NeurPIS2020������
�ٷ�����
�����Ŀ�ܲ���STM���������������Ӧ����memory bank��һ����ӱ��refinement������
Motivation
STM��Ŀǰ��ලVOS�����SOTA���ķ�����������������Ķ�����STM�Ļ����ϸĽ���
���߷�����STM��ȱ�㣺
- �ڲ��Ե�ʱ��ÿ5֡����һ��memory������dz����У�memory bank���ܻᱬ�Դ档
- ÿ����֡������һ��memory bank�����ܻ�©��һЩ�ؼ�֡
�������Adaptive feature bank(AFB)������Ӧ����bank�������µ�����������ͬʱ�������Ҫ�����ų�һЩ��������memory bank������������һ������֮�¡�
ͬʱ���Ŀ���Ե�ķָĿ���Ե���ѷ���������Ҳ�Dz�ȷ�������������uncertain-region refinement��URR����������Ե�ָ�������
����
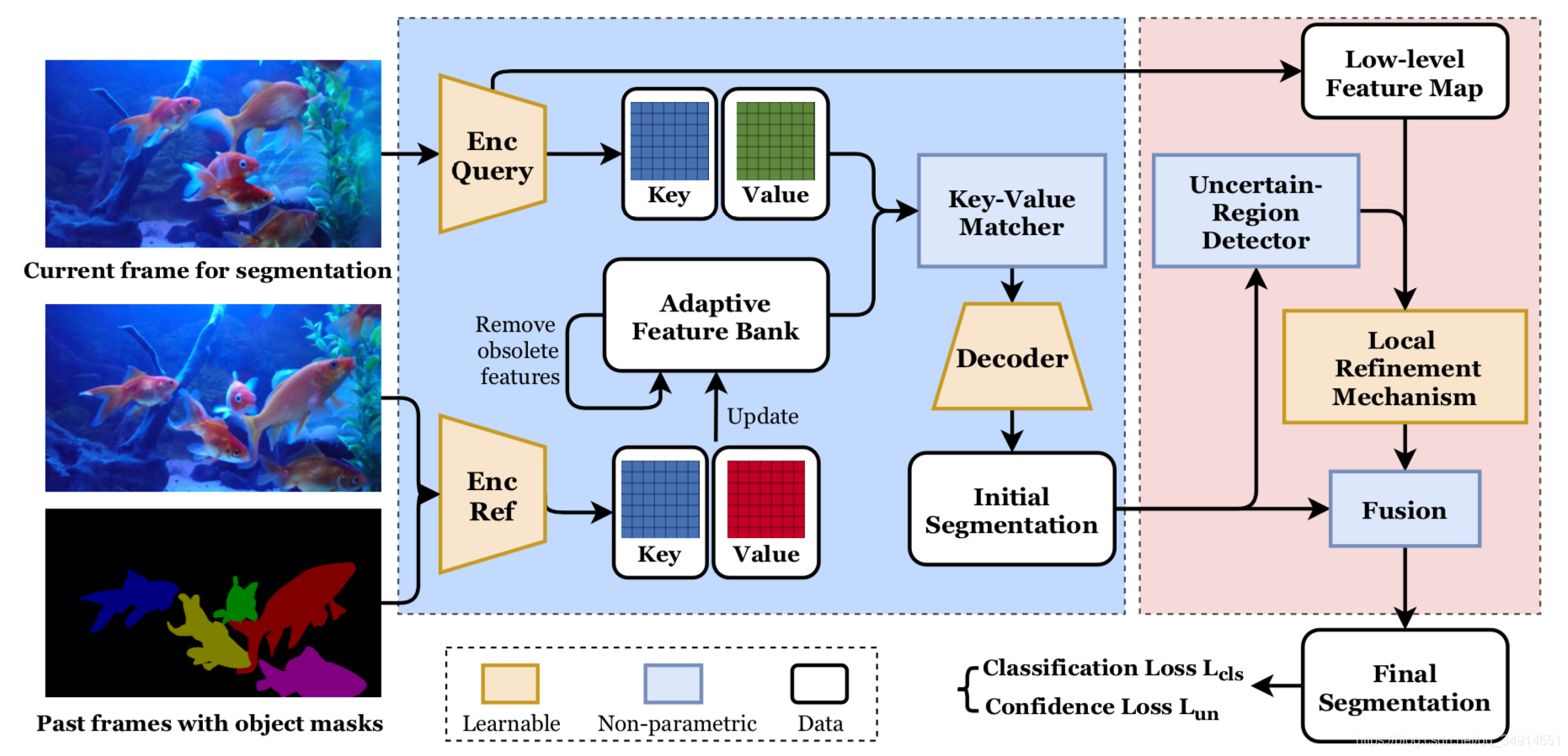
�ӿ���Ͽ������Կ�����һ�����ε�vos������
- ��һ�Σ�����STM���Adaptive Feature bank�õ�initial segmentation��
- �ڶ��Σ����ò�ȷ�������� ��local refinement module�õ�����ϸ���Ľ����
Լ��һЩ���ţ�
- LLL��Ŀ����Ŀ��davis17�Ƕ�Ŀ�����ݼ�������������û����ȷʵ����������
- FBFBFB: feature bank������value ��key�� FB={(kl,vl)�Ol=0,1,2,...L?1}FB=\{(k_l, v_l) | l = 0,1,2,...L-1\}FB={ (kl?,vl?)�Ol=0,1,2,...L?1}��Ҳ����˵ÿһ��Ŀ�궼��һ��(key,value)
- query����Q���ǵ�ǰ֡
- kQ,vQk^Q, v^QkQ,vQ: �ӵ�ǰ֡����ȡ����key��value
Pipeline������Ե�i��Ŀ����зָ
- kQk^QkQ��feature bank�е�FBiFB_iFBi?��attention transform����һ����STMһ����
- Ȼ����STMһ����Decoder���õ�initial segmentation��
- ʹ��Uncertain-Regions Refinement�Խ������ϸ����
- ��Ԥ����mask�͵�ǰ֡������feature bank���£�Ȼ��Ϳ�����һ֡Ԥ����
�������������STM�����������ģ���һ����Uncertain-Regions Refinement���ڶ��������������Ӧ����feature bank��
Uncertain-Regions Refinement
���ģ��������ߣ�
- �ȵõ�confience loss���Ͳ�ȷ�������mask
- ���ݲ�ȷ�������mask���ֲ�ϸ��
confidence loss
��һ�εõ��������һ��shape��(LLL, h, w)������������softmax֮�õ�ÿ�����ص�����ÿ��Ŀ��ĸ��ʣ�����M��
��ȷ�������maskͨ�����·�ʽ��ã�
U=exp(1?M1��M2��)U = exp(1-\frac{M'_1}{M'_2})U=exp(1?M2��?M1��??)
M1��M'_1M1��?��M2��M'_2M2��?��ÿ������λ�����ĸ���ֵ�͵ڶ���ĸ���ֵ��ɵ�����mask��U��ֵ��Χ�ڣ�0��1]��
Խ�ӽ�0������M1��M'_1M1��?��ֵԶ����M2��M'_2M2��?��˵�������ȷ��������ص�����Ŀ�ꡣ
Lconf=�O�OU�O�O2L_{conf} = ||U||_2Lconf?=�O�OU�O�O2?
��U��2������Ϊloss����U��ֵ����������0���Ż����������ÿ�����ص㶼ȷ���Լ������

��ͼ��ɫȦ�еİ�ɫ�����Dz�ȷ�������Է��ֶ������ڱ�Ե��
local refinement mechanism
���U�����ֵIJ�ȷ������ʹ�� local refinement mechanism��refine��
������Ϊ��һ����ȷ����p�����Ӧ�ÿ��Դ�p����Χ�ĵ��������ƶϡ�����˵���������ĸ�Ŀ�����˼��
����Ҫ���һ���ֲ���������res1�����͵�һ��Ԥ���mask���˷���
rough_seg = rough_seg.view(bs * obj_n, 1, h, w) # bs*obj_n, 1, h, wr1_weighted = r1 * rough_seg # �õ�reference feature
Ȼ��������7*7�ķ�Χ����ƽ�����õ�local feature
r1_local = self.local_avg(r1_weighted) # bs*obj_n, 64, h, w # 7*7������
Ȼ��ϣ�����ֵ��ϵ�����Ǿ��ֵģ�����������Χ�ĸ���ֵ������
r1_local = r1_local / (self.local_avg(rough_seg) + 1e-8) # neighborhood reference
��ʵ���������������ʽ
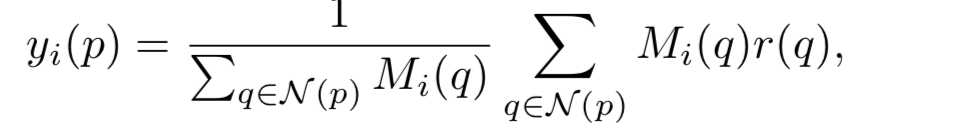
Ȼ��Ҫѧϰres1��r1_local�����ƶȣ�
r1_conf = self.local_max(rough_seg) # bs*obj_n, 1, h, w
local_match = torch.cat([r1, r1_local], dim=1)
q = self.local_ResMM(self.local_convFM(local_match))
q = r1_conf * self.local_pred2(NF.relu(q))
�ȼ�������ʽ
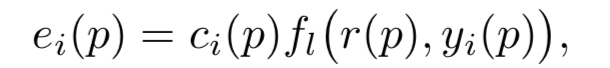
�������refine��һ��Ԥ���logits
p = p + uncertainty * q # ��P+��p��û�о���softmax������ֵ ���Ǹ���ֵ
p = NF.interpolate(p, scale_factor=2, mode='bilinear', align_corners=False) # ԭͼ��С
p = NF.softmax(p, dim=1)[:, 1] # no, h, w �൱��sigmoid
֮����һ��soft aggregation ��softmax��
Adaptive feature bank(AFB)
AFBҲ���������裺
- ������������ Absorbing new features
- ɾ������������ Removing obsolete features
Note����ͬĿ���в�ͬ��Bank���ڵ�һ֡��ʱ���ʼ������һ֡����Ԥ�⡣����ֻ�ڲ��Ե�ʱ���á�
����������
����������;��������������ֱ��merge�ˡ�ʡ�˿ռ䣬���testЧ��
�ںϵĹ���Ҳ�ܱ���������������������Ҿ������0.95����ֱ��ʹ�û���ƽ���ںϡ����С��0.95����ֱ�����ӽ�ȥ��

ɾ����������
˼�룺 ���feature bank�е������ܾ�û�б�read out��������Ҳû�б�Ҫ�������ˡ�
ʲô��read out������ʹ�á��������matching�Ĺ����С�Feature bank�ĵ�j��������query�ĵ�i��������dot product����1e-4���Ե�j�������ļ���+1�� û����feature bank��ÿ����������Ӧ��һ��counter��time span counter��ǰ��¼��readout �Ĵ���������¼���������Խ��ʱ��֡����
ʹ��LFU����������Ҫ�̶ȣ����һ��FB�е������ܾ�û��ʹ���ˣ�readout�Ĵ������٣���ʱ���Ⱥܴ���LFUֵ��С
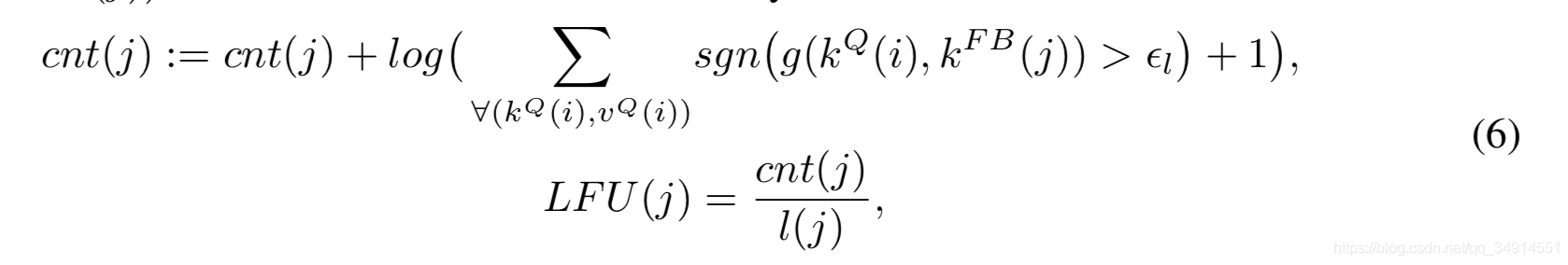
# p��softmax��attention mapif self.update_bank: # ֻ�ڲ��Ե�ʱ���ã�����try:ones = torch.ones_like(p)zeros = torch.zeros_like(p)bank_cnt = torch.where(p > self.thres_valid, ones, zeros).sum(dim=2)[0]except RuntimeError as e:device = p.devicep = p.cpu()ones = torch.ones_like(p)zeros = torch.zeros_like(p)bank_cnt = torch.where(p > self.thres_valid, ones, zeros).sum(dim=2)[0].to(device)print('\tLine 170. GPU out of memory, use CPU', f'p size: {p.shape}')feature_bank.info[i][:, 1] += torch.log(bank_cnt + 1)
��matcher�����У����Կ�������p�е�ÿ��λ���жϺ���ֵthres_valid�Ĺ�ϵ��ʵ�ּ�����Ȼ������ֱ��浽FB�С�
ϸ��
- FBֻ��eval���ã�ѵ����ʱ��6��ͼ�ѵ�һ������5��warp��
- 400*400 ��uncertain loss��Ȩ��Ϊ0.5��һ�����������в�3��Ŀ�ꡣ