ʵ��GROUP BY�Ӿ����÷�����ɨ��������������һ���µ���ʱ��������ÿ�����е������ж��������ģ�Ȼ��ʹ�ô���ʱ���������鲢Ӧ�þۺϺ���������У�����ijЩ����£�MySQL�������ñ�����ã�ͨ��ʹ���������ʱ��ⴴ����ʱ����
ʹ��GROUP BY����������Ҫǰ�������ǣ�����GROUP BY�����õ���������ͬһ�������������������˳��洢keys �����磬BTREE����������HASH���������Ƿ����ͨ�������������滻��ʱ����ʹ�û�ȡ���ڲ�ѯ��ʹ������������Щ���֣�Ϊ��Щ����ָ���������Լ���ѡ�ۺϺ�����
�����ַ���ͨ����������ִ��GROUP BY��ѯ�������¸����������ڵ�һ�ַ����У�������������з�Χν�ʣ�����еĻ���һ��Ӧ�á��ڶ��ַ�������ִ�з�Χɨ�裬Ȼ��Եõ���Ԫ����з��顣
Loose Index Scan
Tight Index Scan
Loose Index Scan
����GROUP BY������Ч������ʹ������ֱ�Ӽ��������columns��ʹ�����ַ�??�ʷ�����MySQLʹ��keys�����һЩ�������ͣ����磬BTREE�������ԡ�������֧����������ʹ�ò���groups�������ؿ�����������������WHERE����������keys���˷��ʷ��������������еIJ���keys����˳�Ϊ��ɢ����ɨ�衣��û��WHERE�Ӿ�ʱ����ɢ����ɨ����ȡ��groups������ͬ��keys������ܱ�������Կ�������ٵöࡣ���WHERE�Ӿ������Χν�ʣ���μ� Section 8.8.1, ��Optimizing Queries with EXPLAIN���ж� range join type�����ۣ�����������ɨ���������㷶Χ������ÿ���е�һ��key�����ٴζ�ȡ�������ٵ�keys������������¿�����������
The query is over a single table.
The
GROUP BYnames only columns that form a leftmost prefix of the index and no other columns. (If, instead ofGROUP BY, the query has aDISTINCTclause, all distinct attributes refer to columns that form a leftmost prefix of the index.) For example, if a tablet1has an index on(c1,c2,c3), loose index scan is applicable if the query hasGROUP BY c1, c2,. It is not applicable if the query hasGROUP BY c2, c3(the columns are not a leftmost prefix) orGROUP BY c1, c2, c4(c4is not in the index).The only aggregate functions used in the select list (if any) are
MIN()andMAX(), and all of them refer to the same column. The column must be in the index and must immediately follow the columns in theGROUP BY.Any other parts of the index than those from the
GROUP BYreferenced in the query must be constants (that is, they must be referenced in equalities with constants), except for the argument ofMIN()orMAX()functions.For columns in the index, full column values must be indexed, not just a prefix. For example, with
c1 VARCHAR(20), INDEX (c1(10)), the index cannot be used for loose index scan.
�����ɢ����ɨ�������ڲ�ѯ����EXPLAIN�������Extra������ʾ Using index for group-by��
�����t1��c1��c2��c3��c4���ϴ�������idx��c1��c2��c3������ɢ����ɨ����ʷ������������²�ѯ��

��������ԭ������select��ѯ��ʹ����ɢ����ɨ����
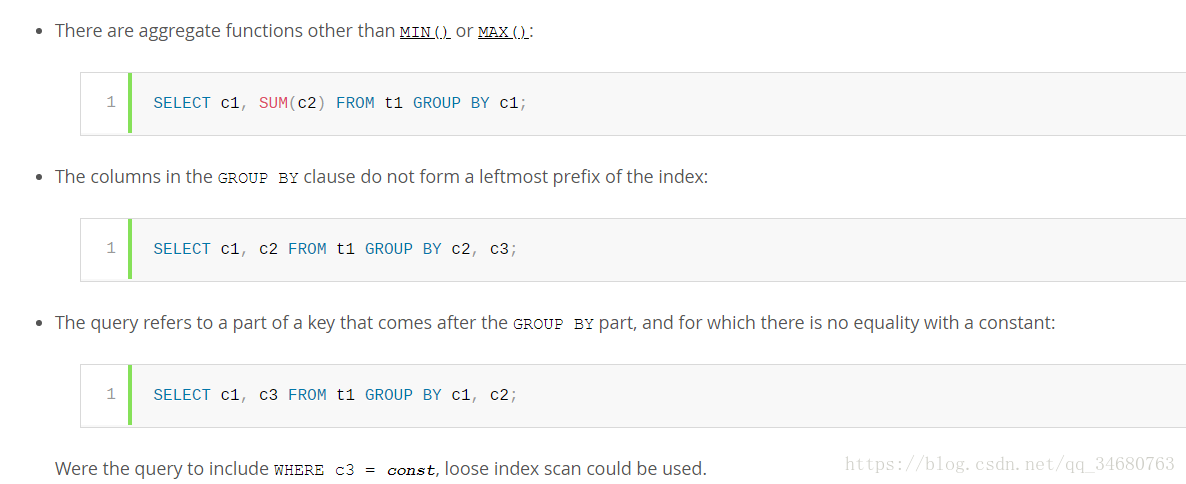
������֧�ֵ�MIN������MAX���������⣬��ɢ����ɨ����ʷ���������Ӧ����select�б���������ʽ�ľۺϺ������ã�
AVG(DISTINCT),SUM(DISTINCT), andCOUNT(DISTINCT)are supported.AVG(DISTINCT)andSUM(DISTINCT)take a single argument.COUNT(DISTINCT)can have more than one column argument.There must be no
GROUP BYorDISTINCTclause in the query.The loose scan limitations described earlier still apply.
�����t1��c1��c2��c3��c4���ϴ�������idx��c1��c2��c3������ɢ����ɨ����ʷ������������²�ѯ��

Tight Index Scan
�ϸ������ɨ�������ȫ����ɨ���Χ����ɨ�裬����ȡ���ڲ�ѯ������
��û��������ɢ����ɨ�������ʱ���Կ��Ա���ΪGROUP BY��ѯ������ʱ�������WHERE�Ӿ����з�Χ��������˷���ֻ��ȡ������Щ������keys����������ִ������ɨ�衣��Ϊ�˷�����ȡWHERE�Ӿ䶨���ÿ����Χ�ڵ�����keys��������û�з�Χ����ʱɨ������������������dz���Ϊ�ϸ������ɨ�衣ʹ���ϸ�����ɨ��ʱ��ֻ�����ҵ����㷶Χ����������keys���ִ�з��������
Ϊ��ʹ���ַ��������ã���ѯ�������棬��GROUP BY key֮ǰ��֮���key part��Ӧ���ж���һ�������������㹻�ˡ�������������ij�����������ؼ����е��κΡ���϶�����Ա�����γ�����������ǰ����Щ����ǰ���������������ҡ����������Ҫ��GROUP BY������������ҿ����γ���Ϊ����ǰ�������ؼ��֣���ôMySQLҲ��������������������Ϊ������������ʹ��ǰ���������Ѿ���˳��������йؼ��֡�
�����t1��c1��c2��c3��c4���ϴ�������idx��c1��c2��c3�������²�ѯ��������ǰ�������Ŀ�������ɨ����ʷ���������Ȼ�������ϸ������ɨ����ʷ�����
