二分图最大权匹配(maximum weight matching in a bipartite graph)
带权二分图:二分图的连线被赋予一点的权值,这样的二分图就是带权二分图
KM算法求的是完备匹配下的最大权匹配: 在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹配使得所有wij的和最大。
完备(美)匹配:二分图中左右子图中的各点都有对应的匹配。
带权重的二分图我们可以把它看成一个所有X集合的顶点到所有Y集合的顶点均有边的二分图(把原来没有的边添加入二分图,权重为0即可),也就是说它必定存在完备匹配(即其匹配数为min(|X|,|Y|))为了使权重达到最大,我们实际上是通过贪心算法来选边,形成一个新的二分图(我们下面叫它二分子图好了),并在该二分图的基础上寻找最大匹配,当该最大匹配为完备匹配时,我们可以确定该匹配为最佳匹配(最大匹配:匹配边数最多的匹配,最佳匹配:匹配边的权重和最大的匹配。)
KM算法是通过给每一个点一个顶标来把求最大权匹配的问题转换为求完备匹配的问题。
初始时左图中点的顶标等于与该点相连的边中边权最大的值,右图中点的顶标等于0。设左图的顶标为A[i] ,右图的顶标为B[j] ,顶点之间的边权为 w[i] [j],可行性顶标 A[i] +B[j] >= w(i,j),即顶标始终满足对于任意的一条边,它连接的两个顶点的顶标和大于等于该边的边权。
而将最大权匹配转换为完备匹配的关键定理就是:若由二分图中所有满足A[i] +b[j]=w[i][j] 的边<i,j> 构成的子图(也称相等子图) 有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
以下讲解改编自:https://blog.csdn.net/thundermrbird/article/details/52231639
贪心算法总是将最优的边优先加入二分子图,该最优的边将对当前的匹配子图带来最大的贡献,贡献的衡量是通过标杆来实现的。下面我们将通过一个实例来解释这个过程。
有带权二分图:
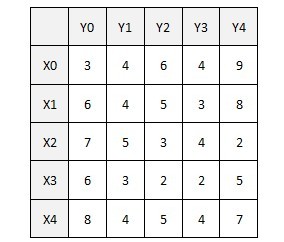
算法把权重转换成标杆,X集跟Y集的每个顶点各有一个标杆值,初始情况下权重全部放在X集上。由于每个顶点都将至少会有一个匹配点,贪心算法必然优先选择该顶点上权重最大的边,初始情况下生成的二分子图是:
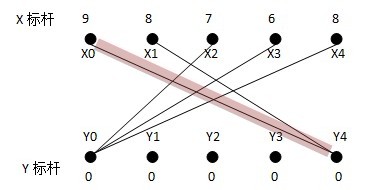
以下是KM生成完备匹配的的过程:
(1)从X0找增广路径,找到X0Y4,因为满足A[i]+B[j]==W[i][j]的只有Y4,而此时Y4未匹配,所以找到X0Y4
(2)从X1找增广路径,此时满足A[1]+B[j]==W[i][j]的只有Y4,但是Y4已经被匹配,所以从X1找不到增广路径,也就是说,必须往二分子图里边添加新的边,使得X1能找到它的匹配,同时使权重总和添加最大。由于X1通往Y4而Y4已经被X0匹配,所以有两种可能,一个是为X0找一个新的匹配点并把Y4让给X1,或者是为X1找一个新的匹配点,此时就要修改顶标来加入新的边。
修改方法:当找不到增广路径时,(此时已经完成了搜索才知道匹配不了,并且对于搜索过的路径上的XY点,已经记下了哪些结点被访问那些结点没有被访问),设该路径上的X顶点集为S,Y顶点集为T,对所有在S中的点xi及不在T中的点yj,计算d=min{(L(xi)+L(yj)-weight(xiyj))},然后调整lx和ly:对于访问过的x顶点,将它的可行标减去d,对于所有访问过的y顶点,将它的可行标增加d,由于S集中的X标杆减少了,而不在T中的Y标杆不变,相当于这两个集合中的L(x)+L(y)变小了,也就是,有新的边可以加入二分子图了,修改后的顶标仍是可行顶标。
在这个例子中,S={X0, X1},Y={Y4},求出最小值d=L(X1)+L(Y0)-weight(X1Y0)=2,得到新的二分子图:
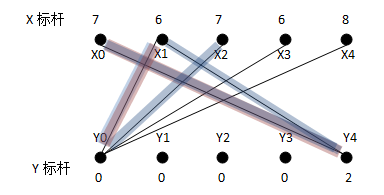
重新为X1寻找增广路径,找到X1Y0(此过程是一个循环的过程,直到匹配终止),可以看到新的匹配子图的权重为9+6=15,比原先的不合法的匹配的权重9+8=17正好少d=2。
(3)接下来从X2出发找不到增广路径,其走过的路径如蓝色的路线所示。形成的非法匹配子图:X0Y4,X1Y0及X2Y0的权重和为22。在这条路径上,只要为S={X0,X1,X2}中的任意一个顶点找到新的匹配,就可以解决这个问题,于是又开始求d。
d=L(X0)+L(Y2)-weight(X0Y2)=L(X2)+L(Y1)-weight(X2Y1)=1.
新的二分子图为:
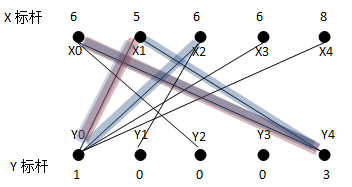
重新为X2寻找增广路径,如果我们使用的是深搜,会得到路径:X2Y0->Y0X1->X1Y4->Y4X0->X0Y2,即奇数条边而删除偶数条边,新的匹配子图中由这几个顶点得到的新的权重为21;如果使用的是宽搜,会得到路径X2Y1,另上原先的两条匹配边,权重为21。假设我们使用的是宽搜,得到的新的匹配子图为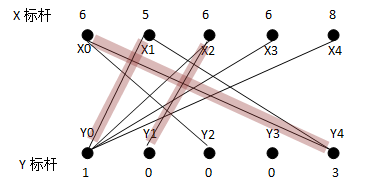
(4)接下来依次类推,直到为X4找到一个匹配点。
KM算法的最大特点在于利用标杆和权重来生成一个二分子图,在该二分子图上面找最大匹配,而且,当些仅当找到完备匹配,才能得到最佳匹配。标杆和权重的作用在于限制新边的加入,使得加入的新边总是能为子图添加匹配数,同时又令权重和得到最大的提高。
总计下步骤:
基本上可以概括成以下几个步骤:
(1) 初始化可行标杆
(2) 用匈牙利算法寻找完备匹配
(3) 若未找到完备匹配则修改可行标杆
(4) 重复(2)(3)直到找到相等子图的完备匹配
总结:在写代码的过程中出现了一个问题,出现了艰苦的调试过程,见调试代码
1、代码:
#二分图最大权匹配算法KMdef Matching(i):#匹配S[i]=1for j in range(1,n+1):if Lx[i]+Ly[j]==W[i][j] and T[j]==0:#i到j可行,且j未被访问T[j]=1if match[j]==0 or Matching(match[j]):match[j]=ireturn Truereturn Falsedef update():#更新顶标值inc=9999999999999for i in range(1,n+1):#扫描x集合的点,找出在S中的点if S[i]==1:for j in range(1,n+1):#扫描y集合的点,找出不在T中的点if T[j]==0 :inc=min(inc,Lx[i]+Ly[j]-W[i][j]) for i in range(1,n+1):if S[i]==1:#对于所有访问过的x顶点,将它的顶标减去incLx[i]=Lx[i]-incif T[i]==1:#对于所有访问过的y顶点,将它的顶标加上incLy[i]=Ly[i]+incdef KM():#初始化顶标值for i in range(1,n+1):Lx[i]=max(W[i])Ly[i]=0for i in range(1,n+1):#为A集合的每个点找匹配while(1):'''刚开始没有设置全局,一直错一直错,调了一天多才找出这个问题,唉函数内部定义的是局部list S,T,但Matching函数里面使用的S,T是全局的S,T,局部的清零操作影响不到全局,所以一直错。。。。。,虽然错了但学到了一些东西'''global S,T S=[0]*(n+1);T=[0]*(n+1)#每次匹配之前都要清零if Matching(i)==True:#可以匹配,跳出循环breakupdate()#不能匹配,更新顶标值while True:n=int(input("\n请输入一个整数n,表示x,y两个集合的元素个数:"))print("请输入{0}行,每行{1}个数,用空格隔开:".format(n,n))W=[]#存储边的权值L=[0 for i in range(0,n+1)]W.append(L)for i in range(1,n+1):L1=[0]+[int(e) for e in input().split()]W.append(L1)Lx=[0]*(n+1);Ly=Lx[:]#存储A、B集合的顶标值S=[0]*(n+1);T=[0]*(n+1)#记录寻找增广路时点集A,B里的点是否搜索过match=[0]*(n+1)#B集合第i个点在A集合中的匹配编号KM()Sum=0for i in range(1,n+1):Sum=Sum+W[match[i]][i]print(Sum)2、调试代码(可以运行,但是里面记下了我的调试过程的输出结果,纪念一下)
'''
纪念辛苦调试程序的自己,记住自己的调试方法,下次还可以再用
程序中绿色的全是调试程序时输出的中间结果
刚开始不知道怎么输出中间结果,不知道应该输出哪些,但是不要急躁,沉入下去慢慢就想出来了
'''def Matching(i):'''print("进入Maching")print("M函数内Lx",Lx) print("M函数内Ly",Ly)'''S[i]=1for j in range(1,n+1):'''print("print Lx[i],Ly[j],W[i][j],T[j]" ,Lx[i],Ly[j],W[i][j],T[j])'''if Lx[i]+Ly[j]==W[i][j] and T[j]==0:#i到j可行,且j未被访问#print("进入匹配")T[j]=1if match[j]==0 or Matching(match[j]):match[j]=i#print("OK")return Truereturn Falsedef update():'''print("进入UPDATE")'''inc=9999999999999for i in range(1,n+1):#扫描x集合的点,找出在S中的点if S[i]==1:for j in range(1,n+1):#扫描y集合的点,找出不在T中的点if T[j]==0 :inc=min(inc,Lx[i]+Ly[j]-W[i][j])'''print("inc=",inc) ''' for i in range(1,n+1):if S[i]==1:#对于所有访问过的x顶点,将它的顶标减去incLx[i]=Lx[i]-incif T[i]==1:#对于所有访问过的y顶点,将它的顶标加上incLy[i]=Ly[i]+inc'''print("函数内Lx",Lx) print("函数内Ly",Ly)'''def KM():#初始化顶标值for i in range(1,n+1):Lx[i]=max(W[i])Ly[i]=0for i in range(1,n+1):#为A集合的每个点找匹配'''t=3print("i=",i)flag=False'''while(1): #死循环输出的中间结果不好看,可把1改成一个参数控制循环的次数,我改成了t,初值为3,每次循环减一global S #刚开始没有设置全局,一直错一直错,调了一天多才找出这个问题,唉global T #调试了很久,很崩溃,但还是学到了很多,S=[0 for i in range(0,n+1)]#相当于重新定义了局部列表S,T,但Matching函数里面使用的S,T是全局的S,TT=[0 for i in range(0,n+1)]#所以一直没有把全局的S,T清零,只是清空了局部的,会一直错'''print("S",S)print("T",T)'''if Matching(i)==True:breakupdate()'''t=t-1'''while True:n=int(input("\n请输入一个整数n,表示x,y两个集合的元素个数:"))print("请输入{0}行,每行{1}个数,用空格隔开:".format(n,n))W=[]#存储边的权值L=[0 for i in range(0,n+1)]W.append(L)for i in range(1,n+1):L1=[0]+[int(e) for e in input().split()]W.append(L1)'''print(W)'''Lx=[0 for i in range(0,n+1)];Ly=Lx[:]#存储A、B集合的顶标值S=[0 for i in range(0,n+1)];T=[0 for i in range(0,n+1)]#记录寻找增广路时点集A,B里的点是否搜索过match=[0 for i in range(0,n+1)]#B集合第i个点在A集合中的匹配编号KM()Sum=0for i in range(1,n+1):Sum=Sum+W[match[i]][i]print(Sum)