
wn},设置w(1)n=1对于n=1,2,…,N
2、For m=1,…,M:
(a) 训练base分类器ym(x)通过最小化加权误差函数:
(b) 计算?m和αm:
(c) 更新样本的权重系数:
3、用最终模型进行预测:
从上面的算法中我们看到了第一个base分类器y1(x)用权重系数(w(1)n)相等的训练样本训练。
假设我们的base分类器为决策桩(decision stumps, 单个节点的决策树),因此,每个base分类器分类一个样本通过这个样本的某个特征是否超过某个阙值,所以,我们的每个分类器所产生的决策边界是一个平行某个坐标轴的线性决策表面,它简单地把样本空间拆分成下图所示的两个区域。
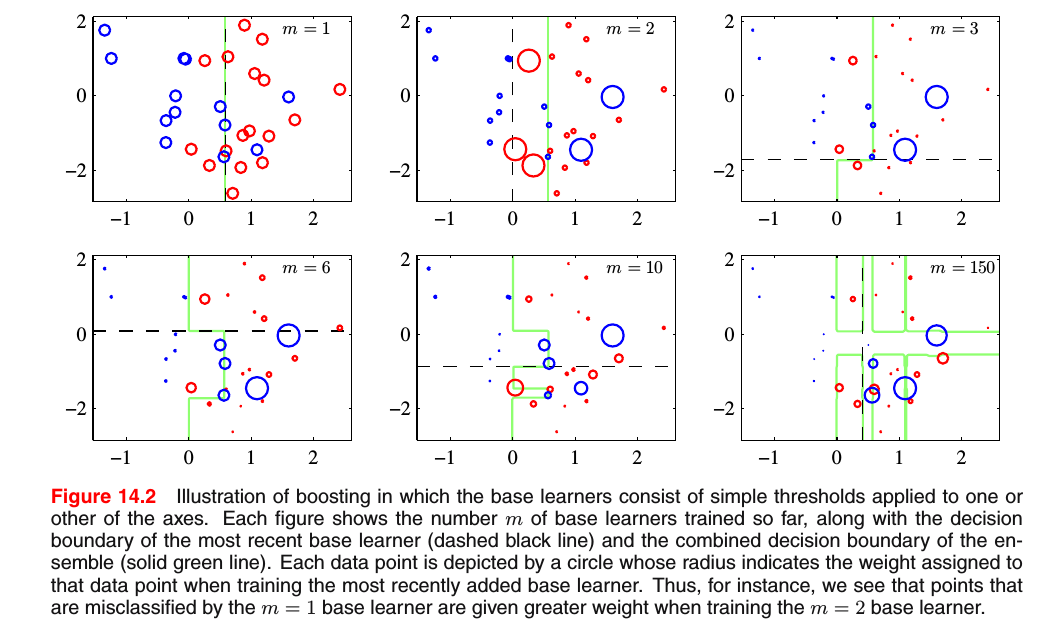
上面每幅图中的m表示了当前要训练的第m个分类器,虚线表示第m个分类器的决策边界,绿线表示所有m个分类器结合以后的决策边界。每个数据点用圆描述,圆半径的大小表示当训练第m个分类器时数据点权重的大小。例如,上面在训练第1个base分类器错误划分的数据点,在训练第2个base分类器时得到了更大的权重系数。
下面,让我们用scikit-learn来训练一下AdaBoost。
from sklearn.ensemble import AdaBoostClassifier# 决策桩分类器性能
tree = DecisionTreeClassifier(criterion='entropy', max_depth=1)
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train, tree_test)) # Decision tree train/test accuracies 0.915/0.896# Boosting分类器性能
ada = AdaBoostClassifier(base_estimator=tree, n_estimators=1000, learning_rate=0.1, random_state=0)
ada = ada.fit(X_train, y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train, y_train_pred)
ada_test = accuracy_score(y_test, y_test_pred)
print('AdaBoost train/test accuracies %.3f/%.3f' % (ada_train, ada_test)) # AdaBoost train/test accuracies 1.000/0.979
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
AdaBoostClassifier类参数的详细信息建议大家去官网查看:AdaBoostClassifier类
总结
上面我提到的这些ensemble方法虽然提高了模型的性能,但是它与单个分类器相比确实增加了很多的计算开销。在实际应用中,应该仔细考虑我们是否想要用计算的代价来换取模型性能的提高。虽然已经证明bagging和boosting比单个分类器有更好的准确性,然而,我们必须考虑在什么情况下和怎么使用这些技术。
当训练集有很小地变化时都会导致预测结果有明显地不同,在这种情况下,Bagging会有很好地效果。Bagging更适合应用到具有很小偏差(small bias)地分类方法中。Bagging减小方差通过平均方法(averaging),如果你的模型具有很高的偏差,Bagging并不会对模型有很大的影响,就好比是一堆臭皮匠平均下来还是臭皮匠。但是,如果你的模型个个都是诸葛亮(都很好地拟合训练集,高方差),那么如果我把这些诸葛亮的决策结果平均下来,会产生很好地效果。
Boosting的原理就好比每个人(weak learners)都是一个比平民(随机猜测)厉害点的人物,我这里有个大问题需要这些人解决一下,Boosting派出第1个人解决了一些问题,但是剩下了一些难题,接着Boosting派出第2个人主要解决第1个人剩下地难题,接着Boosting派出第3个人解决第2个人剩下地难题,依此类推……到最后,Boosting一定可以很好地解决问题。从上面地例子中,我们也看出了每个人有很高地偏差(更适合解决某一部分问题,也就是不能很好地拟合训练集),但是,Boosting通过上面的手段不仅平均了大家的智慧而且还减小了某个人偏差的问题。
对于稳定的模型来说,Bagging并不会工作地很好,而Boosting可得会有帮助。如果在训练集上有noisy数据,Boosting会很快地过拟合,降低模型的性能,而Bagging不存在这样地问题。
一句话总结:在实际应用中,Bagging通常都会有帮助,而Boosting是一把利剑,用好的情况下肯定会比Bagging出色,但是用不好很可能会伤到自己。