写在之前
??这是本人的统计学习方法作业之一,老师要求一定要用Matlab编程,本人在此之前未曾大量使用Matlab,因此某些算法可能因为不知道函数或者包而走了弯路。代码高亮查了一下,没找到Matlab的所以用了C的。部分算法参考了某些算法的python算法,如有建议或者错误欢迎指出,谢谢!
数据集
??提供的flower.txt文件为鸢尾花数据集,共分为3类花(前50个样本为一类,中间50个样本为一类,后50个样本为一类,每一朵花包含4个维度的测量值(feature)。现只处理二分类问题,因而只使用前100个数据。其中,每组前40个用作训练,后10个用作测试。因此,该数据集训练样本80个,测试样本20个。
主程序
??首先,在matlab工程新建script文件classification.m,参考代码如下:
classification.m
clear;%% step1: 划分数据集
flower = load('flower.txt');
train_X = [flower(1:40, :);flower(51:90, :)];
train_Y = [ones(40, 1); zeros(40, 1)];
test_X = [flower(41:50, :);flower(91:end, :)];
test_Y = [ones(10, 1); zeros(10, 1)];%% step2:学习和预测,预测test_y
output_perceptron = perceptron(train_X, train_Y, test_X);%因为随机取起点,所以每次运行分类结果不一定一样
output_knn = knn(train_X, train_Y, test_X); %简单测试,k取9效果比较好
output_logistic = logistic(train_X, train_Y, test_X);
output_entropy = entropy(train_X, train_Y, test_X);
output_tree = tree(train_X, train_Y, test_X);
output_nb = nb(train_X, train_Y, test_X); %数据集为连续型数据,需用高斯贝叶斯分类器%% step3:分析结果,准确率召回率等
output_set = [output_perceptron;output_knn;output_logistic;output_entropy;output_tree;output_nb];
compare(test_Y,output_set);
function compare(test_Y,output)result = [];for i = 1:length(output(:,1))[ACC,PRE,REC] = evaluation(test_Y,output(i,:));result = [result;[ACC,PRE,REC]];endbar(result);grid on;legend('ACC','PRE','REC');set(gca,'XTickLabel',{
'perceptron','knn','logistic','entropy','tree','nb'});xlabel('分类器种类');ylabel('指标值');
end
function [ACC,PRE,REC] = evaluation(test_Y,output) %评估分类性能,ACC分类准确率、PRE精确率、REC召回率TP = 0;FN = 0;FP = 0;TN = 0;for i = 1:length(test_Y)if test_Y(i)==1if output(i)==1TP = TP + 1;%将正类预测为正类数elseFN = FN + 1;%将正类预测为负类数endelseif output(i)==1FP = FP + 1;%将负类预测为正类数elseTN = TN + 1;%将负类预测为负类数endendendACC = (TP+TN)/(TP+FN+FP+TN);PRE = TP/(TP+FP);REC = TP/(TP+FN);
end子程序
??第二步:分别新建6个函数,perceptron,knn,logistic,entropy,tree,nb,实现相应7个分类器,将代码分别复制到以下对应文本框内。每个分类器的输入只有训练集和测试集的X,其返回结果为测试集的y(一个向量)。
perceptron.m
function [ test_Y ] = perceptron( X, Y, test_X )
%% 初始化w,b,alpha,
w = [0,0,0,0];
b = 0;
alpha = 1; % learning rate
sample = X;
for i = 1:length(Y)if Y(i)==1sign(i) = 1;elsesign(i) = -1;end
end
sign = sign';
maxstep = 1000;
%% 更新 w,b
for i=1:maxstep[idx_misclass, counter] = class(sample, sign, w, b);%等式右边为输入,左边为输出,理解为函数调用%obj_struct = class(struct_array,'class_name',parent_array) %idx_misclass:误分类序号索引,counter:if (counter~=0)%~=代表不等于R = unidrnd(counter);%产生离散均匀随机整数(一个),即随机选取起点训练%fprintf('%d\n',R);w = w + alpha * sample(idx_misclass(R),:) * sign(idx_misclass(R));b = b + alpha * sign(idx_misclass(R)); elsebreakend
end
%%
for i=1:length(test_X)if(w*test_X(i,:)'+b >=0)test_Y(i) = 1;elsetest_Y(i) = 0;end
end
endfunction [idx_misclass, counter] = class(sample, label, w, b)counter = 0;idx_misclass = [];for i=1:length(label)if (label(i)*(w*sample(i,:)'+b)<=0) %如果有误分类点,进行迭代idx_misclass = [idx_misclass i];%fprintf('%d\n',idx_misclass);counter = counter + 1; end end
endknn.m
function [ test_Y ] = knn( X, Y, test_X )
k = 7;for i = 1:length(test_X)for j = 1:length(X)dist(i,j) = norm(test_X(i)-X(j));end[B,idx] = mink(dist(i,:),k);result(i,:) = Y(idx);endfor i = 1:length(test_X)if(sum(result(i,:))>=k/2)test_Y(i) = 1;elsetest_Y(i) = 0;endend
endlogistic.m
function [J, grad] = costFunction(theta, X, Y, lambda)m = length(Y);grad = zeros(size(theta));J = 1 / m * sum( -Y .* log(sigmoid(X * theta)) - (1 - Y) .* log(1 - sigmoid(X * theta)) ) + lambda / (2 * m) * sum( theta(2 : size(theta), :) .^ 2 );for j = 1 : size(theta)if j == 1grad(j) = 1 / m * sum( (sigmoid(X * theta) - Y)' * X(:, j) );elsegrad(j) = 1 / m * sum( (sigmoid(X * theta) - Y)' * X(:, j) ) + lambda / m * theta(j);endendendfunction g = sigmoid(z)g = zeros(size(z));g = 1 ./ (1 + exp(-z));
endentropy.m
function [ test_Y ] = entropy( X, Y, test_X )%% 变量定义maxstep=10;w = [];labels = []; %类别的种类fea_list = []; %特征集合px = containers.Map(); %经验边缘分布概率pxy = containers.Map(); %经验联合分布概率,由于特征函数为取值为0,1的二值函数,所以等同于特征的经验期望值exp_fea = containers.Map(); %每个特征在数据集上的期望 N = 0; % 样本总量M =0; % 某个训练样本包含特征的总数,这里假设每个样本的M值相同,即M为常数。其倒数类似于学习率n_fea = 0; % 特征函数的总数fit(X,Y);test_Y = [];for q = 1:length(test_X) %测试集预测p_Y = predict(test_X(q));test_Y = [test_Y,p_Y];end%% 变量初始化function init_param(X,Y)N = length(X);labels = unique(Y);%初始化px pxyfor i = 1:length(X)px(num2str(X(i,:))) = 0;pxy(num2str([X(i,:),Y(i)])) = 0;end%初始化exp_feafor i = 1:length(X)for j = 1:length(X(i,:))fea = [j,X(i,j),Y(i)];exp_fea(num2str(fea)) = 0;endendfea_func(X,Y);n_fea = length(fea_list);w = zeros(n_fea,1);f_exp_fea(X,Y); end%% 构造特征函数function fea_func(X,Y)for i = 1:length(X)px(num2str(X(i,:))) = px(num2str(X(i,:))) + 1.0/double(N);pxy(num2str([X(i,:),Y(i)])) = pxy(num2str([X(i,:),Y(i)]))+ 1.0/double(N);for j = 1:length(X(1,:))key = [j,X(i,j),Y(i)];fea_list = [fea_list;key];endendfea_list = unique(fea_list,'rows');M = length(X(i,:));endfunction f_exp_fea(X,Y)for i = 1:length(X)for j = 1:length(X(i,:))fea = [j,X(i,j),Y(i)];exp_fea(num2str(fea)) = exp_fea(num2str(fea)) + pxy(num2str([X(i,:),Y(i)]));endendend%% 当前w下的条件分布概率,输入向量X和y的条件概率function py_X =f_py_X(X)py_X = containers.Map();for i = 1:length(labels)py_X(num2str(labels(i))) = 0.0;endfor i = 1:length(labels)s = 0;for j = 1:length(X)tmp_fea = [j,X(j),labels(i)];if(ismember(tmp_fea,fea_list,'rows'))s = s + w(ismember(tmp_fea,fea_list,'rows'));endendpy_X(num2str(labels(i))) = exp(s);endnormalizer = 0;k_names = py_X.keys();for i = 1:py_X.Countnormalizer = normalizer + py_X(char(k_names(i)));endfor i = 1:py_X.Countpy_X(char(k_names(i))) = double(py_X(char(k_names(i))))/double(normalizer);endend%% 基于当前模型,获取每个特征估计期望function est_fea = f_est_fea(X,Y)est_fea = containers.Map();for i = 1:length(X)for j = 1:length(X(i,:))est_fea(num2str([j,X(i,j),Y(i)])) = 0;endendfor i = 1:length(X)py_x = f_py_X(X);py_x = py_x(num2str(Y(i)));for j = 1:length(X(i,:))est_fea(num2str([j,X(i,j),Y(i)])) = est_fea(num2str([j,X(i,j),Y(i)])) + px(num2str(X(i,:)))*py_x;endendend%% GIS算法更新deltafunction delta = GIS()est_fea = f_est_fea(X,Y);delta = zeros(n_fea,1);for i = 1:n_featrydelta(i) = 1 / double(M*log(exp_fea(num2str(fea_list(i,:)))))/double(est_fea(num2str(fea_list(i,:))));catchcontinue;endenddelta = double(delta) / double(sum(delta));end%% 训练,迭代更新wifunction fit(X,Y)init_param(X,Y);i = 0;while( i < maxstep)i = i + 1;delta = GIS();w = w + delta;endend%% 输入x(数组),返回条件概率最大的标签function best_label = predict(X)py_x = f_py_X(X);keys = py_x.keys();values = py_x.values();max = 0;best_label = -1;for i = 1:py_x.Countif(py_x(char(keys(i))) > max)max = py_x(char(keys(i)));best_label = str2num(char(keys(i)));endendend
end
tree.m
function [ test_Y ] = tree( X, Y, test_X )global tree;tree = [];disp("The Tree is :");build_tree(X,Y);
% disp(tree);S = regexp(tree, '\s+', 'split');test_Y = [];var = 0;condi = 0;for i = 1:length(test_X)tx = test_X(i,:);for j=1:length(S)if contains(S(j),'node')var = tx(str2num(char(S(j+1))));condi = str2num(char(S(j+2)));if var < condiif contains(S(j+3),'leaf')ty = char(S((j+3)));ty = ty(6);test_Y = [test_Y,str2num(ty)];breakelsej = j + 3;endelseif contains(S(j+4),'leaf')ty = char(S((j+4)));ty = ty(6);test_Y = [test_Y,str2num(ty)];breakelsej = j + 4;endendendendend
endfunction build_tree(x, y, L, level, parent_y, sig, p_value)% 自编的用于构建决策树的简单程序,适用于属性为二元属性,二分类情况。(也可对程序进行修改以适用连续属性)。% 输入:% x:数值矩阵,样本属性记录(每一行为一个样本)% y:数值向量,样本对应的labels% 其它参数调用时可以忽略,在递归时起作用。% 输出:打印决策树。global tree;if nargin == 2level = 0; parent_y = -1;L = 1:size(x, 2);sig = -1;p_value = [];
% bin_f = zeros(size(x, 2), 1);
% for k=1:size(x, 2)
% if length(unique(x(:,k))) == 2
% bin_f(k) = 1;
% end
% endendclass = [0, 1];[r, label] = is_leaf(x, y, parent_y); % 判断是否是叶子节点if r if sig ==-1disp([repmat(' ', 1, level), 'leaf (', num2str(label), ')'])tree = [tree,[' leaf(', num2str(label), ')']];elseif sig ==0disp([repmat(' ', 1, level), '<', num2str(p_value),' leaf (', num2str(label), ')']);tree = [tree,[' leaf(', num2str(label), ')']];elsedisp([repmat(' ', 1, level), '>', num2str(p_value),' leaf (', num2str(label), ')']);tree = [tree,[' leaf(', num2str(label), ')']];endelse[ind, value, i_] = find_best_test(x, y, L); % 找出最佳的测试值
%
% if ind ==1
% keyboard;
% end[x1, y1, x2, y2] = split_(x, y, i_, value); % 实施划分if sig ==-1disp([repmat(' ', 1, level), 'node (', num2str(ind), ', ', num2str(value), ')']);tree = [tree,[' node ', num2str(ind), ' ',num2str(value)]];elseif sig ==0disp([repmat(' ', 1, level), '<', num2str(p_value),' node (', num2str(ind), ', ', num2str(value), ')']);tree = [tree,[' node ',num2str(ind), ' ', num2str(value)]];elsedisp([repmat(' ', 1, level), '>', num2str(p_value),' node (', num2str(ind), ', ', num2str(value), ')']);tree = [tree,[' node ',num2str(ind), ' ', num2str(value)]];end
% if bin_f(i_) == 1x1(:,i_) = []; x2(:,i_) = [];L(:,i_) = [];
% bin_f(i_) = [];
% endbuild_tree(x1, y1, L, level+1, y, 0, value); % 递归调用build_tree(x2, y2, L, level+1, y, 1, value);endfunction [ind, value, i_] = find_best_test(xx, yy, LL) % 子函数:找出最佳测试值(可以对连续属性适用)imp_min = inf;i_ = 1;ind = LL(i_);for i=1:size(xx,2);if length(unique(xx(:,i))) ==1continue;end
% [xx_sorted, ii] = sortrows(xx, i);
% yy_sorted = yy(ii, :);vv = unique(xx(:,i));imp_min_i = inf;best_point = mean([vv(1), vv(2)]);value = best_point;for j = 1:length(vv)-1point = mean([vv(j), vv(j+1)]); [xx1, yy1, xx2, yy2] = split_(xx, yy, i, point);imp = calc_imp(yy1, yy2);if imp<imp_min_ibest_point = point;imp_min_i = imp;endendif imp_min_i < imp_minvalue = best_point;imp_min = imp_min_i;i_ = i;ind = LL(i_);endendendfunction imp = calc_imp(y1, y2) % 子函数:计算熵p11 = sum(y1==class(1))/length(y1);p12 = sum(y1==class(2))/length(y1);p21 = sum(y2==class(1))/length(y2);p22 = sum(y2==class(2))/length(y2);if p11==0t11 = 0;elset11 = p11*log2(p11); endif p12==0t12 = 0;elset12 = p12*log2(p12); endif p21==0t21 = 0;elset21 = p21*log2(p21); endif p22==0t22 = 0;elset22 = p22*log2(p22); endimp = -t11-t12-t21-t22;endfunction [x1, y1, x2, y2] = split_(x, y, i, point) % 子函数:实施划分index = (x(:,i)<point);x1 = x(index,:);y1 = y(index,:);x2 = x(~index,:);y2 = y(~index,:);endfunction [r, label] = is_leaf(xx, yy, parent_yy) % 子函数:判断是否是叶子节点if isempty(xx)r = true;label = mode(parent_yy);elseif length(unique(yy)) == 1r = true;label = unique(yy);elset = xx - repmat(xx(1,:),size(xx, 1), 1);if all(all(t ==0))r = true;label = mode(yy);elser = false;label = [];endendend
end
nb.m
function [ test_Y ] = nb( X, Y, test_X )%% 计算每个分类的样本的概率labelProbability = tabulate(Y);%P_yi,计算P(yi)P_y1=labelProbability(1,3)/100;P_y2=labelProbability(2,3)/100;%% 计算每个属性(列)的均值与方差X1 = [];X2 = [];for i = 1:length(X)if(Y(i)==1)X1 = [X1;X(i,:)];elseX2 = [X2;X(i,:)];endend%% 计算每个类的均值和方差x1_mean = mean(X1,1);x1_std = std(X1,0,1);x2_mean = mean(X2,1);x2_std = std(X2,0,1);test_Y = [];for i = 1:length(test_X)p1 = 1; %归属第一个类的概率p2 = 1; %归属第二个类的概率for j = 1:length(test_X(1,:))p1 = p1 * gaussian(test_X(i,j),x1_mean(j),x1_std(j)); %p(xj|y)p2 = p2 * gaussian(test_X(i,j),x2_mean(j),x2_std(j));endp1 = p1 * P_y1;p2 = p2 * P_y2;if(p1>p2)test_Y = [test_Y,1];elsetest_Y = [test_Y,0];endend%% 定义高斯(正太)分布函数function p = gaussian(x,mean,std)p = 1/sqrt(2*pi*std*std)*exp(-(x-mean)*(x-mean)/(2*std));end
end
结果分析
??运行classification.m脚本,将所得到的6个分类器的结果与真实test_Y进行比较,对各分类器的结果进行简单分析比较。
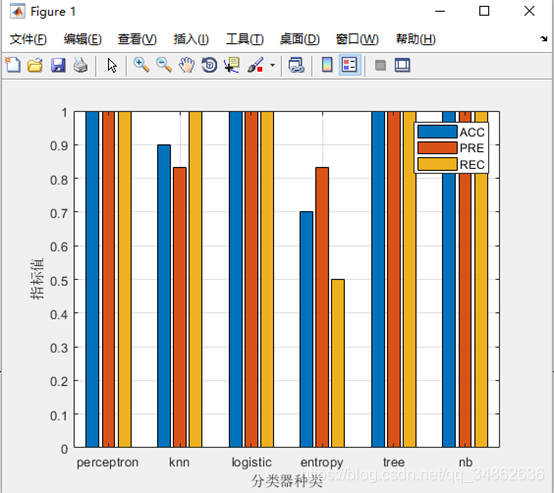
??运行结果为每个类的预测标签,通过测试集真实标签对比,构造处混淆矩阵,可以计算得到分类准确率ACC、分类精确率PRE、分类召回率REC,以其作为评价指标可绘制柱形图对比,结果如下图所示,具体代码见classification.m 的step3。
??从分类结果上来看,感知机、罗吉斯特回归、决策树、朴素贝叶斯的表现最好,全部指标都达到了满值,一方面是这些分类器分类效果比较好,另一方面也由于训练样本不足而导致。分类效果一般的是KNN,这是由K的取值而导致的不稳定分类,分类效果最差的是最大熵,原因可能因为训练集数据是连续的,而实现最大熵的时候将每一条数据当成离散的特征函数,导致分类效果不佳。值得一提的是,朴素贝叶斯最开始实现的时候也会存在这个问题,但朴素贝叶斯处理连续数据时可做正态分布假设,实现时使用高斯朴素贝叶斯,其结果表现良好。