˵��
1.ԭ�����ӡ�
2.���˼����������ķ���ˮƽ���ޣ��ֶ����ɣ������뿴ԭ�ġ�
����
1.��Ŀ�������������Ƽ���Ⱥ��֪��������ͼ��ʾѧϰ
????Group-Aware Long- and Short-Term Graph Representation Learning for Sequential Group Recommendation
2.���ߣ�
??����ʦ����ѧ��������Ӧ�ò��š�����������ѧԺ

ժҪ
??˳���Ƽ���Ⱥ�Ƽ����Ƽ�ϵͳ�е�������Ҫ��֧����Ȼ�����Ѿ�����������֧�����˴����������о���������������µ�����Ⱥ�Ƽ����⣬�����ǽ����һ�𣬸������ܹ���ģȺ�Ķ�̬��ʾ����ʵ�ָ��õ�Ⱥ�Ƽ����ܵĹؼ������������Ҫ��ս�������Ч��ѧϰ�������Ա�ڹ�ȥʱ������������û�-����Ķ�̬���ʾ��Ϊ�˽��������⣬���������һ�����֪�ij�������ͼ��ʾѧϰ��������GLS-GRL������˳�����Ƽ��������˵������һ��Ŀ��Ⱥ�壬���ǹ���һ��Ⱥ���֪�ij���ͼ����������ʷ�е��û��������Ŀ-��Ŀ���֣��Լ�һ��Ⱥ���֪�Ķ���ͼ���������ڵ�ǰʱ���ܵ���ͬ��Ϣ��������Щͼ��GLS-GRL����ͼ��ʾѧϰ����ó��ںͶ����û���ʾ��Ȼ������Ӧ���ں����ǣ���ü��ɵ��û���ʾ�����ͨ��Լ���û�����ע��������������Ա֮��Ĺ������Ӷ��õ����ʾ���ۺ�ʵ�������GLS-GRL��������������Ƽ���Ⱥ�Ƽ�����ǿ�����������֤��GLS-GRL�����������Ч�ԡ�
1 ����
??�ִ��Ƽ�ϵͳ�������û�-��Ʒ�Ľ�����ʽ�����ž������ص����á��������Ϣ��ը��ʱ������һ����Ϊ��Ҫ�������ʱ�����û��ձ���������Ϣ���ص�����(���磬����ѷ����������IJ�Ʒ��Twitter���д��ģ����ý���û���������)����ˣ��������о�������Ϊ��ͬ���Ƽ��������ÿ�����Ч���Ƽ�ģ�ͺ��㷨��˳���Ƽ�[17,33]���ⷽ���һ���о��ȵ㣬��Ŀ����Ԥ��Ŀ���û�Ը����֮��������һ�������������һ����Ҫ����ս����ѧϰ����˳���û�����Ķ�̬�û�ƫ�ñ�ʾ���ݹ�������(RNNs)[8]������������(CNNs)[19]��ǿ���ע��������[10]���Լ������ͼ������(GNNs)[26]�ѱ�Ӧ����������⡣
??����һ���Ƕ�������һЩ�о�������ǽ��Ƽ��IJ�Ʒ�ṩ��Ŀ���û��������������ǰ���һ���˳���Ƽ��������û�����������Ϊ�����Ƽ�[15]���û�Ⱥ����ʽ�������罻ý���зdz��ձ飬��meetup1���û�����֯��С�飬����һЩ���»��facebook2��С������Ȥ���ֲ����ţ��û��������ɴ���С�����졣����ʹ����ƽ��Ⱥ���Ա[2]��ƫ�÷��������ľ�������⣬�������Ⱥ���Ƽ����о�����������Զ���������ƫ�����γ�Ⱥ����ƫ���е������Ҫ�ԡ����������Եļ�����֧�Ǹ���ģ��[13]�ͻ���ע�����ķ���[3]��Ȼ�����о���ĿǰΪֹ���������Ϊ��̬�Ƽ����������Ŷӳ�Ա��Ϊ��˳���ԡ�
??�ڱ����У����������һ���µ����⣬��˳��Ⱥ�Ƽ�(SGR)����λ��˳���Ƽ���Ⱥ�Ƽ��Ľ���㡣��ͼ1��ʾ��������ּ������Ŀ�����Ա�ڹ�ȥʱ�����е�˳���������Ԥ����Щ�����һ��ʱ�����д�Ŀ�����Ա��ø��ཻ���������罻ƽ̨�Ͽ��ܻʱ�����������û���ɵ���Ⱥ�飬������������Ҫͬʱ������Ⱥ�����Ⱥ���Ƽ���Ʒ����֮ǰ��Ⱥ���Ƽ�����������ȣ�˳��Ⱥ���Ƽ����к�ǿ�Ĺ����ԣ��ܹ���ģ��˳���Ƽ�������Ⱥ�鶯̬��ʾ���������Ⱥ���Ƽ������ܺ���ϣ����ֵ��ע����ǣ���Ȼ��Щ�о�[14,27]�漰��˳���Ƽ��ͷ���ĸ�������������ǵ��о����Ÿ����IJ�ͬ����Ϊ:(1)ǰһ���о�Ϊ�Ự�Ƽ������������䷽����ȫ��ʵ֤�ģ�û��ģ��ѧϰ����;(2)����ʵ����������Ⱥ��ƫ�����ٽ��Ը����û���˳���Ƽ����Կ˷�ϡ�������⡣
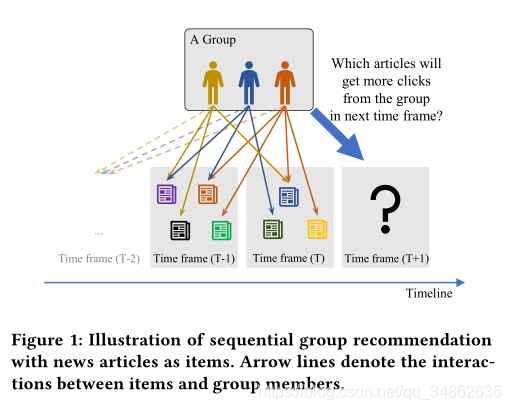
??Ϊ�˽��������⣬һ����������ս�������Ч��ѧϰ�������Ա�ڹ�ȥʱ������������û�-����Ķ�̬���ʾ��ʵ���ϣ����ʾ�������Ա�Ķ�̬��ʾ����ӳ�ģ����ֶ�̬��ʾ�������������飬Ҳ���������顣��ˣ��û���ʾ�DZز����ٵģ����ֲ����ض��û�-��������ʾ֮��IJ�ࡣȻ������Ļ�����ս�ֽ�Ϊ�������ս:
??-����������Ա��ϵ��˳����û�������˽��û���ʾ?
??-������û�õ��û���ʾ����ʾ��ƫ��?
??Ϊ�˸��õؽ�������������⣬���������Ⱥ���֪��������ͼ��ʾѧϰ(Group-aware Long- and - short Graph Representation Learning)ģ�͡��÷���ʹ���Ա��ϵ�ܹ�Ӱ���û���ʾ��ѧϰ�ͻ�������õ��û���ʾ�����ʾ��ʵ�֣���һ���ܵ������ǵĻ�ӭ�������˵����ÿ��ʱ�����У��������ȹ�����֪��ij��ںͶ���ͼ��������ͼ��������ͬһĿ����������û�������ͼ����������ʷ�е��û�-��Ŀ��������Ŀ-��Ŀ���֣�������ͼֻ�������ڵ�ǰʱ���ܵ���Ϣ����������ͼ�Ļ����ϣ�GLS-GRL��������ͼ����ͼ��ʾѧϰ���ֱ�ѧϰ�û��ij���ʾ�Ͷ��ڱ�ʾ��ͨ��һ����բ�Ż������ں����������͵ı�ʾ���Ի�ü��ɵ��û���ʾ������������һ����ս�õ��˽�������ڵڶ�����ս��GLS-GRL��һ��������һ����Լ�����û�����ע����������ע����������ע��������[20]�����ġ���ͨ����ʾһ���û�w.r.t���������Ա֮�������ԣ�����ѡ����������Ա�ı�ʾ����Щ��Ա��Ҫ������һ����ͬ��������Ŀ�����ʾ����ͨ�������û���ʾ��ʵ�֡�
??������������Ҫ��������:
- ���������һ���µ����⣬��˳��Ⱥ���Ƽ�������Ҫ��Ⱥ���ʾ��˳����ѧ���н�ģ��������Ŀǰ��Ⱥ���Ƽ��о��б������ˡ�
- ���ǿ�����GLS-GRLģ�ͣ�����֮����ͨ����Ӧ�����֪��������ͼ��ѧϰ���������û���ʾ���Լ����ʾѧϰ���û���ʾѧϰ����ϡ�
- ������������ʵ���ݼ��Ͻ�����ȫ���ʵ�飬֤����GLS-GRL��ǿ���������Ⱦ��и��õ����ܣ���֤��ģ�͵�һЩ�ؼ���ơ�
2 ����о�
??�ڱ����У����Ǵ�˳���Ƽ���Ⱥ���Ƽ���GNNs�Ƽ���������ع�������о���
2.1 �����Ƽ�
??��һ����Ƽ��������ò�ͬ��˳���Ƽ����ص����ڽ���û���Ϊ��˳�����ԣ���Ԥ���û��ڲ��õĽ���(������һ��)��ϲ��ʲô�����ڹ���˳���Ƽ����о�������һ�������Ʒ���裬����һ������ֻ������ͬһ�û���ǰ�Ľ������������ڹ��ɼ����ķ���[5]��DZ������ģ��[17]�������ѧϰ�㷺�ɹ���������������RNNs��CNNs��attention mechanism��GNNs��Ӧ����˳���Ƽ���������˵�������Ե��о�[8]ͨ��������õ���Ŀ��Ϊ���������ø������RNNs��ͨ����������ӳ�䵽Ƕ�������֤������ͼ�����Ļ�����ʩCNNs[19]���ⷽ����һ���̶��ϵ���Ч�ԡ�������ͬ����Ҫ�Թ�ȥ��������µ�Ԥ�⣬����ע�����[10 - 12,18]������һ���Ƕ�������GNNs��������ģΪһ��ͼ���⽫��2.3�������ۡ�
??��������е�˳���Ƽ�����������Ե����û��ġ�һ�����뷨��ֱ��������Щ������ѧϰ�û���ʾ��Ȼ��ͨ��һЩ�ںϷ������ۺ����ǡ����ǣ��������������Ա��ϵ������û���ʾ�����ڵ�һ����ս�еõ���ǿ����ֵ��ע����ǣ����Dz��ܽ���idӳ�䵽Ƕ������ǿ�����ʾ����ΪӦ�ô�����ѵ����û�г��ֵ����顣
2.2 Ⱥ���Ƽ�
??���Ƽ���Ҫ�ں��û��������г�Ա�ĸ�����ѡ�Ϊ�ˣ��������Ȳ�����һЩʵ֤�ġ��IJ��ԡ�O 'Connor����[15]ʹ��������û���ƫ������ʾȺ���ε�ƫ��(�ֳ��ʹ�����)��[2]�Ƚ��˰�����ƽ���ۺϲ������ڵļ���ƫ�þۺϲ��ԣ�����:(1)��Щ���ԵĽ�����ƣ�(2)Ⱥ���Ƽ��ȸ����Ƽ��ѡ�Ȼ������Щ���Զ��е�̫���������壬û��һ��ѧϰ������ָ���ۺϡ�
??Ϊ���Զ����������Ӱ�죬��������˸���ģ��[6,13,28,31]��������Ʒ�Ƽ���Ϊһ�����ɹ��̡���Щģ�����Ļ��������ǣ�����ΪĿ����(��ͬһ���еij�Ա)ѡ��һ���û���Ȼ����ݸ��û�����������������������ǣ�������һ�����ƣ����û����������ķֲ�(Ҳ����Ϊ�û���ʾ)��������[20]�������������ȱ�ʾѧϰ��ģ�ͱ����[3,20,29]�����Ƕ�����ע�����[1]���������Ӱ��Ȩ��w.r.t.�ض�Ⱥ�壬�Ӷ���Ч�ں��û�����������֤���ȸ���ģ�͵����ܸ��á�
??���ϵ�Ⱥ���Ƽ�������û�п����û���Ϊ��˳���ԣ����û���Ϊ��˳���Թ�����Ⱥ��Ķ�̬�ԡ����ʹ���������˳�����Ƽ��Ϳ�����Ը�����Ķ���ģ�͡�ֵ��ע����ǣ�һЩ�о�[32]��Ⱥ���Ƽ��ƶ�Ϊ���ض��û��Ƽ������Ⱥ�壬����һЩ�о�[9,27]����Ⱥ����Ϣ����������Ƽ����ܣ������ڸ����϶������о������ⲻͬ��
2.3 �����Ƽ���GNNs
??ͼ�����罫�û�-��Ʒ�Ľ�����ģΪͼ�������ܹ����߽������뵽��ά���û�����Ʒ��ʾ�У�����ܵ���ӭ�������PinSage[30]������ͨ��ͼ�ľ����㴫��itemitemͼ�ϵı�ʾ��NGCF[24]Ϊ�û�-��Ŀ����ͼ��ģ����ѧϰ�����û���Ϊ��RippleNet[22]����֪ʶͼ����������ʾ���û�ƫ�ô��������ܱ��Ƽ��ĺ�ѡ���Щ������Ϊһ����Ƽ��������������ģ�������û���Ϊ��˳��
??��˳���Ƽ��������µ��о�[16,23,25,26]��Ŀ���û��ĵ�ǰ�Ự��ģΪ��-��ͼ����ͬ�û��Ķ���Ựת��Ϊȫ�ֹ�������-��ͼ����һ����Ŀ�Ƽ���ͨ�������ѡ��Ŀ֮��������Ժ������Ự�ı�ʾ��ʵ�ֵġ������о�ͨ�����û��Ķ���ƫ�öԸ�������Ƽ���
??���֮�£����ǵ�Ŀ���ǻ�ȡ�û���˳�����Ƽ��ij��ںͶ���ƫ�ã���Ԥ��Ŀ��������һ��ʱ��λ��ϲ����Щ��Ŀ�����ǻ�ͨ�������ɸ�֪��ij��ںͶ���ͼ�̳��˻���gnn�Ľ�ģ˼�롣��ʹ���û���ʾѧϰ���������Ա��ϵ��˳����û������ָ����
3 ���ⶨ��
??��������U={u1,u2,��,u�OU�O}U = \{u_1,u_2,\dots,u_{|U|}\}U={
u1?,u2?,��,u�OU�O?}��V={v1,v2,��,v�OV�O}V = \{v_1,v_2,\dots,v_{|V|}\}V={
v1?,v2?,��,v�OV�O?}��ʾ�Ƽ�ϵͳ�������������Ԫ��,�ֱ�Ϊ�û�������Ŀ�����û���ggg������һ���û���Mg?UM_g\subseteq UMg??U,�������һ�����е����һ������Ⱥ�塣��ˣ�����������ܻ���ʱ����ı䡣Ϊÿ���û�u��Uu \in Uu��U,���DZ�ʾ�û��ij�����ʷ��ΪHul=(v0l,v1l,v2l,��)H_u^l=(v_0^l,v_1^l,v_2^l,\dots)Hul?=(v0l?,v1l?,v2l?,��)��Ӧ��������ʷ,��ʷ�Ͷ�����ΪHus=(v0s,v1s,v2s,��)H_u^s=(v_0^s,v_1^s,v_2^s,\dots)Hus?=(v0s?,v1s?,v2s?,��)��Ӧ�ڵ�ǰʱ��֡?�����ǽ�һ��������(Hul)(��(Hul)?V)��(H_u^l)(��(H_u^l) \subseteq V)��(Hul?)(��(Hul?)?V)����(Hus)(��(Hus)?V)��(H_u^s)(��(H_u^s) \subseteq V)��(Hus?)(��(Hus?)?V)�ֱ��ʾ��ʷ��Ϊ�а�������Ŀ��.
??������Щ���ţ��������ȶ������֪����ͼ�����֪����ͼ����:
??����1(Ⱥ���֪�ij���ͼ).Ggl={Vgl,Egl}\mathcal{G}_g^l=\{\mathcal{V}_g^l,\mathcal{E}_g^l\}Ggl?={
Vgl?,Egl?}��Ⱥ���֪�ij���ͼ�����ڸ���Ⱥ��ggg��������������(1)Vgl=?��(Hul)�Ou��Mg?Mg\mathcal{V}_g^l= \bigcup\Omega(H_u^l)|_{u \in M_g}\bigcup M_gVgl?=?��(Hul?)�Ou��Mg???Mg?;(2)Egl\mathcal{E}_g^lEgl?�����û�-��Ŀ����Ŀ-��Ŀ�ı߽��ɺ��Ľ��ܵ�ͼ�ṹ�����{Hul}�Ou��Mg\{H_u^l\}|_{u \in M_g}{
Hul?}�Ou��Mg??��Ϊ���롣
??;����2(Ⱥ���֪�Ķ���ͼ).Ggs={Vgs,Egs}\mathcal{G}_g^s=\{\mathcal{V}_g^s,\mathcal{E}_g^s\}Ggs?={
Vgs?,Egs?}��Ⱥ���֪�ij���ͼ�����ڸ���Ⱥ��ggg��������������(1)Vgs=?��(Hus)�Ou��Mg?Mg\mathcal{V}_g^s= \bigcup\Omega(H_u^s)|_{u \in M_g}\bigcup M_gVgs?=?��(Hus?)�Ou��Mg???Mg?;(2)Egs\mathcal{E}_g^sEgs?�����û�-��Ŀ����Ŀ-��Ŀ�ı߽��ɺ��Ľ��ܵ�ͼ�ṹ�����{Hus}�Ou��Mg\{H_u^s\}|_{u \in M_g}{
Hus?}�Ou��Mg??��Ϊ���롣
??Ⱥ���֪�ij���ͼ����Ⱥ���Ա�ij���ƫ�ã���Ⱥ���֪�Ķ���ͼ����עȺ���Ա�Ķ�̬ƫ�á���ˣ����������͵�ͼ��Ԥ����ڵĻ���������ʽ�ϣ����Ƕ�˳�����Ƽ�����Ķ�������:
??����1(����Ⱥ���Ƽ�).����һ��Ŀ��Ⱥ��ggg,����Ⱥ���֪�ij���ͼGgl\mathcal{G}_g^lGgl?�Ͷ���ͼGgs\mathcal{G}_g^sGgs?�����ݵ�ǰʱ��֡TTT������Ŀ���Ϊ��һ����ѡ��Ŀvvvѧϰһ������f(g,Ggl,Ggs,v)��sigf(g,\mathcal{G}_g^l,\mathcal{G}_g^s,v) \rightarrow s_i^gf(g,Ggl?,Ggs?,v)��sig?,����sigs_i^gsig?Ϊ����Ŀ��T+1T+1T+1ʱ��֡��Ⱥ�鼶���ƫ�õ÷֡�
??�ڲ��������������£�Ϊ�����������ʡ������Ⱥggg��ص��ϱ���±ꡣ
4 �����ģ��
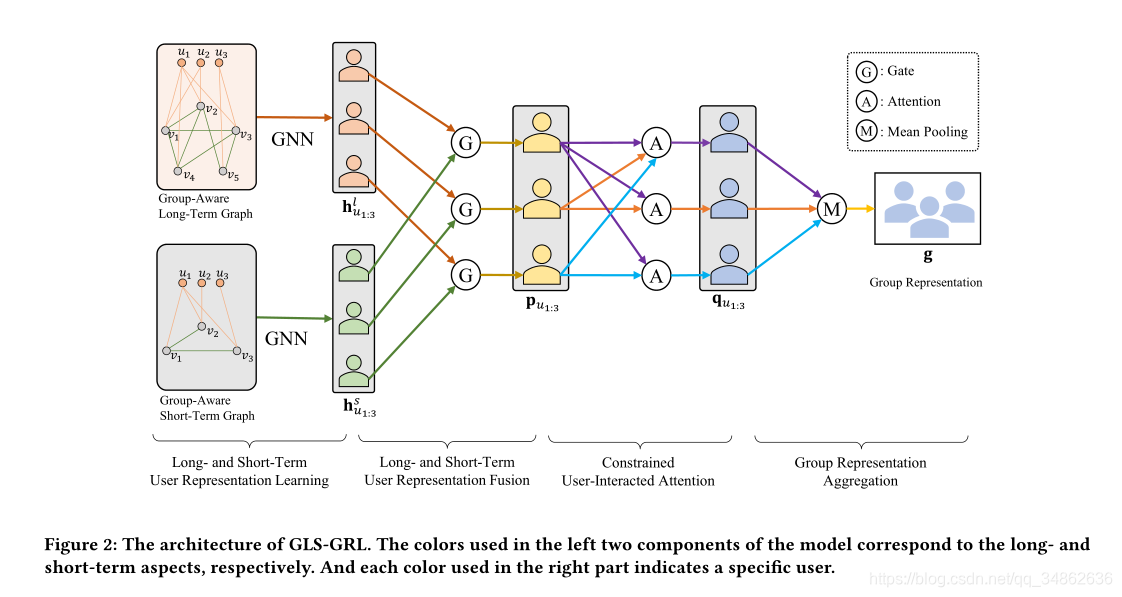
??���ǵ�GLS-GRLģ�͵�����ܹ���ͼ2��ʾ��������ij���ͼ�Ͷ���ͼ��Ϊ���룬����鼶��ʾ�������ƶȼ��㣬�����ѡ�Ƽ���һ������Ƽ�������(�����)ͼ�ǻ������Ա��������ʷ(��ǰʱ�䷶Χ��)��Ŀ�Ľ��������ġ�ͼ3��ʾ��һ�����ʾ����˵��������ͼ���Ľṹ��GLS-GRL���ĸ��ؼ�������ɣ�(1)���ںͶ����û�����ѧϰ��(2)���ںͶ����û������ںϣ�(3)�����û�����ע������(4)������ۺϡ������һ�ֻ��ڻ���������ʧ�������Ż�GLS-GRL���ڲ��������ؼ���ɲ��ֺ�Ŀ�꺯��֮ǰ��������˵��ͼ�ι������̡�
4.1 Ⱥ���֪��ͼ�ṹ
??�ڳ�����˳���Ƽ������У���¼�û�����Ŀ��˳�������ڹ������֪�ij��ںͶ���ͼ����������Ⱥ��Ա��Ϊ(��3(A)��ʾ)�������û���Ϊ(��3(B)��ʾ)Ϊ������˵��ͼ�Ĺ������̡��綨��1��2��������ģ�������ͼ������ͬ���û��ڵ㣬������Ŀ�ڵ������Ա��������ʷ(���ڳ���ͼ)���ڵ�ǰʱ�䷶Χ(���ڶ���ͼ)�н��������ݡ���ˣ���������ȷ��ͼ�еĽڵ㡣
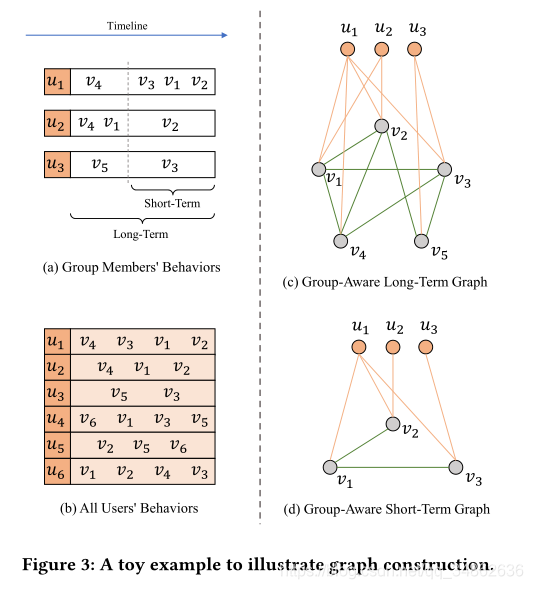
??Ȼ������������������ͼ�й���ߡ��ڹ����ͼ�����������͵ıߣ����û�-��Ŀ�ߺ���Ŀ-��Ŀ�ߡ�һ���棬�û����Ե��Ȼ�ز�����Ⱥ��Ա�Ķ�̬ƫ�á�����û���ȥ����ij����Ŀ���й������������һ�������Ӹ��û�����Ŀ����ͼ3(A)��ʾ���û�u1u_1u1?�ڵ�ǰʱ�䷶Χ������v3v_3v3?��v1v_1v1?��v2v_2v2?���������û�u1u_1u1?�����֪����ͼ�е���Щ��֮����ڱߣ���ͼ3(D)��ʾ�����Ƶأ������û�u3u_3u3?��������ʷ������v5v_5v5?��v3v_3v3?��������������֪����ͼ�д����û�����Щ��ıߣ���ͼ3?��ʾ����һ���棬��-���Ե���벻ͬ��֮��Ĺ�ϵ���ⱻ��Ϊ���û�ƫ�ø��ȶ�����ˣ����Ƕ�������ͼ�����ù���������������-��ߡ������˵�����������Ŀ�Ѿ��������κ��û����������Ǽ�����������Ŀ֮����ڱ�Ե�����磬���û�u1u_1u1?����Ϊ������ʾ������v1v_1v1?��v2v_2v2?���û��������������v1v_1v1?��v2v_2v2?Ӧ���������Ƶġ�
4.2 ���ںͶ����û�����ѧϰ
??��ѧϰ��ͼ��ϵ����Ϊ��ά�û���ʾ֮ǰ����һ���ǹ����û�����������ʾ��Ϊ�ˣ�����ʹ��e��v��R�OV�O\mathrm{\mathbf{\bar e}}_v\in\R^{|V|}e��v?��R�OV�O��f��v��R�OU�O\mathrm{\mathbf{\bar f}}_v\in\R^{|U|}f��v?��R�OU�O��ʾÿ����Ŀv��Vv\in Vv��V��ÿ���û�u��Uu\in Uu��U��һ���ȵ��ʾ��Ȼ������ʹ��������ѵ��Ƕ�����E��R�OV�O��d\mathrm{\mathbf{E}} \in \R^{|V|\times d}E��R�OV�O��d�����Ƿֱ�ת��Ϊ��ά�ܼ�����ev��Rd\mathbf{e}_v\in\R^dev?��Rd��fu��Rd\mathbf{f}_u\in\R^dfu?��Rd��
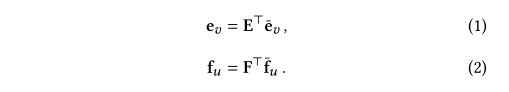
??����ͼ��ͼ��ʾѧϰ����ѧ��ʽ������ͬ����������Գ���ͼGl\mathcal{G}^lGlΪ������˵�������Ǽ���hvl,(0)=ev\mathbf{h}_v^{l,(0)}=\mathbf{e}_vhvl,(0)?=ev?����Ŀ�ڵ�v��Vlv \in \mathcal{V}^lv��Vl�ij�ʼ��ʾ��hul,(0)=fu\mathbf{h}_u^{l,(0)}=\mathbf{f}_uhul,(0)?=fu?���û��ڵ�u��Ulu \in \mathcal{U}^lu��Ul�ij�ʼ��ʾ��Ȼ�����Dz��ó��õ����η�[30]��ͼ�Ͻ��б�ʾ��������һ���Ǿۺ�Ŀ��ڵ�������ʾ������ͼ�������������͵Ľڵ㣬����������ȶ����û��ڵ�ı�ʾ�ۺϷ�ʽ��������ʾ��
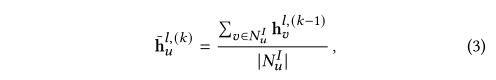
??����NulN_u^lNul?��ʾ�û�uuu����Ŀ����kkk��ʾ�ۺϵĵ�kkk�Ρ����֮�£���ڵ㲻���漰�û�-���Ե�����һ��������Ե���������ˣ������������͵�������Ӧ�ľۺϱ�ʾͨ�����·�ʽ���㣺
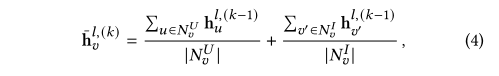
??����NvUN_v^UNvU?��NvIN_v^INvI?�ֱ��ʾ��vvv���û������������ͨ��������ʽ�����ʾͬʱ�ܵ��û������ʾ��Ӱ�졣��ע�⣬���ǻ�������ͼ�еı�ȡ����ֵ������������ĵ�5�����������Dz���һ��ֱ�۵ķ�ʽ�������ı�Ȩ�غϲ����ۺϹ����С�Ȼ����Ŀǰ��ʵ����û�й۲쵽�κθ��ơ�
??��ʾ�����ĵڶ�����ͨ���ۺϱ�ʾ����Ŀ���û������ʾ��
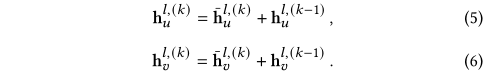
??���Ǽ��贫�����ܴ�����KKK����ˣ���õij����û���ʾ��hul,(K)\mathbf{h}_u^{l,(K)}hul,(K)?��
??���ڹ��������֪�Ķ���ͼGs\mathcal{G}^sGs�����ǿ������Ƶķ�ʽ��ñ�ʾΪhus,(K)\mathbf{h}_u^{s,(K)}hus,(K)?�Ķ����û���ʾ��ֵ��ע����ǣ�����ͼ���û��ڵ�the�ij�ʼ��ʾ����ʼ��Ϊ��������hus,(0)=0\mathbf{h}_u^{s,(0)}=\mathbf 0hus,(0)?=0�������е����ģ���Ϊ�ڸ�ͼ��ѧϰͼ�α�ʾ��Ŀ����Ϊ����Ҫ�������������������Ŀ��ѧϰ�����û���ʾ������������ʼ���������������û���ʾ��Ӱ�졣
4.3 �û���ʾ�ں�
??��ĿǰΪֹ�������г��ںͶ��ڵ��û���ʾ��ʽ���������û���ʾ֮��������һ��������ȫ���ӣ�nFC���㣬�Ը������Ƿḻ�ı������������㶨�����£�
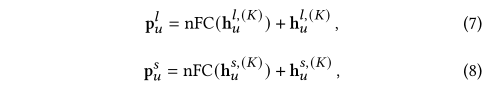
??����nFCʹ��tanh��Ϊ������Լ�������ݾ�[7]���뷨Ҳ��������������ʽ�С�
??��ǰ�����������û�������Ӧ�ڳ���ƫ�ã��������û�������ʾ��̬�ͽ���ƫ�á������ֱ������ศ��ɵģ����ǵ��ںϿ����и�ǿ�ı���������Ϊ�˱�֤����Ӧ�ںϣ����Dz���һ�ּ��ſػ���������ÿ�ֱ�ʾ���Ͷ��ض��û��������Ҫ�ԡ�����ѧ�ϣ���������Ϊ��
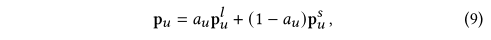
??���У�aua_uau?�DZ���ֵ����ʾ���ڱ�ʾ���γ��ۺ��û���ʾpu\mathbf p_upu?ʱ��ռ�ı��ʣ�����㷽��Ϊ��
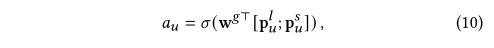
??������\sigma����Sigmoid������wg��R2d\mathbf{w}^g \in \R^{2d}wg��R2d�ǿ�ѵ���IJ���������[������]��ʾ�������㡣
4.2 Ⱥ���ʾѧϰ
??GLS-GRL���ۺ��û������Ļ����ϣ�ͨ�������û�����ע������ѧϰ���Ա֮�����������ԣ�������������ۺϣ��õ��鼶��ı�����
4.4.1 ��Լ�����û�����ע������
??����������ע������[20]�ھ�̬���Ƽ�������ʵ�������Ƚ������ܡ���������������ע�⼼��[21]�����������Ա�ı�ʾ�ļ�Ȩ�������ʾһ���û���ͨ��ע��������õ���ϵ�Ȩ�ء�Ȼ������ע���������һ��������ÿ���û���ע�����������������������Ա�Ͻ��еġ���ܺ�ʱ�����ҿ���û�б�Ҫ����Ϊ��ʵ������£�����ͬһ���е������û�����ֱ�ӽ�������������ֱ�������Ƕ�����ע�⼼�������һ�ּĸĽ�������ÿ��Ŀ���û�����Ҫ�μӵ�Ⱥ���Ա����Ϊ�����û�����ע����ơ�
??������˵������������co?interact(u,u��)co-interact(u,u')co?interact(u,u��)����ʾ��������ʷ��¼���û�uuu��u��u'u����ͬ��������Ŀ����Ȼ������ʹ��NuUN_u^UNuU?����ʾ�����û�uuu������������?u���NuU,co?interact(u,u��)��1.\forall u'\in N_u^U,co-interact(u,u')\geq1.?u����NuU?,co?interact(u,u��)��1.�ڴ˻����ϣ����Ƕ����������û�����ע�����ļ���ϸ�����£�
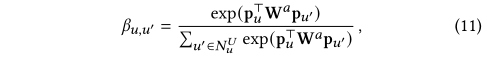
??���У�Ӧ��˫���Է����������û�uuu��u��u'u��֮������ƶȣ�����Wa\mathbf W^aWa�Ǹ÷����Ŀ�ѵ�������ڸ�����ע��Ȩ�ص�����£�ͨ�����·�ʽ������º���û���ʾ��
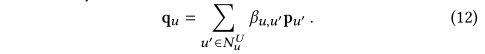
4.4.2 Ⱥ���ʾ�ۺ�
??������Ǿۺϸ��º���û���ʾ���Ի������鼶��ʾ�������о�[20]�����������������û������Ͻ��ж����ע�������㲢����������ܡ���ˣ����Dz��ö������µļ�ֵ�ϲ�������
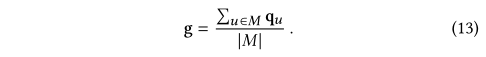
??��ĿǰΪֹ��GLS-GRL����?���䳤�ںͶ���ͼGgl\mathcal G_g^lGgl?��Ggs\mathcal G_g^sGgs?��Ϊ���룬���������ͼ��ʾg����ͼ��ʾg�Ժ����ڼ����ѡ��Ŀ����ƫ�õ÷֡�
4.5 ģ��Ԥ���ѵ��
4.5.1 ģ��Ԥ��
??����һ�����У����Dz�������μ�����鼶���ƫ�÷���sss����ѡ��vvv���Ա������ǵķ�������ʾ����fff(������1���ᵽ)��ȫò��������Ϊ��ѡ��Ŀ?��ƫ�÷�������������ɣ�(1)������Ŀ֮�������ԣ�ͨ���������ƶ���������(2)��Ŀ���ܻ�ӭ�̶ȣ��������ض�Ⱥ�塣Ȼ��ͨ�����·�ʽ�������sss��
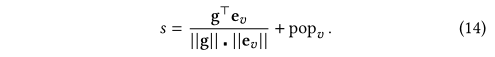
??���У�popv\mathrm{pop}_vpopv?���Կ�������Ŀvvv���ܻ�ӭ�̶�ƫ���������ģ�͵�һ����ѵ��������Ϊ�˽���ѵ�������ǽ���ֵ��ʼ��Ϊ0��
4.5.2 ģ��ѵ��
??�������Ƽ������������һ�ֻ����ʧ����������ʽ������ʧ����ʽ������ʧ��ɡ���������YE?VY^E\subseteq VYE?V����ʾ������Ŀ���Ѿ���Ⱥ��Ա�����˽�������Ŀ����ʹ��YI?VY^I\subseteq VYI?V����ʾÿ����Ŀ��û����Ⱥ�е��κ��û����н����ĸ���Ŀ�����ڴ˻����ϣ����ǽ���ʽ������ʧ��ʽ�������£�
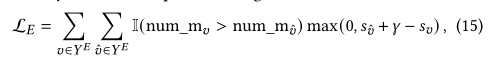
??���У�I(?)\mathbb I(*)I(?)��ָʾ�������������������?������ȡֵΪ1��num_mv\mathrm{num\_m}_vnum_mv?��ʾ����Ŀvvv���������Ա��������\gamma���DZ߾࣬��ʵ��������Ϊ0.1.�����ǽ�һ������������Ⱥ���Ƽ������ձ���õ���ʽ������ʧ��
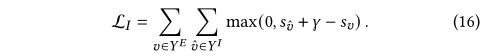
??�������ͨ�����Բ�ֵ����������ʧ��������������õ������ʧ������
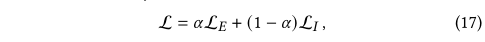
??����aaa�ǿ���ÿ����ʧ�����������Ҫ�Եij�������
5 ʵ��
??�ڱ����У�����ͨ��ʵ��ش������о����⣺
- ����1��GLS-GRL�����е�����Ƽ������������Ƽ������Լ�һЩ��ϵ��������Ƽ�������ȱ�����Σ�
- ����2��GLS-GRL�Ĺؼ�����Ƿ���Ƽ������й��ף��뱸ѡ������ȣ�GLS-GRL�ĺ�������Ƿ��������Ч��
??Ϊ��ʵ����һĿ�꣬����������ȷ��ʵ��װ�ã�Ȼ���ʵ��������������ķ�����
5.1 ʵ������
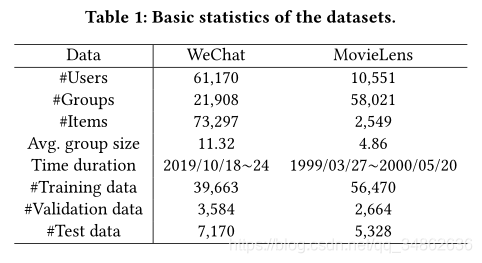
5.1.1 ���ݼ�
??���Dz�����������ʵ��������ݼ����ֱ���Ϊ�ź͵�Ӱ��ͷ�������ݼ��ռ����ŵ�ͷ������(��һ��)���û���������Ź��ںŷ��������¡����Ǵ�����ѡ���˴�Լ2���Ⱥ��������3����Ա���ռ�����Ⱥ��Ա�ĵ����¼��Ϊ��һ�ܡ����ǽ�һ����Ϊ������ݼ���ʱ���ܡ�MovieLens���ݼ��Ǵ�MovieLens 20M����4^44��ȡ�ġ���������13.8�����û���2.7��Ӱ������Լ2000��������ʡ��ڱ����У����Ǽ�������û�����Ӱ���ִ���3�����û���õ�Ӱ�л�����Ϊ��ʹϡ�����ݼ��ʺ���˳���Ƽ��������ռ���60���ڵ��û����ּ�¼������10��Ϊʱ���ܡ��������ݼ���û����ʽ����ṹ��������ѭ[2]��ʹ�õIJ��������ɾ��������û����顣����ͨ��Ƥ��ѷ���ϵ�������û�-�û����ƶȾ���Ȼ�������û��ۺϳ�����ʵ�ֵģ�Ҫ��ÿ�����������û��Ե����ƶȴ���0.27��������ԣ����������˴�Լ60,000��������3����Ա��Ⱥ��
??����ÿ��ʱ���ܣ����ǽ�Ŀ��Ⱥ��Ļ�����ʵ��Ϊ�Ѿ�����������������Ա��������Ŀ�����ǽ��û���������ʷ�еĽ�����¼��Ϊ���ǵij�����Ϊ������ǰʱ�䷶Χ�ڵ��û�������¼��Ϊ������Ϊ����ȷ��������Ϊ���ٸ����ĸ�ʱ�䷶Χ�����ǽ������һ֡�������������Ϊѵ�����ݡ����һ��ʱ��֡��1/3������Ϊ��֤���ݣ�����ȷ�����ų��������ú���ǰֹͣ�����һ��ʱ��֡��ʣ��2/3������Ϊ�������ݣ�����������ͬ���������ܡ����ڹ���ͼ����Ŀͬ�ֹ�ϵ������ѵ�����ݡ��ܶ���֮����1�ܽ������������ݼ��Ļ���ͳ�����ݡ�
5.1.2 ���߷���
??��ʵ���У����Dz����˲�ͬ���Ƽ�������Ϊ��ȷ����ƽ�ıȽϣ�����ʹ���п�ѵ�����߲�����ͬ�ķ������ɷ�ʽ(��ʽ)��14)�ͻ����ʧ����(��ʽ��17)������һ���������������õ�һ��ɶ�������ʧ�����졣�����ʧ����Ч���ں����������֤��
- POP[4]���������һ�֣������ǽ�ѵ�������е�������Ŀ�Ƽ���С�飬��������������Ϣ��
- MF+AVG[20]������ֽ�ѧϰ�û�����Ŀ��ʶ����DZ�����ء������ǵ�ʵ���У�����û�п��õ����ʶ�����������ʹ��ƽ��ֵ
- AGREE[3]�������ڶ����Ա��ע��������������ʶ�����������ƫ��Ƕ�����ۺ����Ա��ƫ�á������ǵ�ʵ���У�����ֻ������-����Ľ�ģ��
- MoSAN[20]������һ�����Ƚ���Ⱥ���Ƽ�ģ�ͣ�������ͨ�����ҹ�ע���ƻ���û�������������Ա��ƫ��Ƕ�룬Ȼ������Ⱥ���Ա��ƫ�û���ΪȺ��ƫ�á�
- GRU4Rec+AVG��GRU4Rec[8]��һ������RNN���������ģ�ͣ����������Ƽ���Ϊ��ʹ�����������Ƽ�������Ӧ�þ�ֵ�ؽ�GRU�����õ�ÿ�����Ա��ʾ�ۺ�Ϊ���ʾ��
- STAMP+AVG��Stamp[12]���û��������Ϊ�ͳ�����Ϊ��ѧϰ�û���ƫ�ã��Ի���û���ʾ�����Ƶأ����ǻ�Ӧ�þ�ֵ�ػ����ۺ�ͨ�����ǻ�õ�ÿ�����Ա��ʾ��Ϊ���ʾ��
- SGR�����ģ��(GRU4Rec+AGREE��STAMP+AGREE��GRU4Rec+MoSAN��STAMP+MoSAN)�� ��Щģ�ͽ�����Ƽ�ģ�ͺͷ����Ƽ�ģ����˵���ѧϰ���ϡ������˵�����ǽ���˳��ģ��(���磬GRU4Rec��STAMP)��õ��û���ʾ���͵����Ƽ�ģ��(���磬AGREE��MoSAN)�Ի�����ʾ��
- SR-GNN��SR-GNN[16]��һ������ͼ�Ļ��ڻỰ���Ƽ�ģ�ͣ�������ͼ����Ŀ��ϵ���б��룬��ͨ����ע�������ûỰ��ʾ�������ǵ�ʵ���У����û�Ƕ��ͻ�õĻỰ��ʾ��Ϊ�û���ʾ�����dz����˲�ͬ�ķ��������Ա�ı�ʾ�ۺ�Ϊ���ʾ����������ѽ����
- NGCF��NGCF[24]ͨ��GNN���û�-��Ŀ����ͼ��ѧϰ�û�����Ŀ��ʾ����SR-GNNһ�������dz����˲�ͬ�ķ������ۺ�Ⱥ��Ա�ı�ʾ��������ѽ����
5.1.3 ����ָ��
??���Dz������ĸ��㷺ʹ�õĶ�����Ϊ�ο����������˵���ʵ���ļ���ϸ�ڡ�ǰ��������������ָ�꣺ƽ��ƽ������(MAP)��һ���ۿ��ۻ�����(NDCG)�����У�MAP����Ϊ��
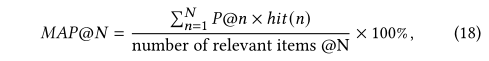
??���У�hit(n)hit(n)hit(n)��ʾ������nnn��λ�õ���Ŀ�Ƿ�Ϊ�棬P@nP@nP@n��top-n�ľ��ȣ�NNN��Ҫ��������Ŀ�Ƽ���������NDCG�����¹�ʽ���㣺
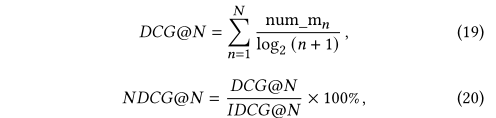
??���У�num_mn\mathrm{num\_m}_nnum_mn?�����m���Ƽ���������Ա����������idcg@N�������?@N��
??��������Ƿ���ָ�꣺��ȫ�ʺ;�ȷ�ȡ����DZ�����Ϊ��
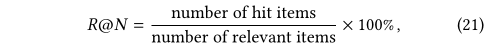
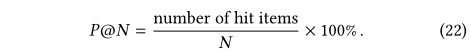
??���ս����ͨ���Բ��Լ�����ƽ���õ��ġ�����ʹ��MAP@10��NDCG@10���Լ�R@3��P@3��������������ع�ע������ǰ�Ĵ𰸵����ܡ�
5.1.4 ʵʩϸ��
??���ǻ���TensorFlowʵ�������ǵ�ģ�ͣ�����ѧϰ��Ϊ1e-4��С����Ϊ64֮�⣬����Ĭ�ϲ������õ�ADAM��ģ�ͽ����Ż�����DZ��������ά������Ϊ64���������ݼ���GNN��ȶ�����Ϊ3�������ݼ�����ʧ������������\alpha������Ϊ0.4����Ӱ��ͷ���ݼ��ij�����Depth����Ϊ0.8������֤���ݵ����������20�����ϱ��ֲ���ʱ������ʹ����ǰֹͣ��������ֹѧϰ���̡�����ÿ��ѵ��ʵ�������������ȡ20����Ŀ��Ϊ��������
5.2 ʵ����
5.2.1 ģ�ͱȽ�(Q1)
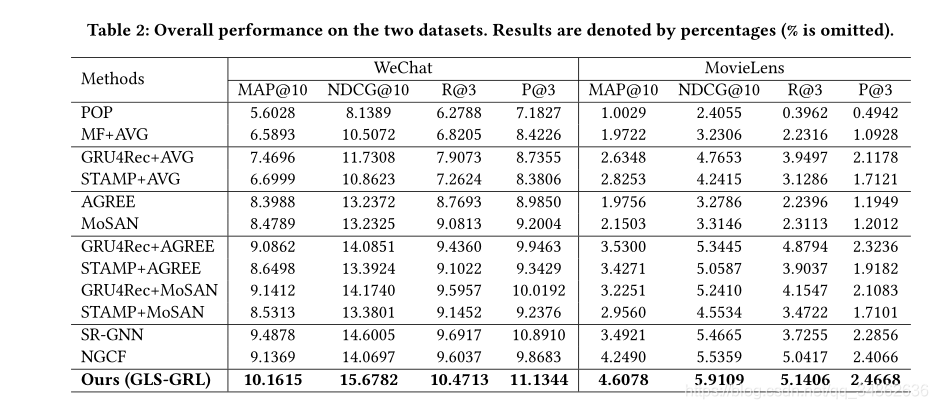
??��2��ʾ�����в��õ�ģ�͵����������������ǿ��Թ۲쵽��
- �����������ݼ������з����У�POP�������������Ⱥ���Ա�ĸ��Ի�ƫ����Ȼ������Ĺؼ���MF+A VG�ı�����������POP����ѷ���������ߡ������������MF��ģ�������ͷ����Խ�ģ����������ޡ�
- GRU4Rec+AVG��STAMP+AVG��MF+AVG�и��õ�Ч����������ʹ���üľۺϲ��ԣ���ǿ��ģ��Ҳ����������ܡ�һ����Ȥ�������ǣ�����������ģ����MovieLens�ϵı��ֺ�������Ⱥ���Ƽ�ģ�ͣ���Agree��MoSAN���������ϵı��ֽϲ���������Ⱥ����Ϊ��������Ϊ���Ƽ�����Ҫ�������ݼ��IJ�ͬ����ͬ��
- ���ģ��(���磬+Agree��+MoSAN)��*+A VGģ�ͳ��ֳ����Ը��õĽ����ԭ�����ڣ����Ƚ�������Ч��Ⱥ�ۺϼ���ȷʵ��SGR��������˺ô������⣬MoSAN��Ϊ����ģ�͵�����Ҫ����Agree������˳���Ƽ�ģ�ͽ��ʹ��ʱ��δ��ʾ���κθĽ��������MoSAN��ʹ�õ�����ע���������Ч�ģ�����Ҫ������Ƶ�˳��ģ�Ͳ��ܻ�ø��õ����ܡ�
- ���ֻ���ͼ���Ƽ�ģ�ͱ������ã�˵��ͼ��������ѧϰ��Ŀ��ϵ���������ߡ������������������GLS-GRLȡ������������ܣ�����Ž��w.r.t��ȣ��ֱ�����7.4%��8.1%����Ը��ơ��ź͵�Ӱ��ͷ�ϵ�ndcg@10��
5.2.2 �����о�(Q2)
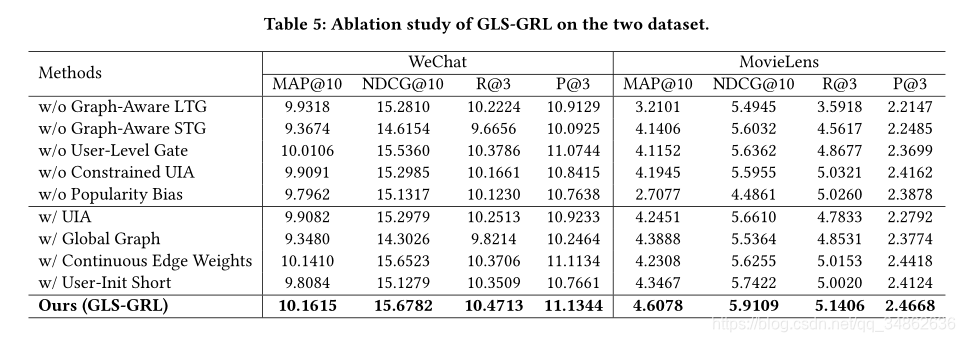
??Ϊ���������GLS-GRL�����ǿ����˸�ģ�͵�������壬���С�w/o����ʾ��GLS-GRL���Ƴ���Ӧ���������w/����ʾ����������滻GLS-GRL��ijЩ������ر�أ����ڵ�һ�飬��w/oͼ��֪LTG���͡�w/oͼ��֪STG���ֱ��ʾ�Ƴ�ͼ��֪�ij���ͼ�Ͷ���ͼ�������û����š�������ʽ9����ʾ��ѡͨ���ơ�������ƽ���ء���w/o Constraated UIA��ɾ����ʽ11��12.����ʾ�ļ��㡣��w/o����ƫ�ɾ����ʽ14.�е���Ŀ�������������ڵڶ��飬��w/UIA����ʾͨ��ɾ���û���Լ����ʹ����MoSAN��ͬ������ע����㡣��w/Global Graph���ð��������û�������ȫ��ͼ�滻�������֪ͼ����W/������ԵȨ�ء���������Ȩ�ض��û�����Ŀ��ʾ���м�Ȩ�ۺϡ����w/User-Init Short����ʾʹ���û�Ƕ������ʼ������ͼ�е��û���ʾ��
??��5��ʾ�˲�ͬ��������ܡ�ͨ�����ȵ�������һ�����еĽ�������������¹۲쵽�Ľ����(1)ɾ������ͼ�����ͼ���ή���Ƽ����ܣ�˵�������ǻ����ġ�(2)ʹ���ſػ��ƽ����ںϣ����Ի�ø��õ��û���ʾ�ͷ��鼶���ʾ��(3)�����û�����ע����Ҳ��������ܲ���ȱ�ٵ����ء�(4)��Ŀ���ܻ�ӭ��ƫ��Լ�Ч�������ף������ǶԵ�Ӱ��ͷ�Ĺ�������ע�⣬�������������п�ѵ�����߶�������������ͬ�ķ������ɷ�ʽ����ȷ���ȽϵĹ�ƽ�ԡ��ڵڶ������У����ǽ�һ���Ƚ��˱����GLS-GRL�Ľ������������Ӧ�Ĺ۲�����(1)ʹ����Լ��������ע�����(��MoSAN��ͬ)�ᵼ�������½�����������û�ע���������м���Լ������Ч�ġ�(2)��ȫ��ͼ�еĹ�ϵ���뵽�û�����Ŀ��ʾ�лᵼ�½ϲ�Ľ�������ǽ��˹�����ȱ����������Ϣ������ѧϰ���Ա�ij����Ļ��ơ�(3)��ͨ����Ȩ�ۺ�������������Ȩ�ز���������㷨�����ܡ�(4)ʹ���û�Ƕ�����������������ʼ�������û���ʾ�ᵼ�������½���ԭ������Ǵ������û���ʾ���õز����˳��ڱ�ʾ��
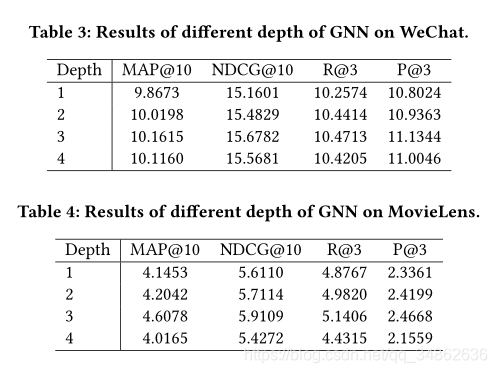
5.2.3 ������K��Ӱ��
??Ϊ������GNN��ȵ�Ӱ�죬������[1��2��3��4]��Χ�ڲ����˲�ͬ�Ĵ���������3�ͱ�4�ֱ���ʾ���������ݼ�����Ӧ��������ǿ��Է��֣�������ȴ�1���ӵ�3�����ܱ�ø��ã����������GNN����ģ��Ʒ���û�֮��ĸ߽�ϵ�����ơ�����һ�����Ӳ���ʱ������û�й۲쵽�κθ��ƣ����ҷ���MoveiLens��Ч���������ܹ����ڸ����Ĺ���ƥ�����⡣
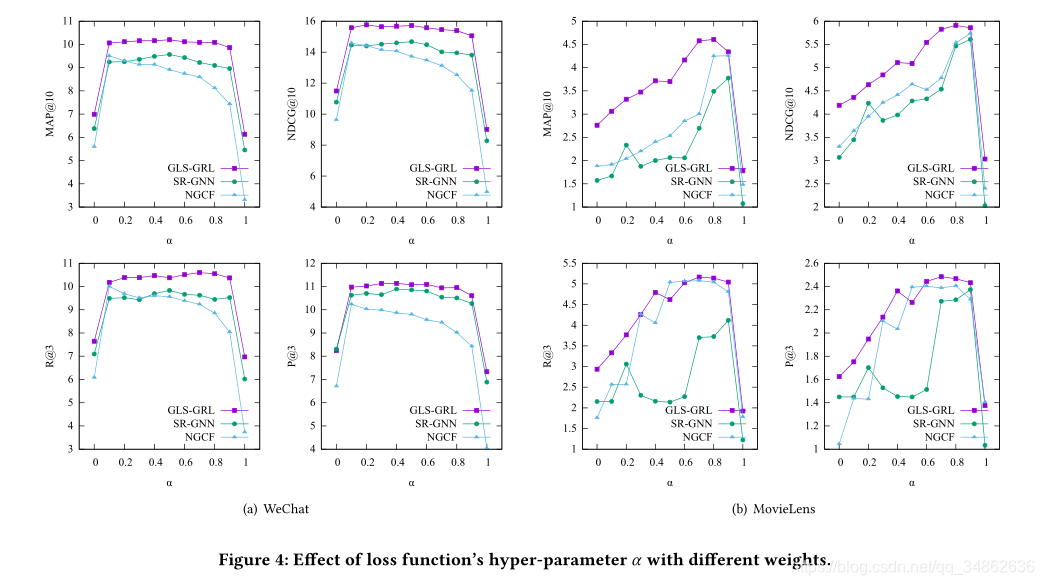
5.2.4 ��\alpha����Ӱ��
??��ͼ4�У����������˻����ĺ�����?�ı仯���Ӱ�������С���˷�������ǿ����(SG-GNN��NGCF)�����ܡ���ߵ�4����ͼ��Ӧ���ŵĽ�����ұߵ�4����ͼ��ʾ�ڵ�Ӱ��ͷ�ϵı��֡����ڵ�?����Ϊ0��1ʱ�����ַ��������ܶ��������½����Ӷ���֤����ʽ����ʽ������ʧ�������ϵĺ����ԡ����⣬����\alpha���Ĵ��������£�GLS-GRL�����ܶ�����SG-GNN��NGCF�����Ż������������SG-GNN��NGCF����������ǵ�ģ���������Ƚ��ġ����⣬�������ݼ��ϵ���ѽ����?��ֵ����仯���Ʋ�����ȫ��ͬ��������������ʧ�������Ҫ��ȡ�����ض����ݼ������ԡ�
6 �ܽ�
??���IJ������������Ƽ���һ��ӱ����Ҫ�����⡣GLS-GRL���������˻���Ⱥ��Ա˳����û�-��Ŀ������ѧϰ��̬Ⱥ��ʾ�ĸ�����ս����ģ�͵���Ҫ����֮�����ڽ�Ⱥ�����ѧϰ�ͳ��ںͶ����û�����ѧϰͳһ��һ������ڡ�����ʵ���ݼ��ϵ�ʵ����֤������ģ�͵���Ч�Լ�����Ҫ��ɲ��ֵĹ��ס�