摘要
CNNs已经在很多计算机视觉和图像理解的任务中获得了超越性的性能。然而,cnn仍然未能有效应用在视频目标分割中(以后简称VOS),因为 对待视频帧当做单独和静态的图像将丢失隐藏在动作中的信息。为了解决这个问题,我们为VOS任务提出一个运动指引式的级联的细粒度网络。通过设想目标的运动通常异于背景的运动,对于每一个视频帧我们首先应用一个active contour(level Set)在光流上,来粗略分割出感兴趣的目标。然后,我们提出的Cascaded Refinement Network(CRN)将这个粗粒度分割作为指引(guidance)来产生精确的并且是保留分辨率的分割。通过这种方式,运动信息和CNN可以互相帮助(complement),以此来精确地分割视频帧。而且,在CRN中我们介绍了一种单通道的残差注意力模块(Residual Attention Module)来联合粗分割的map作为guidance,使我们的网络在训练和测试中都更加有效和高效。我们在流行的benchmark上做了实验,证明了我们的方法实现了state of the art的效果,同时还能有更快的速度。(大概0.73sec/frame)
Introduction
VOS是计算机视觉中的一个重要的任务,因为对目标跟踪,视频复原,动作识别,视频编辑等有促进。由于在连贯的视频帧之间存在强的时空的关联,运动在很多最先进的VOS方法中起到关键作用。运动估计比如光流和像素轨迹揭示了在帧之间的联系,并且能够利用运动信息将一帧的前景/背景标签传播到另一帧。而且,运动包含了丰富的时空结构信息,对移动的目标分割很有帮助。然而,运动估计本身仍然是一个困难的任务,并且很难提供精确的结果。一些普遍的情况,如噪声,模糊,变形和遮挡能加重(exacerbate)这种困难。
不用与之前的方法,那些方法主要依赖运动,最近的一些基于CNNs的尝试通过学习解决了VOS问题。由于强大的学习能力并且大量的训练数据,CNNs在静态图像分割已经实现了非常好的性能。同时对于VOS,带有注释的训练数据是很缺乏 ,把每一帧视为静态图将丢失隐藏在运动中的信息。
这里解释一下黑体字的含义,这句话并不难理解。我们在训练maskTrack的时候,先是离线训练。由于是静态图方法,可以用做实例分割或者语义分割的数据集训练,所以训练数据集没有时序的关系,自然没有考虑到运动信息。然后在通过在线训练,达到最终的效果。
我先大致说一下论文思路。
这篇论文提出的方法又有不同,虽然同样是基于maskTrack,它有考虑到运动信息。首先是用静态图的训练方法训练CRN网络(后面会提到),为了能满足用于视频目标分割的方法,又用视频数据集做了一次离线训练。这次离线训练整合了光流和active contour,使得模型能适应视频分割任务。最后在测试数据集的第一帧做在线训练。
作者认为在maskTrack中仅仅使用静态图离线训练,然后用第一帧做在线训练的方法,仅仅能让网络记住目标,确实能从后续帧找到形态相近的目标。但是仅仅于记住目标的形态会有一些限制。例如,物体形态可能随着时间改变(along with time),在背景中出现和目标形态相似的目标(这种情况经常出现,我在maskTrack实验中就出现过这个问题,想分割一个人,连同把旁边的人的一部分也分割出来了)
这篇论文如何解决这个问题呢?试想两种情况:
- 目标物体在运动,旁边有个相似的物体没有在运动
- 目标物体在运动,旁边有相似的物体但是也在运动。
对于第一种情况,我们从光流图计算得到的分割就应该仅仅为目标的粗分割,因为相似目标没有在运动,自然光流图没有显示相似目标。
对于第二种情况,光流图中会显示多目标,这时利用上一帧的分割结果和active contour,把粗分割的轮廓通过迭代的方式慢慢往目标轮廓上靠拢,也能得到单独仅仅有目标的粗分割。
为了能利用隐藏在运动中的时空信息和CNNs的强大的学习能力,我们提出了一种由运动指引式(motion-guided)的级联细粒度网络用于VOS。方法有两个部分组成:基于光流的移动目标分割和级联的细粒度分割网络(CRN)。特别地,对输入帧,目标的粗略分割是从光流中取出的。 CRN用粗分割作为向导(guidance)输出精确的分割。
为了能够产生能提供目标的粗略形状和大致位置的粗分割,我们应用active contour来分割光流(光流通过flownet2获得)。active contour是图像分割的经典工具,并且通过找到能分别最大化前景区域和背景区域的同性相似度的最优分割。因为目标通常有和背景不同的运动模式,所以我们用active contour分割光流图。而且,通过合适的初始化,active contour模型能很好的收敛。
- 在每一个帧,我们首先计算当前帧和下一帧的光流图。
- 用光流图初始化active contour,使用上一帧的分割结果(对于第二帧来说,这里是第一帧的标签),通过迭代最终获得目标的粗分割。
整个过程如下图
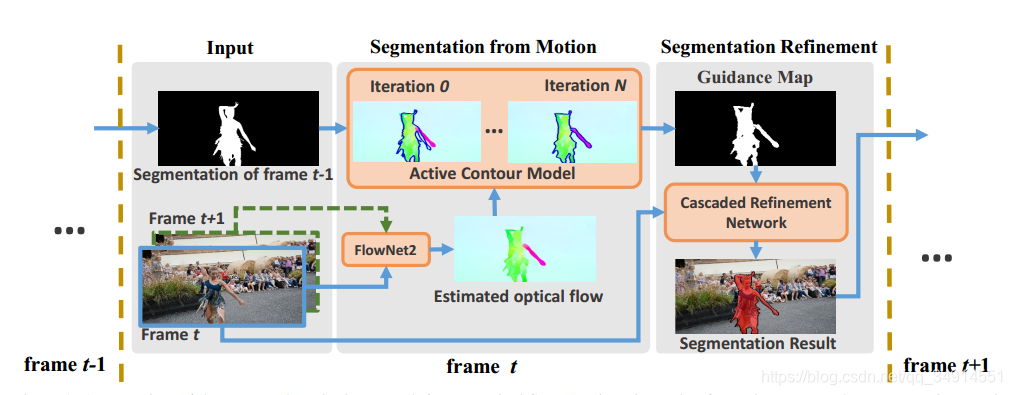
在得到了粗分割之后,将粗分割视为guidance map,和第当前帧一起送入CRN之中,输出当前帧的精确的分割结果,再将分割结果送到下一阵的分割之中。其中CRN里面还设计了一个残差注意力模块。这些具体都放在下一部分讲述。
这篇论文的主要贡献:
- 提出了一种基于光流的active contour 模型,能够有效地将视频目标分割出来
- 我们的CRN网络在训练和测试阶段都是高效的。在CRN中,我们提出了一个单通道的残差注意力模块,有效利用guidance map作为注意力,以便帮助CRN注意感兴趣区域,降低了模型大小和训练的负担。
- 我们的方法实现了在三个benchmark上最好的性能。在DAVIS上我们实现了84.4%的mIOU,0.73sec/frame,用于半监督任务;0.764的mIOU,0.36sec/frame用于无监督任务。比当前的方法更好,而且没有姿态的处理,实现更快速的分割。
方法
整个pipeline的第一部分是估计光流,使用的是flownet2,然后用上一帧分割的结果初始化active contour,我本人并没有看懂这个active contour,所以这一部分我就省略不仅讲述了。只知道使用迭代的方式求解,应用在光流上得到感兴趣目标的大致轮廓,作为粗分割。active contour的结果见下图。
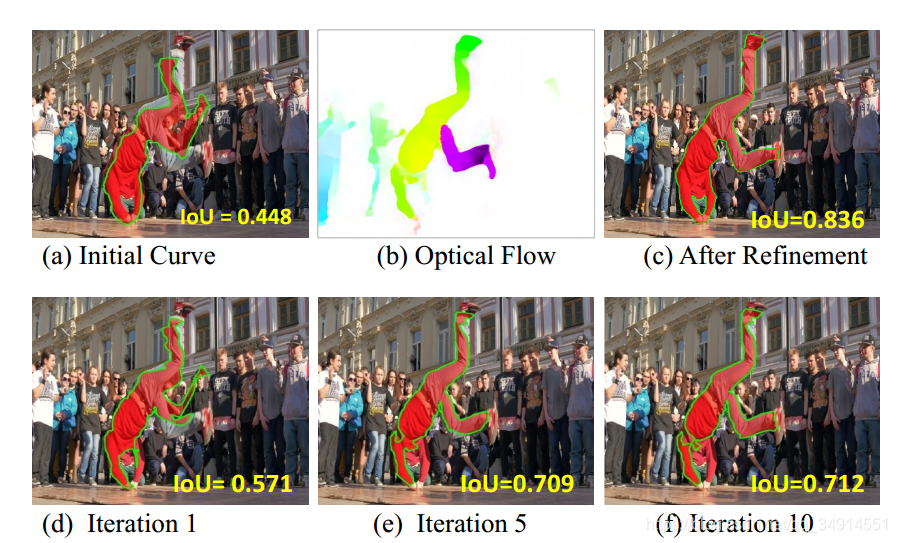
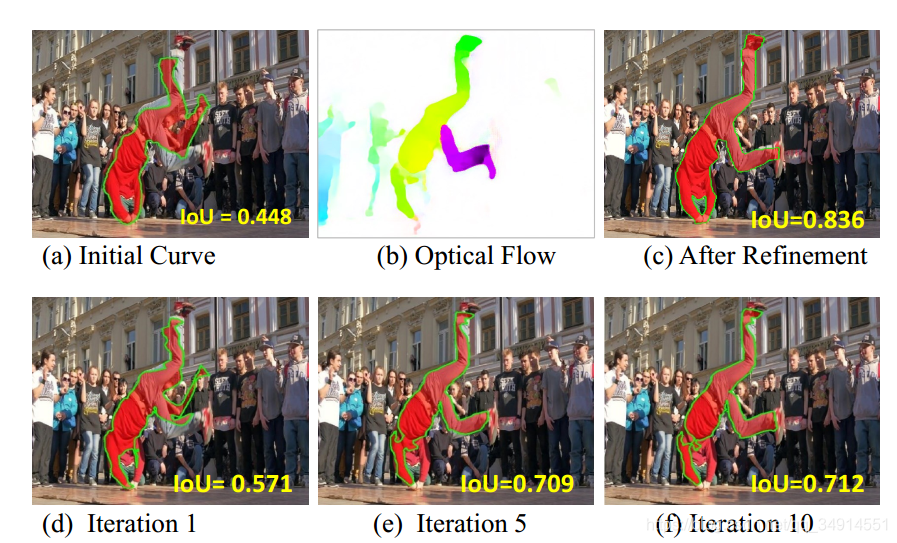
(a)就是使用上一帧的分割结果初始化active contour的结果,随着迭代次数的增加,mIOU越来越高,得到的粗分割越来越接近下一帧的感兴趣目标的全部区域。
接下来得到的粗分割会当做guidance map送入到CRN中。先看一下CRN的结构:
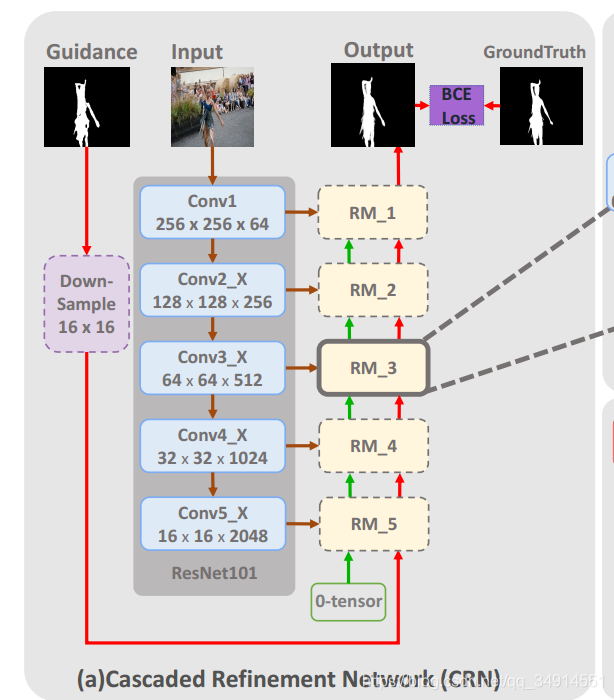
这是一个编码-解码结构,编码器选择resnet101,形式很像segNet,每一个大的卷积块的输出都送到在解码器对应的残差注意力模块之中。Guidance map先缩小为16x16的,(我在想resize成16x16真的好吗?16x16又能有多少信息保存呢?有没有一种更好的融合guidance map的方法呢) 我们还是主要看看resduial attention module(RM)。除了最后一个RM,即RM_1,每个RM都有三个输入,第一个输入来自于resnet101的每一卷积块的输出;其他两个输入来自于上一个RM。第一个RM,即RM_1,有一个输入为全0tensor。现在再来看看RM结构。
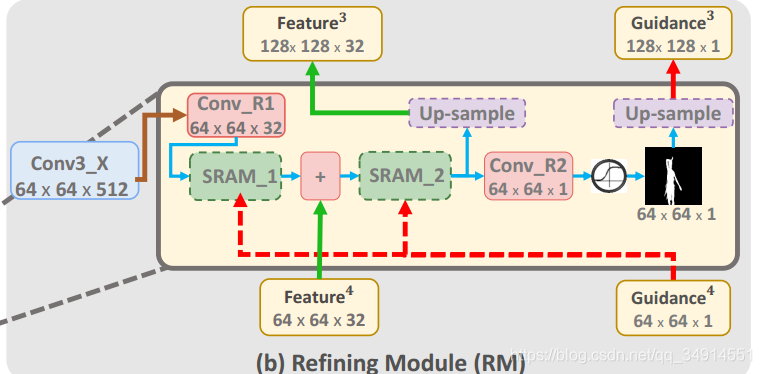
这里以RM_3为例,最左边的蓝色块代表来自resnent的特征图,经过一个卷积层和SRAM_1,加上来自上一个RM_4的输出,再经过SRAM_2,分两条路。其中一条线直接使用上采样得到更大的特征图作为RM_2的输入之一;另一条线经过一个卷积层,使用sigmiod函数获得单通道的分割结果,再上采样输出。
RM既然称为 residual attention Module ,自然含有残差结构,就在SRAM中。
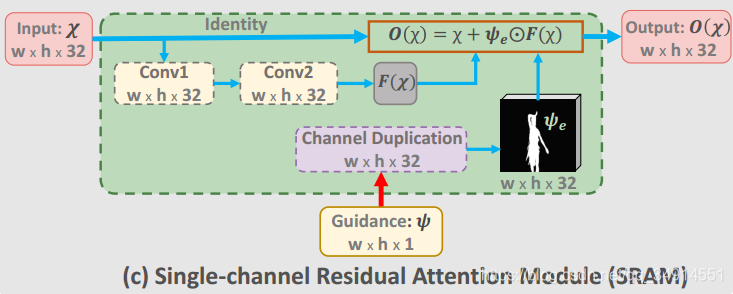
SRAM的S意味着输入是单通道的,这里看的出模块有一个残差块。那个圆圈里面有个点的符号就是对应元素相乘的意思。作者这里并没有像 《look closer to see better》中去分析这样设计的目的,又如何能体现注意力机制的效果。我的理解是Conv_R1无非是降维的作用,关键还是在SRAM中,那个element-wise 相乘使得特征图中不是预测区域的部分全部为0,然后在加上原来的输入,使得特征图中属于预测区域的部分的值变大了,那个后续的卷积核对这个区域就更加敏感,也就是起到了注意力的作用
训练方法
首先用在resnet101在ImageNet上训练的模型初始化resnet101,使用Xavier初始化其他卷积层。除了RM中的CONV_R2,所有卷积层都是用BN+RELU。
训练CRN
因为active contour 和flownet是不用训练的,所以训练过程仅仅训练CRN。由于CRN是在guidance map的指导下对图像分割,所以可以使用实例分割数据集来扩充训练样本。作者是在PASCAL VOC2012上用了11355张图像,他们的实例标签来自于ICCV2011年的一篇论文提出的方法。为了训练CRN,每一个训练样本由三部分组成,一个分辨率为512x512的图像,一个二值标签,和一个16*16的guidance map。这个guidance map不是数据集中的,为了做出guidance map,对前景mask(不就是label吗?)做形态学处理,用不同的核大小和不同核形状(矩形,椭圆,cross)。loss选择BCE,优化器选择SGD,初始学习率为0.0001,动量为0.9,
针对VOS离线训练
CRN网络仅仅在一些语义分割数据集上训练是不够的,即便CRN已经按照guidance map能分割出一般性的实例目标。为了能适应VOS任务,在DAVIS2016训练集上继续训练。guidance直接来自对label的形态学处理
在线训练
这个基本是任何VOS方法都有的一种半监督的方法,对第一帧训练,就不在多说了。
目前这个方法还没有开源代码