对Apriori算法的改进
Apriori算法在挖掘事物关联规则有一定的弊端,也就是在数据量过大,而最小支持度阈值却很低的情况下,Apriori算法对事物数据库的遍历,尤其在编程过程中对组合步骤中,嵌套了过多的循环,导致挖掘效率低下。对此,做出改进的经典算法之一是FP-growth算法。
FP-growth算法
FP-growth是频繁模式增长(Frequent-Patter Growth)简称。它采用分治策略:
- 首先,对事物数据库的每个项计数,记录到一个表里,并将按照频次从大到小的项排序,这个表叫做heard。
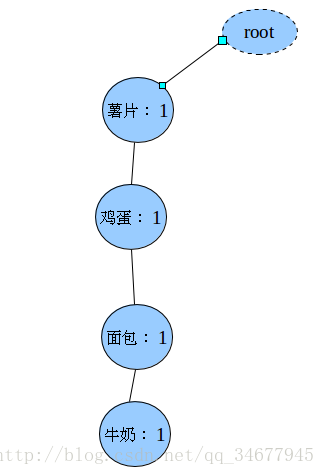
- 构造FP-树。FP树的根节点是个哑信号,接着对事物数据库的每一条记录查找:首根据heard中排好序的项,找出记录中频次最多的项加到父亲节点下(如果没有就创建新的孩子节点),并且记录它出现的次数(cunt++);接着添加频次次之的项…;直到数据库中所有记录添加完成,FP树就构造好了。
例如:
插入第一条(薯片>鸡蛋>面包>牛奶)之后
插入第二条记录(薯片>鸡蛋>啤酒)
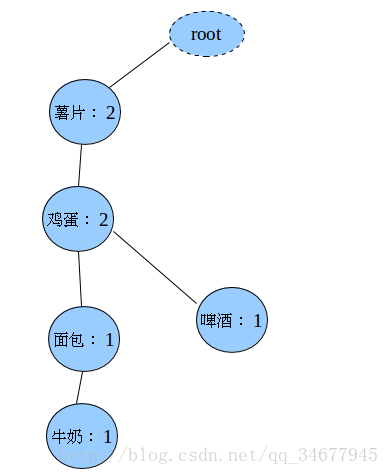
注意:A>B是指这条记录中A在heard表中的频次大A在heard表中的频次 - 在FP树中,根节点到每个孩子的距离便是一条数据库中的记录,而且节点记录的次数是从上到下逐渐降低的,这样,我们挖掘的数据被压缩到树上,根据节点的计数信息,从叶子节点开始向上可以找出条件模式基,对条件模式基的有序子集查找与过滤可以得到条件FP树,产生的频繁模式是条件FP树的项集合,频繁大小是项集最小项的频次数。
总结
以上是个人理解,作为学习记录。