信息
西北工业大学,计算机科学学院一篇博士发表论文,19年2月出版。
摘要:
虽然交通标志检测已经研究多年,并且随着深度学习技术的兴起已经取得了很大进展,但仍有许多问题有待解决。对于复杂的现实世界交通场景,存在两个主要挑战。首先,交通标志通常是小型物体,这使得它们比大型物体更难以发现; 第二,在没有上下文信息的情况下,难以区分复杂街道场景中类似真实交通标志的虚假目标。为了解决这些问题,我们提出了一种新颖的端到端深度学习方法,用于复杂环境中的交通标志检测。我们的贡献如下:1)我们提出了一种多分辨率特征融合网络架构,该架构利用具有跳过连接的密集连接的反卷积层,并且可以为小尺寸物体学习更有效的特征; 2)我们将交通标志检测构建为空间序列分类和回归任务,并提出垂直空间序列注意模块以获得更多的上下文信息以获得更好的检测性能。为了全面评估所提出的方法,我们对几个交通标志数据集以及一般目标检测数据集进行了实验,结果表明了我们提出的方法的有效性。
亟待解决问题
- 交通标志通常图像占比小于1%。
- 存在大量干扰性的其他标志。
贡献:
- 提出一种多分辨率融合的单阶段检测方法。通过密集连接的反卷积层和跳跃连接获取多分辨率特征映射,提高小目标检测能力。
- 将交通标志检测与识别任务是为区域序列的分类与回归问题。通过注意机制建模可以更好联系上下文,减小其他标志的干扰。
策略:
1.为了提高模型的尺度不变性,需将训练数据预处理为多种不同尺度图像。
技术现状:
- 基于颜色和形状
- 基于颜色分割交通标志,包括亮度,色度和色调。
- 基于形状分割交通标志,三角形,矩形和箭头符号检测。
上述方法通常用于检测任务的前处理或后处理阶段。
- 基于机器学习
- Harr-Like分类检测器
- 聚合通道特征(ACF)检测器。
上述方法对于存在遮挡的复杂场景表现效果不佳。
- 基于深度学习
- 基于区域建议,如RCNN流派。
- 基于单阶段,overfeat将对象分类网络与检测任务相结合,DenseBox用反卷积层放大特征图,YOLO和SSD是实时检测器。
基于单阶段的方法更有希望用于自动驾驶的实时任务,单精度相对较差。
- 小目标检测
- MS-CNN 多尺度检测
- 影响因素:图像分辨率,上下文推理,尺度不变形。
- DSSD:反卷积层放大特征图分辨率。
- 空间上下文
- 文献:“Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks”提出RNN编码不同方向上下文。
- 文献:“Spatial memory for context reasoning in object detection”提出空间存储器编码对象。
本文框架
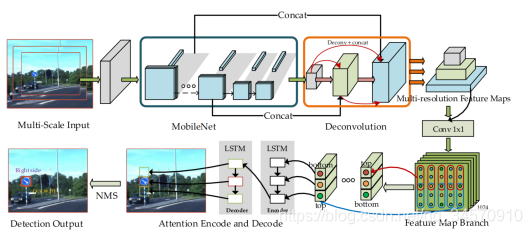
神经网络的浅层的保留图像对象位置信息;深层网络提高检测性能。
分为两个过程:
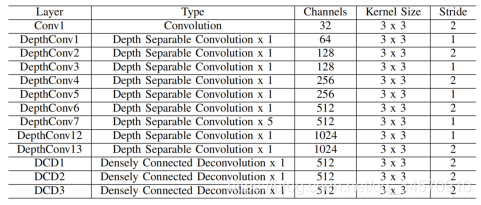
- Multi-Resolution Conv-Deconv Network:在MobilNet基础上提出密集连接的多分辨率反卷积层,来放大特征,同时获得更高级语义信息。(优势即提取了更深层的语义信息,同时融合了低级与高级层增加细节检测)。结构是将mobilenet最后一层stride改为2并添加了三层密集反卷积:
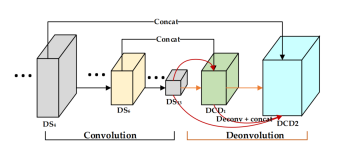
DC4和DC6层用于构建多分辨率conv-deconv模块,保证计算成本的同时,减小梯度消失的问题。
![]()
![]()
垂直空间序列注意模型(Vertical Spatial Sequence Attention Model):充分利用图像上下文信息,下图为VSSA模块。 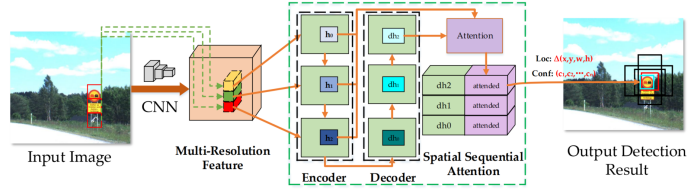
使用 LSTM将编码点进行特征映射,其上下文信息表示为 (h1, h2, ..., hT ):
![]()
另一个LSTM用于注意力解码,解码的隐藏状态为(dh1, ..., dhT ):
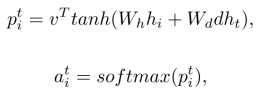
![]() 表示第t个步骤生成的权重矢量;v,Wh,Wd是模型可学习参数。
表示第t个步骤生成的权重矢量;v,Wh,Wd是模型可学习参数。
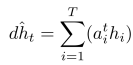
最后连接所有dht预测类别y与边界框d.
- 训练过程
Loss:
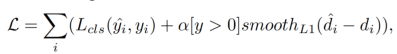
Alpha设为0.1
- 实验
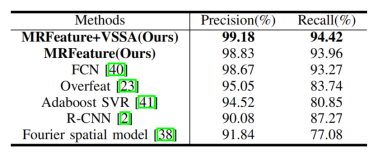
STS(瑞典交通标志)数据集的性能比较。

证明垂直空间比水平空间检测效果好。

Voc数据集比较