用于在GPU上实时的目标跟踪新方法,入选ECCV2020
官方代码
我认为论文有如下特点:
- 相对于simaMask这种孪生网络,作者进行full-frame matching。不在上一帧预测位置expand一个box作为search image。直接用原图作为search的对象。
- 因为没了时间smooth假设,没法在目标邻域截取search image。为了解决在原图存在很多相似目标的情况,作者提出tridentAlign方法,考虑到多尺度,更好的表达时序上的目标尺度变化。
- 使用full-frame search,可以处理目标消失,重新出现的问题
- 设计了context generator和embeder。使用2阶段算法实现目标跟踪。
前言
目标跟踪目前被孪生网络所统治。这类方法一般有这样的假设:
- 目标是连续平滑运动,尺度也是平滑变化的
因此siam系列往往都要crop框。在上一帧预测的结果为中心,expand出一个更大的框作为search对象。这样做有两个目的:
- 减少FLOPS,因为输入图像小了
- 减小其他目标的干扰,尤其是具有相同语义类别的目标
这样的特性有好处,也有坏处:不能解决目标消失又重新出现的问题(位置不平滑变化)。只有full-frame的search才能解决这个问题。但full-frame则会受到其他目标的干扰。TACT用两个办法解决该问题:
- tridentAlign:更好表征目标以及尺度变化
- context embed module: 将关注的目标从一众具有干扰性的背景目标中分离。避免得到假阳性结果
method
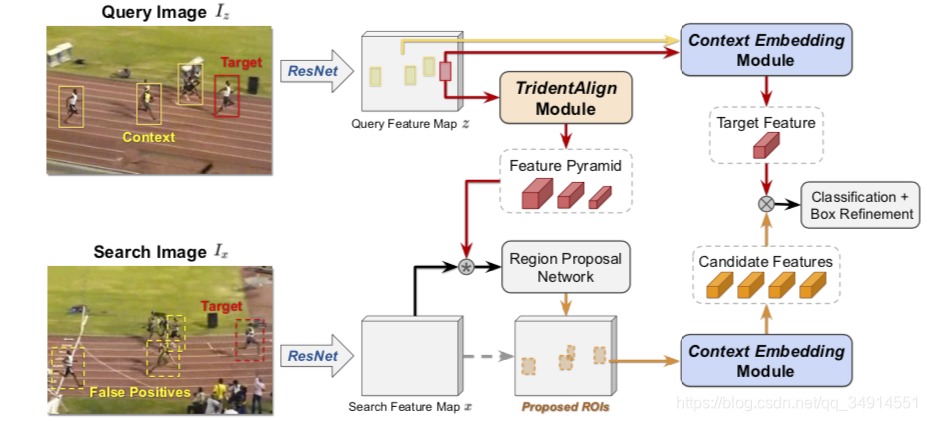
第一阶段:得到候选框。query根据给定的box,经过tridentAlign得到模板金字塔特征。然后用金字塔特征去和当前帧特征学习相似图(corr操作),得到的相似图进入RPN,得到一系列的候选框。
第二阶段:得到的候选框继续ROI align,得到一系列的特征,这些特征可能属于干扰目标,要继续做分类。此时依然使用模板特征通过context embedding得到的特征作为参考。从而得到true positive预测。
第一阶段
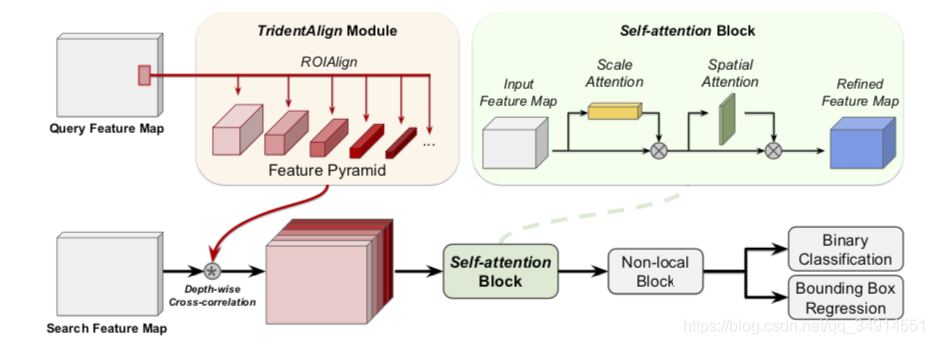
第一阶段很常规。self-attention block其实是CBMA block。先执行通道注意力,在执行空间注意力
第二阶段
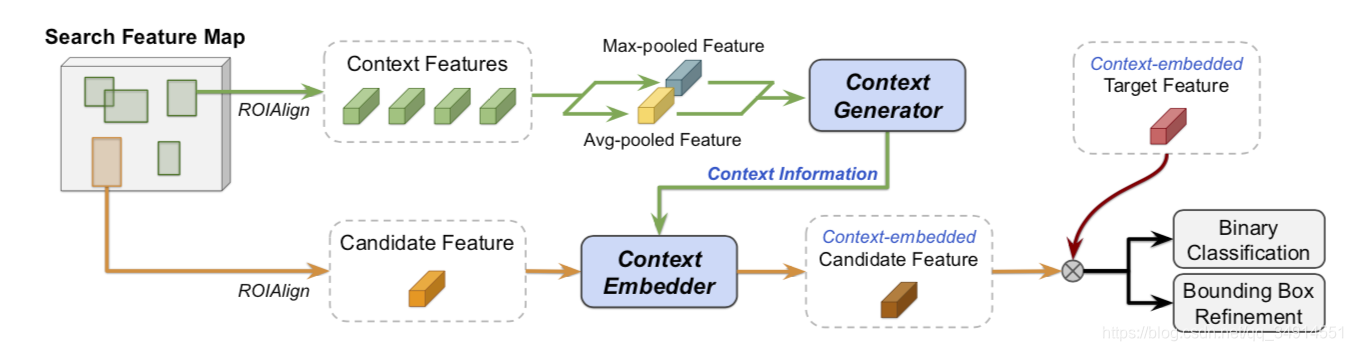
假设上一帧得到的目标候选框,通过ROI align得到的特征集合为X
X={x1,x2,...xN}X = \{x_1, x_2, ... x_N \}X={
x1?,x2?,...xN?}
一共有N个候选框。这N个候选框中,只有一个是我们想要的,其他都是假阳性预测。
首先X中的所有特征会经过 element-wise maximum 和aver- aging operations得到Max-pooled feature 和 Avg-pooled feature。这两个feature经过context generator得到context information。接着X中的每个xix_ixi?,会和context information一起进入context embedder得到xi~\widetilde{x_i}xi?
?s。
xi~\widetilde{x_i}xi? ? 会和context-embeded target feature计算element-wise 乘,然后再分类和回归。
context-embeded target feature是将第一帧作为新的一帧,走一边上述过程得到的。
整体的pipeline

Note:
TACT因为是full-frame search,不受时序限制,所以在推理的时候,可以把一个序列的其他帧组成batch,从而加快推理速度
细节
iou阈值等。


训练batch为4个pair。每个pair就是(query,search),随机采。
代码剖析
作者开源了测试代码
给定一个序列,用第一帧的状态初始化跟踪器。
if i == 0:xfa = self.net.get_feats_xfa(net_im, net_bb)
get_feats_xfa的目的是得到第一帧的用于匹配的金字塔特征“xfa_tri”,和z0z_0z0? “xfa_pos”,
net_out_bb, _, _ = self.net.forward_box(None,net_im, None, xfa=xfa, nbox=1)
forward_box得到当前帧的目标框。
主要含有3部分结构。
bb_ch = self.backbone(torch.zeros(1,3,64,64)).shape[1]# rpn module for proposal generationself.rpn = RPN_Module(cfg, bb_ch)# rcnn module for matching and refinementself.rcnn = RCNN_Module(cfg)
最复杂的就是RPN。含有CBMA,FCOSHead, BOXNMS, ContextModule(第一帧和后续帧使用参数不同的contextModule)
self.cbamod = CBAModule(self.head_nfeat*fmul)self.conv_x = nn.Conv2d(self.bb_ch, cfg.head_nfeat, 1) # 256self.conv_y = nn.Conv2d(self.bb_ch, cfg.head_nfeat, 1)# detection headself.roi_head = FCOSHead(cfg)# nms box predictionsself.boxes = BoxModule(cfg)# context moduleself.context_x = ContextModule(cfg) if self.head_ctxff[0] else None # 用于第一帧self.context_y = ContextModule(cfg) if self.head_ctxff[0] else None # 用于后续帧
RCNN中的BOX refine。
boxes_w = boxes[...,2] - boxes[...,0]boxes_h = boxes[...,3] - boxes[...,1]boxes_xc = boxes[...,0] + boxes_w*0.5boxes_yc = boxes[...,1] + boxes_h*0.5# modify accto regression outputsboxes_xc_m = boxes_xc + boxes_w * re[...,0]boxes_yc_m = boxes_yc + boxes_h * re[...,1]boxes_w_m = boxes_w * torch.exp(re[...,2])boxes_h_m = boxes_h * torch.exp(re[...,3])# revert cooridatesboxes_x0 = (boxes_xc_m - boxes_w_m*0.5).unsqueeze(-1)boxes_x1 = (boxes_xc_m + boxes_w_m*0.5).unsqueeze(-1)boxes_y0 = (boxes_yc_m - boxes_h_m*0.5).unsqueeze(-1)boxes_y1 = (boxes_yc_m + boxes_h_m*0.5).unsqueeze(-1)
总体来说,代码挺清晰的