练习题:grep、sed、awk练习题 - myfu - 博客园
一、grep
格式;:grep [OPTIONS] PATTERN [FILE...]
常用的正则表达通配符
^ 起始文本 '^love' 匹配所有以love开头的行
$ 结束文本 'love$' 匹配所有以love结束的行
. 匹配一个字符 'l..e' 匹配包含一个 l, 接着两个字符, 最后一个 e 的行
* 匹配零或者多个之前的字符 ' *love' 匹配零或多个空格, 后面接着字符串love(注:*前有一个空格)
[ ] 匹配一个字符在字符集中 '[Ll]ove' 匹配包含 love 或者 Love的行
[^] 匹配一个字符不在字符集中 '[^A–K]ove' 匹配行:其中一个字符不在A-K间,接着字符串ove
\< 起始单词 '\<love' 匹配以love单词开头的行,即某个单词开头包含love
\> 起始单词 'love\>' 匹配以love单词结尾的行,即某个单词结尾包含love
x\{m\} 重复字符x:m次; 'o\{5\}' 匹配重复o 5次的行
x\{m,\} 重复字符x:至少m次;'o\{5,\}' 匹配重复o 至少5次的行
x\{m,n\} 重复字符x:m-n次; 'o\{5,10\}' 匹配重复o 5-10次的行
?grep 'NW' 123.txt 匹配包含NW的行grep 'NW' 12* 匹配以12开头的所有文件的行grep '^n' 123.txt 匹配以n开头的行grep '3$' 123.txt 匹配以3结尾的行grep '5\..' 123.txt 匹配包含5.x的行,其中x为任意单字符grep '^[we]' 123.txt 匹配包含w或e的行grep '[A-Z][A-Z] A' 123.txt 匹配包含2个字母一个空格一个A的行grep 'er* ' 123.txt 匹配包含1个e紧接着至少0个r的行grep '[a-z]\{9\}' 123.txt 匹配包含9个连续小写字母的行grep '\<north' 123.txt 匹配起始包含north单词的行grep 'north\>' 123.txt 匹配结尾包含north单词的行grep “^[[:space :]]*$” 匹配任意一个空格grep '^ *$' file.txt 匹配空白行grep -A 2 "oldboy" grep.sh oldboy这行及下两行grep -B 2 "oldboy" grep.sh oldboy这行及上两行grep -C 2 "oldboy" grep.sh oldboy这行及上下两行
?or操作
grep -e 'Tech' -e 'Sales' employee.txt

and操作
grep Manager employee.txt | grep Sales
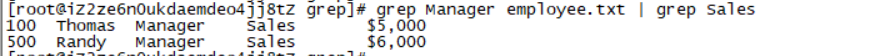
not 操作
grep -v Manager employee.txt #找到不含Manager的行
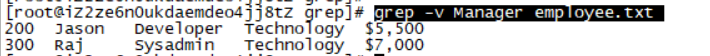
二、awk
-F指定分隔符,$1 指指定分隔符后,第一个字段
awk -F "N" '{print $1}' 123.txt 不使用-F的话默认使用空格分割
awk -F "2" '{print $1 $2}' awk.txt $1与$3相连输出,不分隔
awk -F "3" '{print $1,$2}' awk.txt 多了一个逗号,$1与$2使用空格分隔
awk -F "3" '{print "id:"$1, "id2:"$2}' awk.txt 自定义输出
awk -F "5" '{print NF}' awk.txt 显示每行有多少字段
awk -F "5" '{print $NF}' awk.txt 将每行第最后一个字段的值打印出来
awk -F 5 'NF==2{print}' awk.txt 显示只有2个字段的行
awk -F 5 'NF>1{print}' awk.txt 显示大于1个字段的行
awk '{print NR,$0}' awk.txt 输出每行内容并且带有行号
awk -F "2" '{print NR,NF,$NF,"\t",$0}' awk.txt 依次打印行号,字段数,最后字段值,制表符,每行内容
awk -F "[:S ]" 指定多个分隔符
awk 'NR==2{print}' awk.txt 打印第二行的内容
awk 'NR==2||NR==1{print}' awk.txt 打印第二行和第一行的内容
awk 'NR!=2{print}' awk.txt 打印不是第二行的内容
awk 'NR>1{print}' awk.txt 去掉第一行的内容
awk 'END{print}' 打印最后一行
//匹配代码块
awk '/8/' awk.txt 输出包含8的行
awk '/8/{print}' awk.txt 输出包含8的行
awk '/8/{print $0}' awk.txt 输出包含8的行
awk '!/8/' awk.txt 输出不包含8的行
awk '/^ *$/' awk.txt 输出空白行且空白行包含空格,“^”和“*”之间带有空格
awk '/678|ee/' awk.txt 输出包含678或ee的行
awk -F2 '$1~/1/{print $1}' awk.txt 以2分隔,分隔打印$1=1的内容 “~”表示包含
awk -F2 '$1!~/1/{print $1}' awk.txt
awk '/1/,/2/' awk.txt 表示每行包含1-2的内容
awk -F ' :' '/^D/{print $1}' 输出第一列以D开头的内容
awk -F ":" '/^[C,E]/{print $1}' 输出第一列以C或者E开头的内容
IF语句
必须用在{}中,且比较内容用()扩起来
awk -F3'{if($1~/1/)print $1}' awk.txt 如果$1包含1,就打印出来
awk -F3 '{if($1~/3/){print $1} else{print$2}}' awk.txt
条件表达式
表达式:==,<=,>=,!=,<,>
awk -F2 '$1=="1"{print $2}' awk.txt 如果$1=1,就打印出来$2
逻辑运算符
与:&&,或者||
awk -F3 '$1==12 && $2~/three/{print $2}' awk.txt 如果$1等于12且$2包含three,打印$2
awk -F3 '$1 || 12 && $2~/three/{print $2}' awk.txt 如果$1等于12或$2包含three,打印$2
输出分隔符OFS
awk -F3 '{print $1,$2}' OFS="\t" awk.txt 输出$1,$2,并且以制表符间隔
RS以某个字符为分割后换行
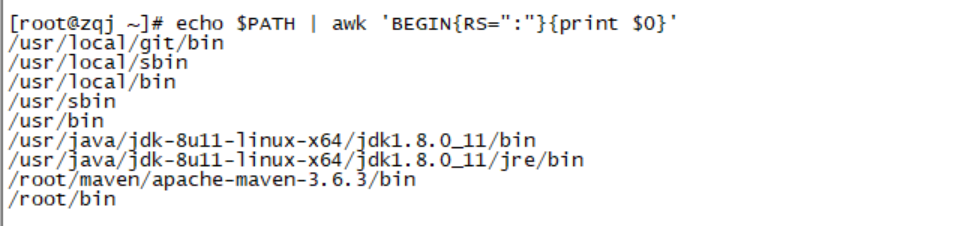
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' #表示以“:”分割后换行
格式化输出
pritnf表示格式化输出
netstat -anp|awk '{printf "%-8s %-8s %-10s\n",$1,$2,$3}'
%格式化输出分隔符
-8长度为8个字符
s表示字符串类型
awk -F '3' 'BEGIN{A=0;B=0}{if($1==1}{A++;print "big"} else {B++;print "small"}} END{print A,'\t',B}' awk.txt 以3为分隔,设置A,B两个变量,分隔后判断$1是否等于1,是的话A+1,否则B+1,并且打印对应的字符,最后输出A,B的值
top -b -n 2 -d 1|grep 11916|awk BEGIN'{print "cpu"," mem",OFS="\t"}{print $9,$10;c+=$9;m+=$10}END{print "----";print "CountCpu CountMem";print c/NR,m/NR}'

排序,去重
cat catalina.out |grep "xxxxx"|awk -F ']' '{print $2}'|sort 排序
cat catalina.out |grep "xxxxx"|awk -F ']' '{print $2}'|uniq 去重
三、sed
sed [-nefri] [动作]
-n :使用安静(slient)模式。只有经过sed特殊处理的那一行(或者操作)才会被列出来。一般与p配合使用
-e :直接在命令行模式上进行sed的动作编辑
-f :直接将sed动作写在一个文件内,-f filename则可以执行filename 内的sed动作。
-r :sed的动作支持的是拓展正则表达式的语法(默认是基础正则表达式的语法)
-i :直接修改读取的文件内容,而不是由屏幕输出
[动作]有下面这些参数:
a :新增
d :删除 (比较重要,测试工作中对数据处理时可快速去除无用信息,比如注释行,空白行等)
i :插入
p :打印 (一般与-n配合使用)
s :替换(重中之重!!!,s参数可以说是日常测试工作中对数据用sed清理过滤时使用率最高的了)

sed 修改表达式: sed 's/待修改/修改结果/' #这种方式不会修改源文件内容,“/”也可以使用其他字符,起到分割即可
如果想要修改源文件就需要借助 -i 命令,另外为了防止误操作修改文件,一般可以采取这种写法: sed -i.bak 's/hello/HELLO/' text.txt ,这种写法在修改源文件的同时还会生成一份以.bak结尾的备份文件,相较安全。
-e能可以使得命令可以直接连续编辑,
sed -i -e 's/:/@/g' hello.txt -i -e 's/a/A/' hello.txt
sed -i "s#.*Jose.*#JOSE HAS RETIRED#g" file #替换掉包含Jose的行
sed -i "s#^Fred#***Fred#g" file #把三个星号(***)添加到以Fred开头的行
sed -i '/Savage/d' grep.sh 删除包含Savage的行
sed -n '3,10p' hello.txt 打印3-10行的内容
sed -i '/^ *$/d' grep.sh # 删除所有空白行且空白行包含空格
四、cut
$ cut -c 字符区间
$ cut -d “分隔字符” -f fields
cut -c 4- test.txt 显示每行第四个字符之后的内容
说明:4- 表示从第4个字符开始 , 4-10 表示从第4个字符到第10个字符 , -4 表示截取前4个字符
cut -d ' ' -f 2 test.txt 以“空白字符”作为分隔符,显示第二列内容
五、sort
$ sort [-nrtk] [file]
| 参数 |
说明 |
| -n |
纯数字进行排序,默认是以文字形态来进行排序的 |
| -r |
反向排序 |
| -t |
分隔符,默认是以tab键来分隔 |
| -k |
以那个区间来进行排序 |
-h 以计算机的大小排序
sort -t ' ' -k 2 test.txt 以空白字符作为分隔符,将第二列内容进行升序排列
sort -t ' ' -k 3 -nr test.txt 以空白字符作为分隔符,将第三列内容进行降序排列
说明:# 年龄字段是数字类型,所以需要加参数n # 默认sort是升序排列,加参数r实现降序排列
六、uniq
$ uniq [-icu]
| 参数 |
说明 |
| -i |
忽略大小写字符的不同 |
| -c |
文本行出现的次数 |
| -u |
只显示不重复的行 |
-f 针对第几列进行比较,默认使用空格分割
sort test.txt |uniq 去除姓名重复的数据结合sort排序和uniq去重(去重的前提是要重复的数据相邻)
sort test.txt |uniq -c 统计每行出现的次数
sort test.txt |uniq -u 显示不重复的行
七、wc
统计文件里面有多少行,多少单词,多少字符
$ wc [-lwm]
统计文件里面有多少行,多少单词,多少字符
$ wc [-lwm]
| 参数 |
说明 |
| -l |
仅列出行数 |
| -w |
仅列出多少字(英文单词) |
| -m |
多少字符 |
wc -l test.txt 打印统计行数
wc -c test.txt 打印统计的英文单词的个数
wc -m test.txt 打印字符个数
八、while
1、死循环
while true
do
命令序列
done
2、当n小于10时输出n的值
!/bin/bash
n=1
while [ $n -lt 10 ]
do
echo "$n"
n=$[$n+1]
done