Large Kernel Matters����Improve Semantic Segmentation by Global Convolutional Network
���ĵ�ַ��https://arxiv.org/pdf/1703.02719.pdf
���Ĵ��µ㣺
1�����GCN����ṹ��Ȩ�ⶨλ�����֮��ľ���ì��
2������߽羫ϸ��ģ��Boundary Refinement block���������ָ�ǰ������߽�Ķ�λ����
Abstract
One of recent trends in network architec- ture design is stacking small filters (e.g., 1x1 or 3x3) in the entire network because the stacked small filters is more efficient than a large kernel, given the same computational complexity. However, in the field of semantic segmentation, where we need to perform dense perpixel prediction, we find that the large kernel (and effective receptive field) plays an important role when we have to perform the classification and localization tasks simultaneously. Following our design principle, we propose a Global Convolutional Network to address both the classification and localization issues for the semantic segmentation. We also suggest a residual-based boundary refinement to further refine the object boundaries. Our approach achieves state-of-art performance on two public benchmarks and significantly outperforms previous results, 82.2% (vs 80.2%) on PASCAL VOC 2012 dataset and 76.9% (vs 71.8%) on Cityscapes dataset.
ժҪ�Ƚ���Ҫ��ԭ��ճ�������ˣ�����ǿ���˾�����С�ͻ������ƣ����Ǵ�ľ������ṩ����Ľ����������GCN��ȫ�־������磬��������ڲв�ı߽�refineȥ�õ����õķָ�߽硣
�����ܽ�
���½�����ָ��Ϊһ�������ط�������������˸������������ս�����ࡢ��λ
�����أ�����Ͷ�λ��������natrually contradictory�ģ�����������Ҫת���IJ����ԣ�����ƽ�ƺ���ת��������λ������Ҫ��ת����������
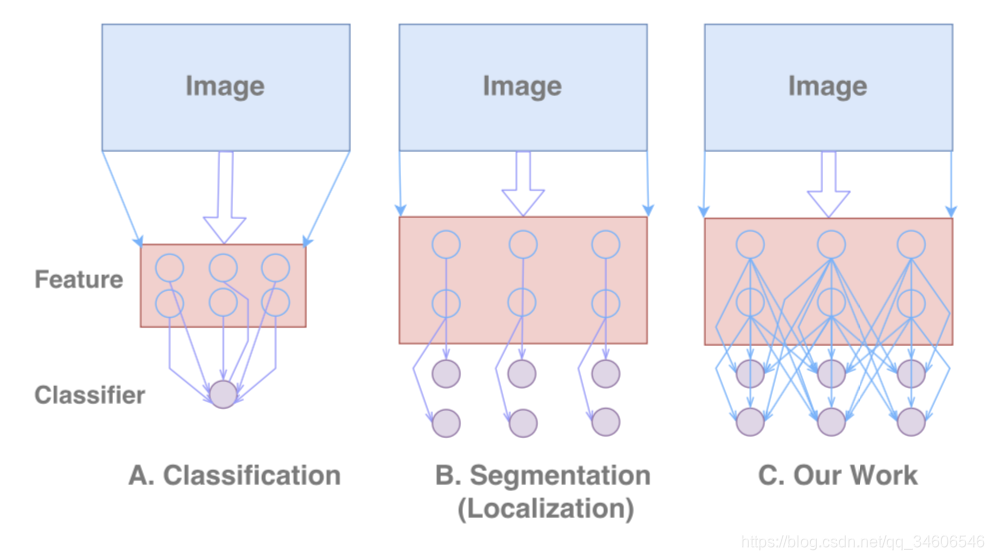
��ͼ�Ľ��ͣ���Feature���ʾ��ȡ������ͼ��classifier��ʾ������������������һ��������������ͼ���棬�ָ�������aligned classifier��Our Work�����ߵ���ϡ���
A.Classification����ṹ
���͵���imagenet�����о���ķ���������ȡ������AlexNet��VGG Net �� GoogleNet ��ResNet���νṹ���硣ͨ����Ӧ���������������ȡ��β���ķ�������ȫ�ֳػ�����ȡ�����������ܼ����ӡ���ʹ������Ծֲ��Ŷ��͵ͽ���������³���ԣ��ܹ�������ͬ���͵�����ת����
B.Localization��λ�ṹ
����ͬ����������Ҫ�������ͼ��������������ж�����������ȡ�����õ�С������ͼ�����������ͼ��Ŀ���Ƕ�λ������Ҫ�������Ŀռ�λ����Ϣ����Ҳ�ͽ����˴��ָ�������FCN��DeepLab��Deconv-Net���������Ͱװ�ṹ�C��������Ŀռ���Ϣ��Ŀǰͨ��ʹ�õ�������չ����ͼ�ķ����У�1��Deconvolution��2��Unpooling��3��Dilated-Convolution�����Ҳ�ͬ�ڷ������磬������������ͼ�ܼ����ӣ����������������ͼ�Ǿֲ����ӵģ���Ϊ����ͼ�Ƚϴ�ʵ�������صķ��ࡣ
C.Our Work��������Ľṹ
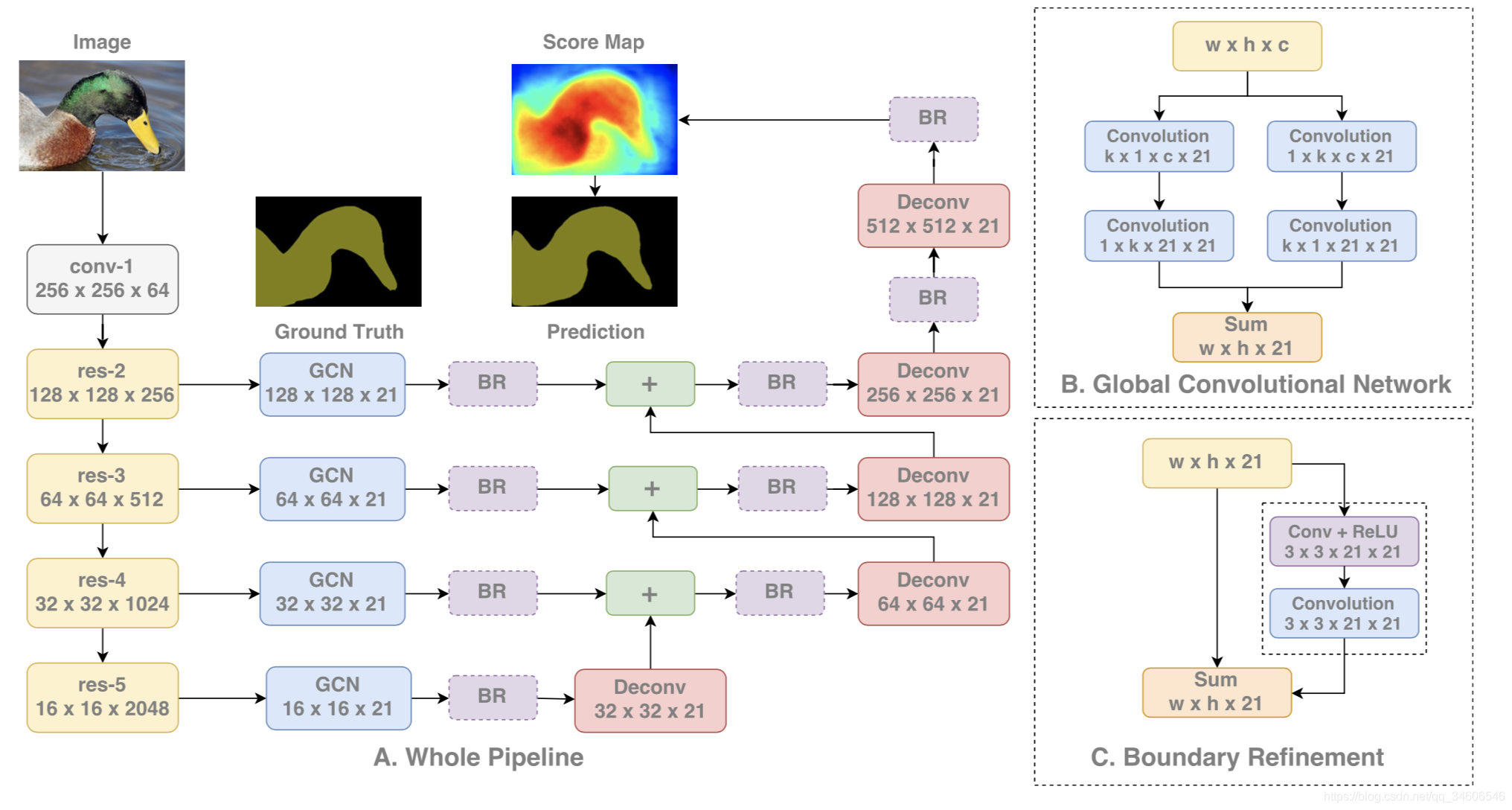
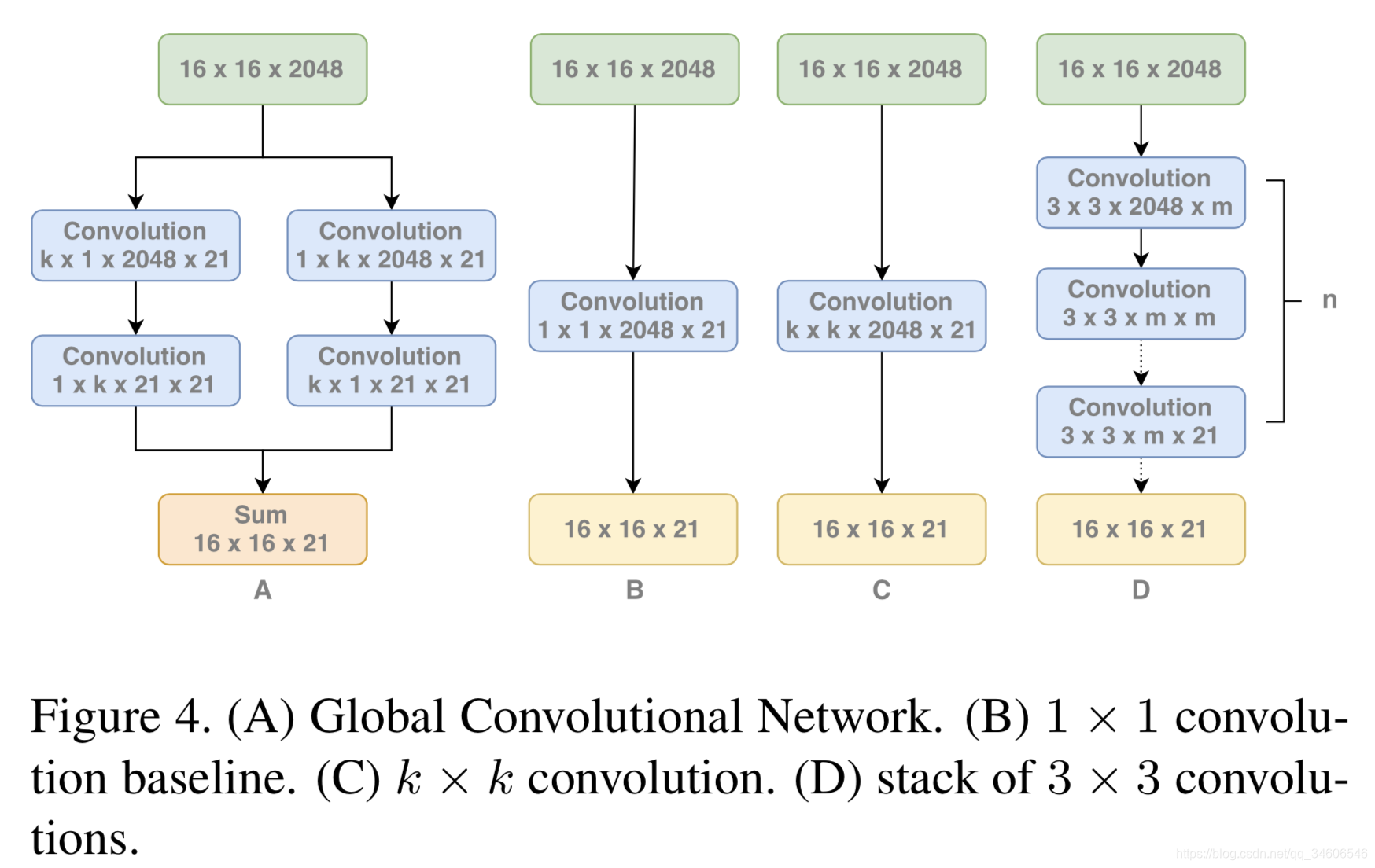
�������GCN�ṹ���������ԭ��
1����λ�Ƕȣ�ʹ��ȫ�������ֶ�λ��Ϣ����ʹ��ȫ���Ӻ�ȫ�ֳػ��ṹ����Ϊ�����ֽṹ�ᶪʧ��һЩλ����Ϣ����λ�Ƕ�ȱʧ�˷������ת���߶������IJ����ԣ������ᵽ����Ч������VRF��������ij߶ȸı�ʱ����Ч��������֮�ı��ˣ�����GCN��������Ч�������㹻���ܰ�ΧĿ�����壬����ͼ��

2������Ƕȣ���ߴ�ľ����ˣ������öԳƵĶ�����������ɴ�size�ľ����ˣ���С�˴����IJ�����kxk -> kx1+1xk)������û�з����Բ�����
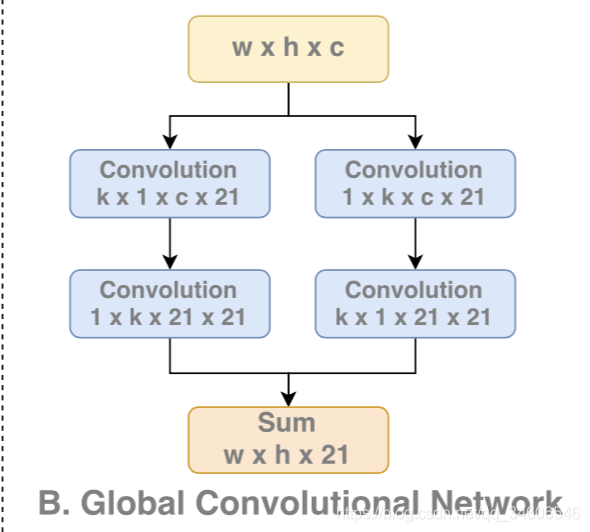
��Ҫע�����������ж�ԭ����the kernel size of the convolutional
structure should be as large as possible.������size�����ܵĴ�Ϊʲô�أ�����Ϊ����Ϊ�Ӷ�λ�Ƕȳ���ȡ����ȫ���ӽṹ������Ҫά�ַ������ܼ���Ҫȫ���ӵ����ԣ�������һ�������ܴ�ľ���size��ȡ��ȫ���ӽṹ��������ʵһ����feature map�Ŀ�����ͬ��kernel size���о���������ʵ����ȫ���Ӽ��㡣
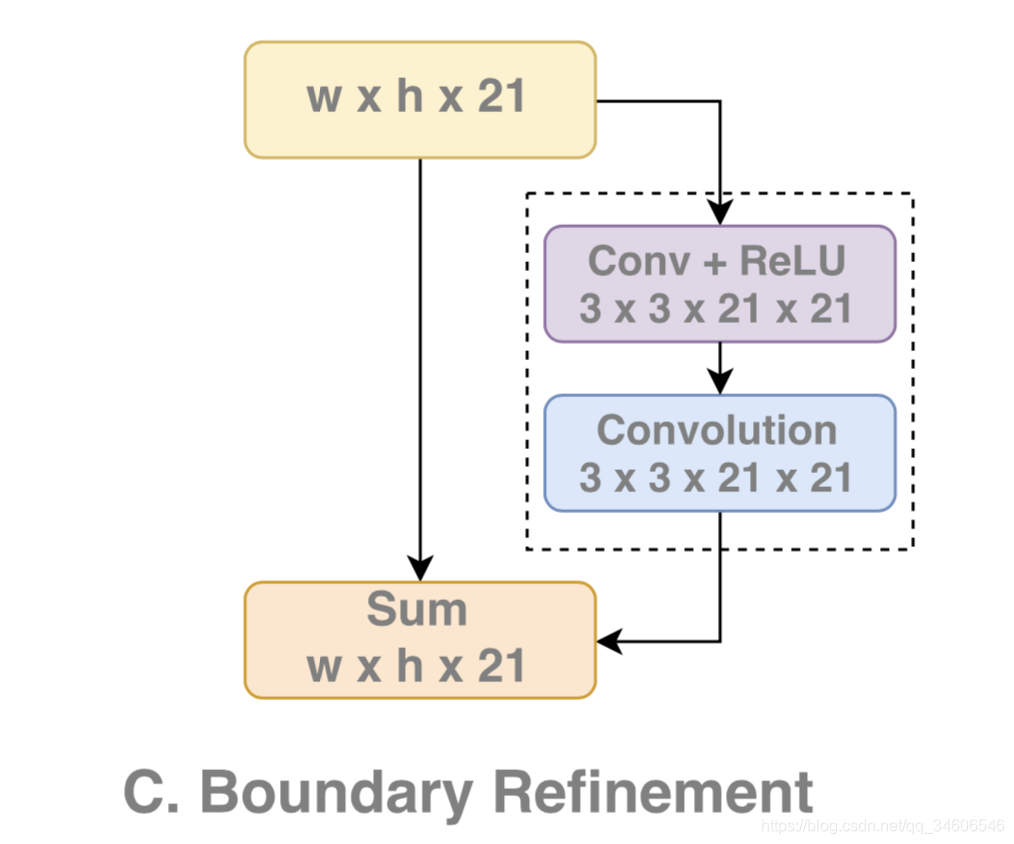
3����BRģ��
�������BRģ��ʹ�߽紦�Ķ�λ�������������������һ���в�ṹ�����б�Ե��refinement��

����ͨ������ʵ�飨Ablation Experiments���Ա��˾�����size��ʵ��Ч����Ӱ�죬ͬʱҲ�Ƚ�������ʵ��kxk�����˵Ľṹ��

��ȷ����k�����ӣ�scoreԽ��Խ���ˣ�����ԭ���������ΪGCN�ṹ�����ĺô�����ֻ����Ϊk�����Ӵ����˸���IJ��������Ա�ʾ������ǿ���µ��أ������ֽ������µıȶ�ʵ��
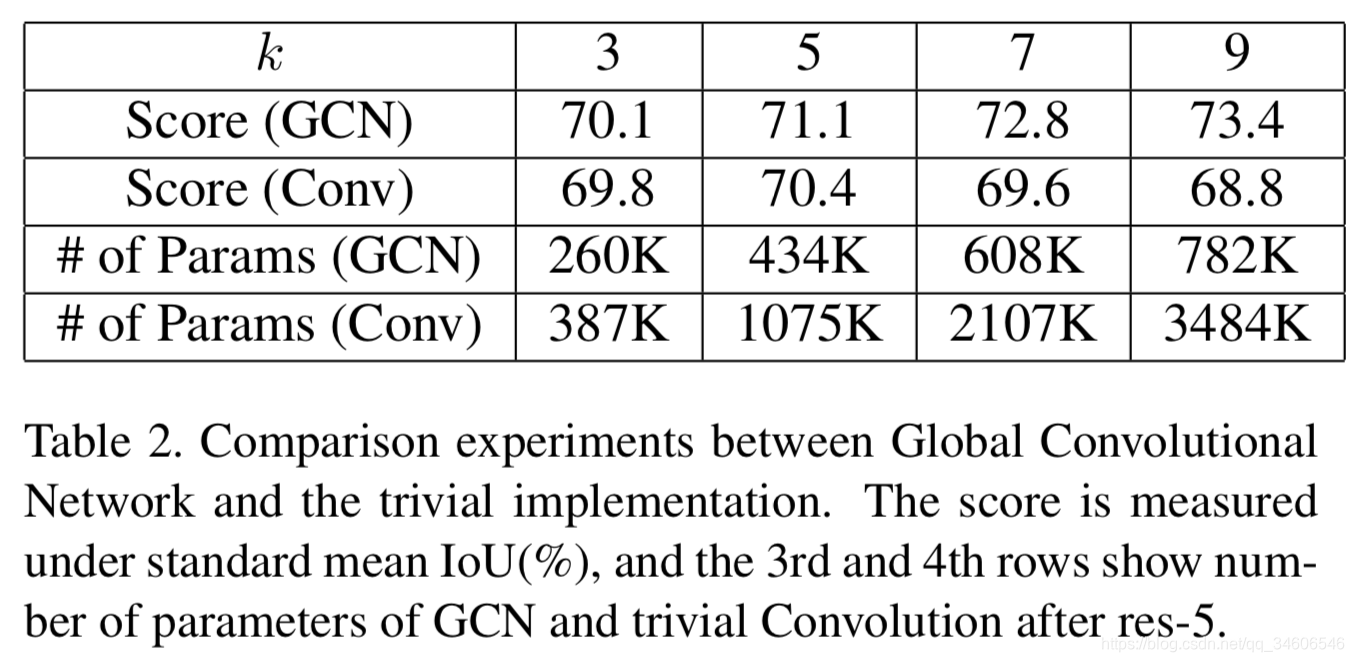
���ԵIJ������¹���ϣ���k��5�C>7ʱconv�IJ������ӵ���IoU�½��ˡ������Ƕ��С�������뵥������˵ĶԱ�

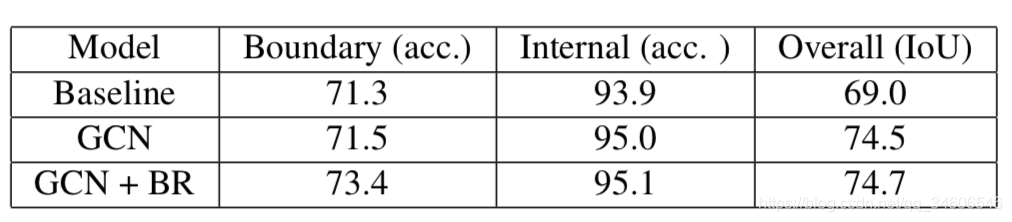
����һ����Ҫ��ʵ��Ա��ǽ�����ͼ��Ϊ�������߽����������ڲ�����Ϊ���DZȽ�GCN�ṹ���ܼ����Ӷ���һ�����и�ǿ�ĸĽ�Ч����ͬʱҲ�ȶ���BRģ��Ա߽�ָ�Ч������Ҳ������Ϊʲô��������GCNʱ�ڲ��ն�С�˺ܶ࣬���Ƕ�С�߶ȵ����壬�ָ�߽�����Ч����BiseNet���Dz���һЩ�ġ�
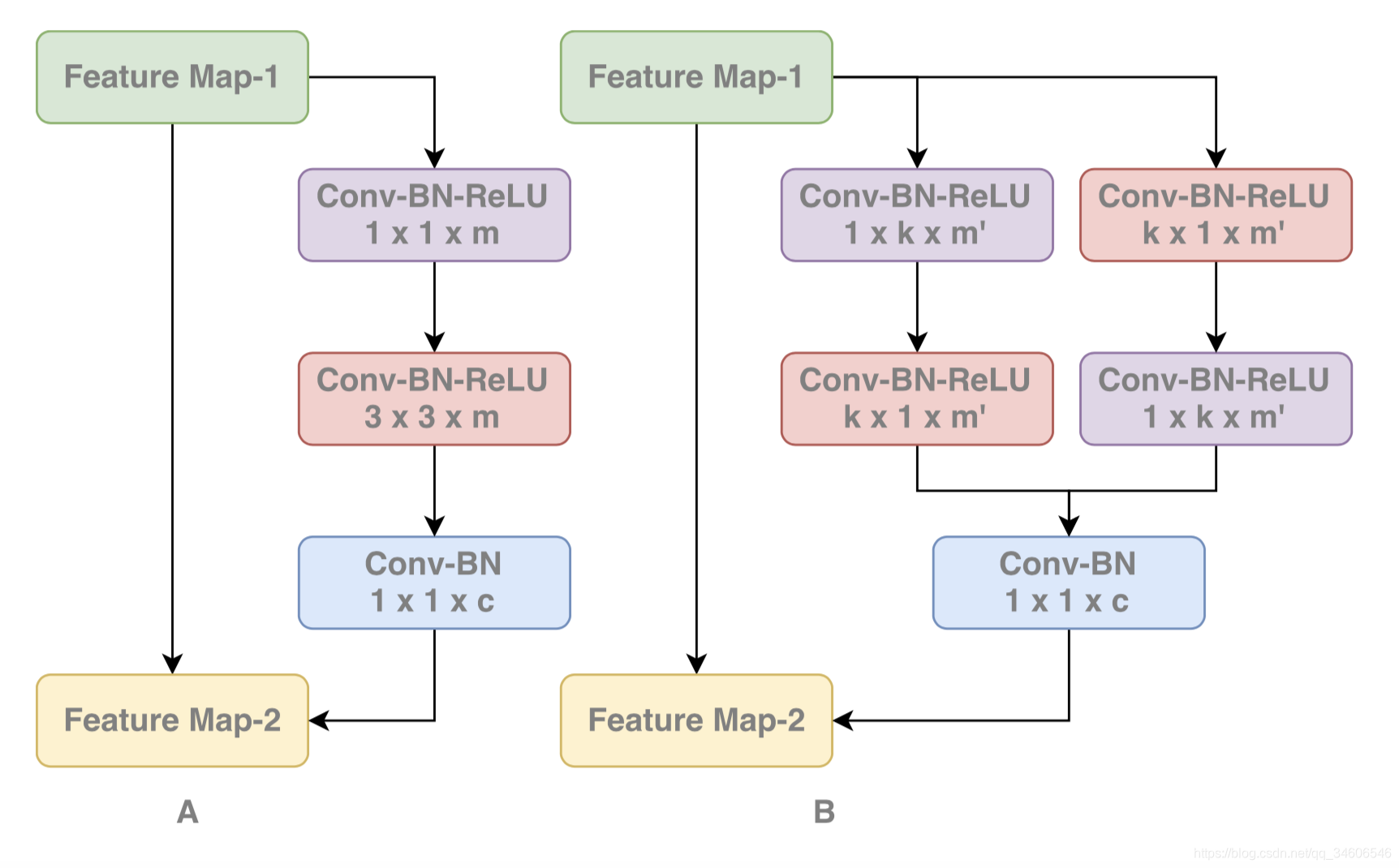
��Ȼ��size �ľ������Ѿ�����֤������Ҫ�����ã���ô�ɴ�backbone��ľ���Ҳֱ����GCN���ˣ����������������ResNet-GCN�ṹ��
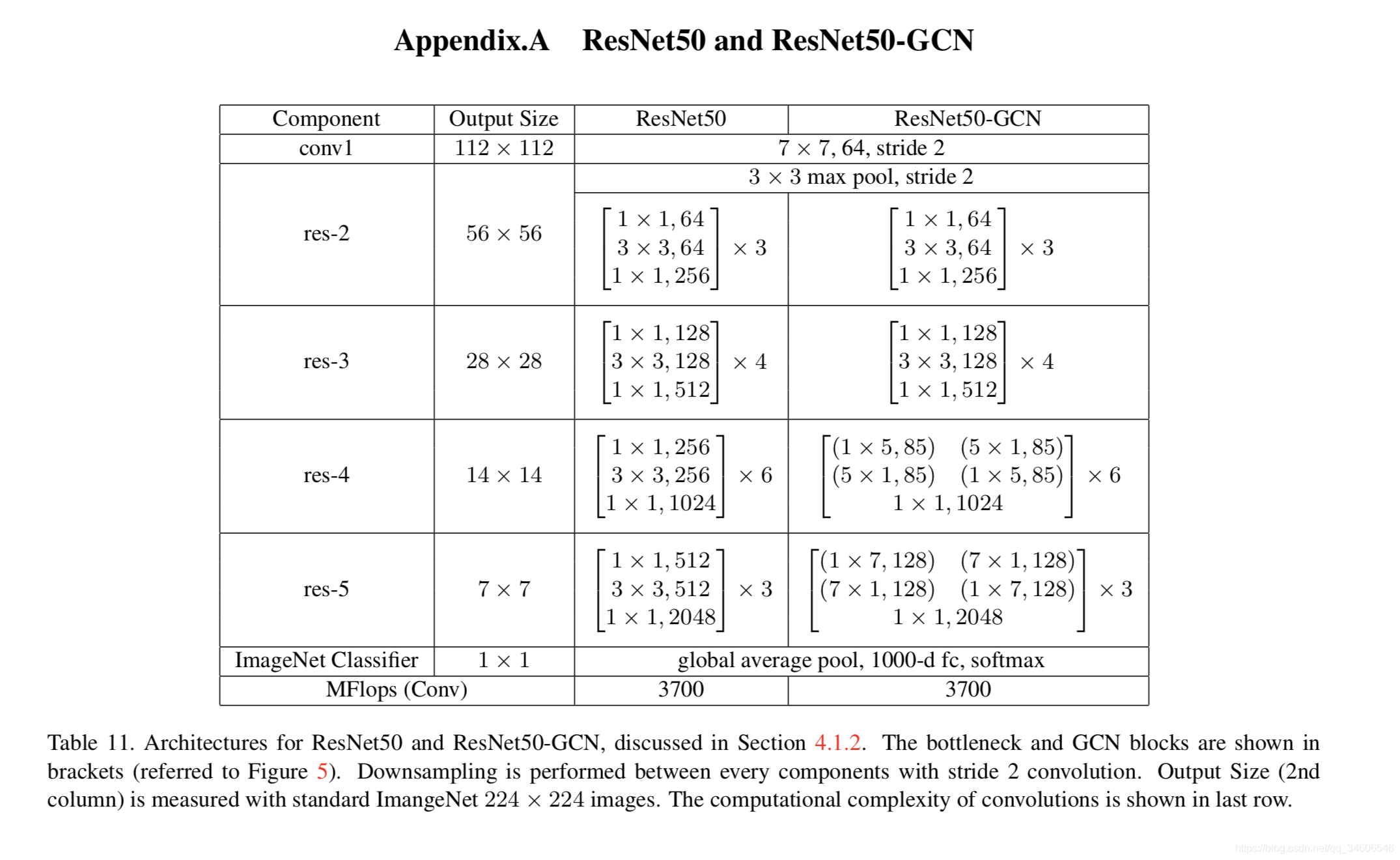
��ImageNet2015����Ԥѵ����PASCAL VOC2012����ʵ��Աȣ�
��ͬ�αȶԣ�Ч����GCN+BR > GCN > Baseline�����Ҽ�CRFЧ�����ã���Ϊ�߽紦����ȷʵ�������⡣
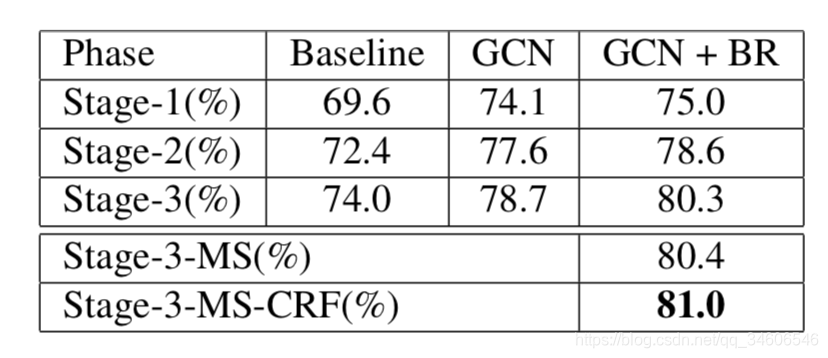
��state-of-the-arts�ıȶԣ�
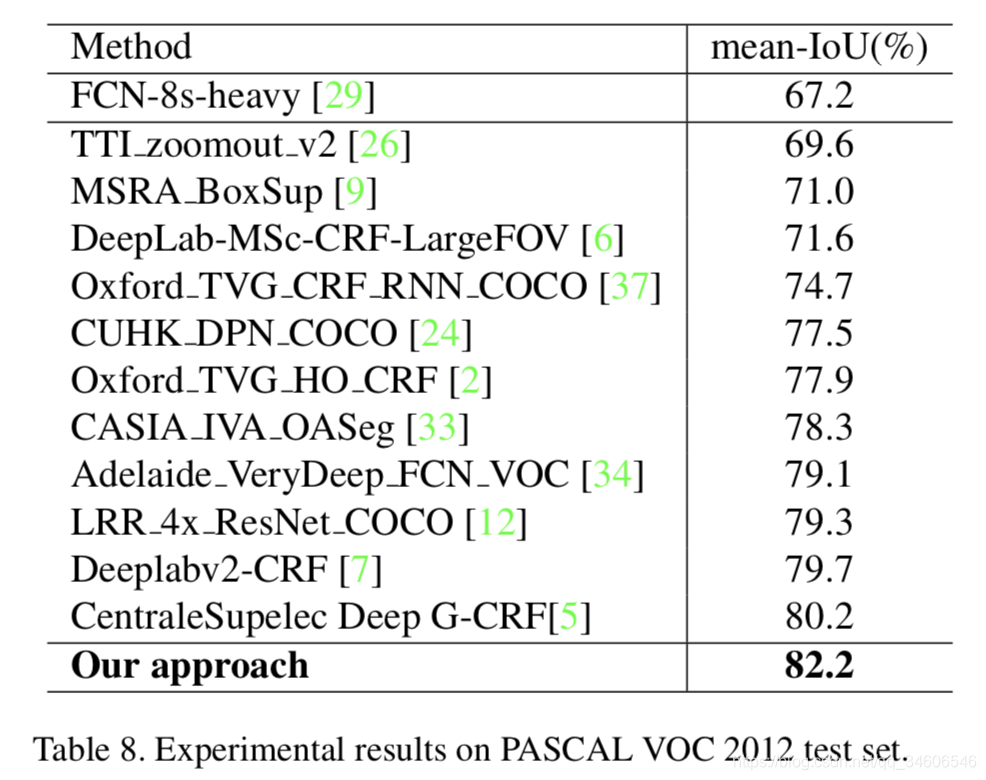
�������Cityscapes���ݼ��ϵ�ʵ��Ч����

�����һ���ܰ���github��ַ�������зdz���ķָ������pytorchʵ�֣�ѧϰpytorch��ʱ�����������
https://github.com/zijundeng/pytorch-semantic-segmentation
��ƪ������Ҳ�Ƚ���ϸ��ΪGCN��pytorch����������ע��
https://blog.csdn.net/u011974639/article/details/78897066
GCN:
# many are borrowed from https://github.com/ycszen/pytorch-ss/blob/master/gcn.py
class _GlobalConvModule(nn.Module):def __init__(self, in_dim, out_dim, kernel_size):super(_GlobalConvModule, self).__init__()pad0 = (kernel_size[0] - 1) / 2pad1 = (kernel_size[1] - 1) / 2# kernel size had better be odd number so as to avoid alignment errorsuper(_GlobalConvModule, self).__init__()self.conv_l1 = nn.Conv2d(in_dim, out_dim, kernel_size=(kernel_size[0], 1),padding=(pad0, 0)) # ��kx1����self.conv_l2 = nn.Conv2d(out_dim, out_dim, kernel_size=(1, kernel_size[1]),padding=(0, pad1)) # ��1xk����self.conv_r1 = nn.Conv2d(in_dim, out_dim, kernel_size=(1, kernel_size[1]),padding=(0, pad1)) # ��1xk����self.conv_r2 = nn.Conv2d(out_dim, out_dim, kernel_size=(kernel_size[0], 1),padding=(pad0, 0)) # ��kx1����def forward(self, x):x_l = self.conv_l1(x)x_l = self.conv_l2(x_l)x_r = self.conv_r1(x)x_r = self.conv_r2(x_r)x = x_l + x_r # sum����return xBR:
class _BoundaryRefineModule(nn.Module):def __init__(self, dim):super(_BoundaryRefineModule, self).__init__()self.relu = nn.ReLU(inplace=True)self.conv1 = nn.Conv2d(dim, dim, kernel_size=3, padding=1) # ��֧3x3����self.conv2 = nn.Conv2d(dim, dim, kernel_size=3, padding=1) # ��֧3x3����def forward(self, x):residual = self.conv1(x)residual = self.relu(residual) # Conv + ReLUresidual = self.conv2(residual) # Convout = x + residual # sum����return out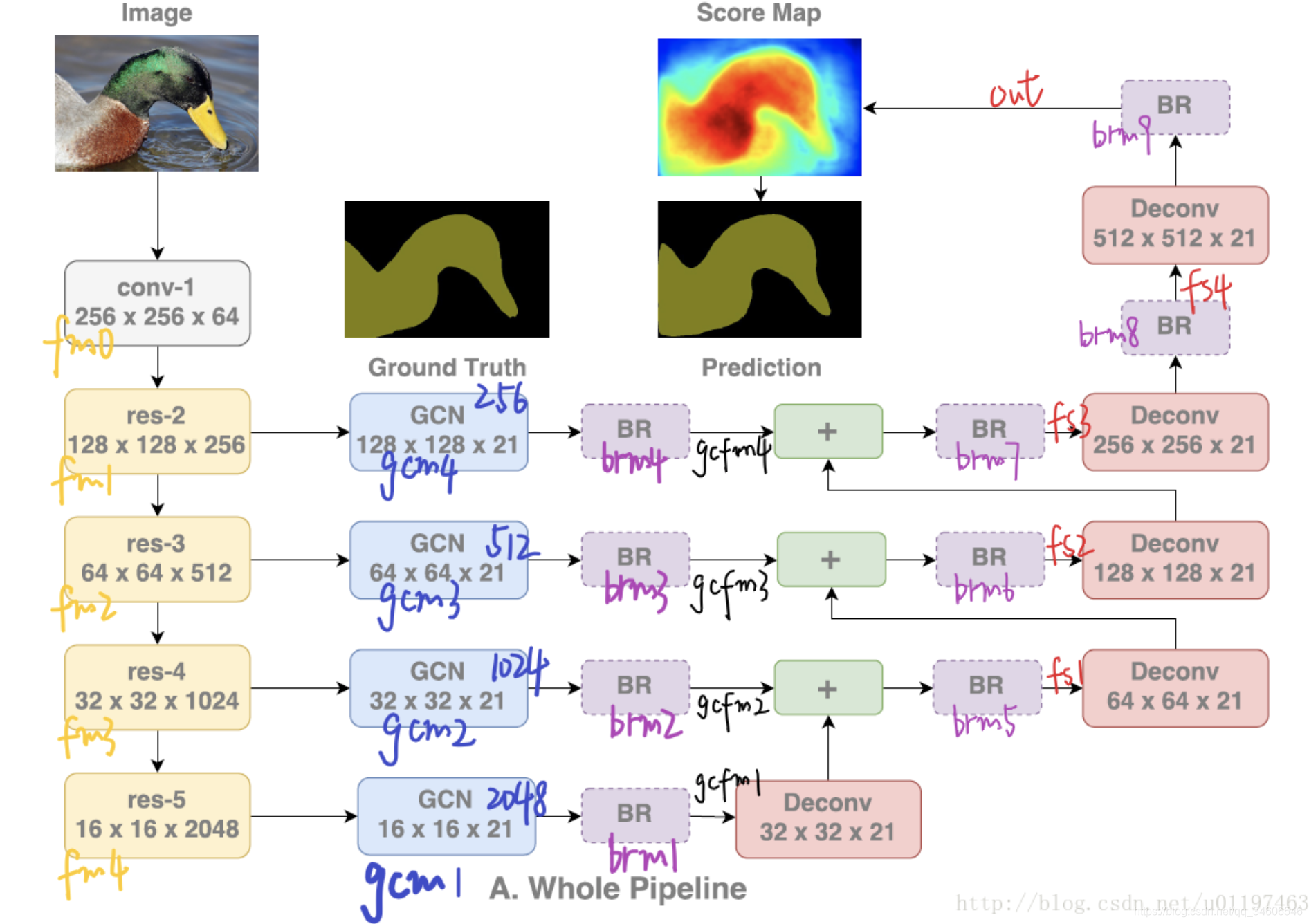
class GCN(nn.Module):def __init__(self, num_classes, input_size, pretrained=True):super(GCN, self).__init__()self.input_size = input_sizeresnet = models.resnet152()if pretrained:resnet.load_state_dict(torch.load(res152_path))self.layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu)self.layer1 = nn.Sequential(resnet.maxpool, resnet.layer1)self.layer2 = resnet.layer2self.layer3 = resnet.layer3self.layer4 = resnet.layer4# ����GCNģ��self.gcm1 = _GlobalConvModule(2048, num_classes, (7, 7))self.gcm2 = _GlobalConvModule(1024, num_classes, (7, 7))self.gcm3 = _GlobalConvModule(512, num_classes, (7, 7))self.gcm4 = _GlobalConvModule(256, num_classes, (7, 7))# ����BRģ��self.brm1 = _BoundaryRefineModule(num_classes)self.brm2 = _BoundaryRefineModule(num_classes)self.brm3 = _BoundaryRefineModule(num_classes)self.brm4 = _BoundaryRefineModule(num_classes)self.brm5 = _BoundaryRefineModule(num_classes)self.brm6 = _BoundaryRefineModule(num_classes)self.brm7 = _BoundaryRefineModule(num_classes)self.brm8 = _BoundaryRefineModule(num_classes)self.brm9 = _BoundaryRefineModule(num_classes)initialize_weights(self.gcm1, self.gcm2, self.gcm3, self.gcm4, self.brm1, self.brm2, self.brm3,self.brm4, self.brm5, self.brm6, self.brm7, self.brm8, self.brm9)def forward(self, x):# if x: 512fm0 = self.layer0(x) # 256fm1 = self.layer1(fm0) # 128fm2 = self.layer2(fm1) # 64fm3 = self.layer3(fm2) # 32fm4 = self.layer4(fm3) # 16gcfm1 = self.brm1(self.gcm1(fm4)) # 16gcfm2 = self.brm2(self.gcm2(fm3)) # 32gcfm3 = self.brm3(self.gcm3(fm2)) # 64gcfm4 = self.brm4(self.gcm4(fm1)) # 128# �ϲ����ں����fs1 = self.brm5(F.upsample_bilinear(gcfm1, fm3.size()[2:]) + gcfm2) # 32fs2 = self.brm6(F.upsample_bilinear(fs1, fm2.size()[2:]) + gcfm3) # 64fs3 = self.brm7(F.upsample_bilinear(fs2, fm1.size()[2:]) + gcfm4) # 128fs4 = self.brm8(F.upsample_bilinear(fs3, fm0.size()[2:])) # 256out = self.brm9(F.upsample_bilinear(fs4, self.input_size)) # 512return out