写在之前:初看这篇论文,觉得很惊艳,很巧妙,非常值得细读和动手实践,本人调通的Pytorch代码也会在后面详解。
另一篇更具有新颖性的人脸特征变换的论文是FaceID-GAN。附我的FaceID-GAN论文解读
摘要
在人脸识别领域,两张脸之间的大角度差异是一个关键的挑战。。论文提出一种能学到一种和姿势无关的人脸特征,将脸部的pose信息从特征中分离出去,这样用于人脸识别的特征提取就能适用于识别人脸的各种角度。首先,G有两个部分,是encoder-decoder结构,这允许DR-GAN具有识别和生成的功能,(encoder就是识别网络,decoder就是生成网络)。第二,encoder输出的人脸特征是不具有姿势信息的,通过给decoder提供姿态编码和判别器的姿态估计来实现。
网络模型
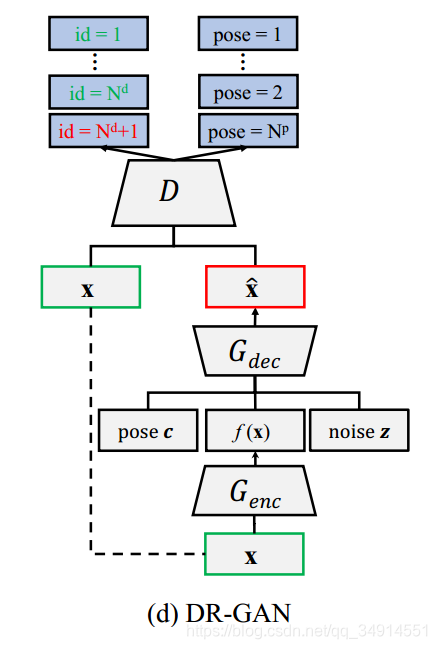
DR-GAN的输入有三个,x,pose code,和noise z。x是输入图像,经过encoder,获得了特征fx。此时fx,c,都是一维向量,将它们concat到一起,在经过一个全连接层,reshape为[ batch_size,channel,6,6]的tesor,送入到decoder中。decoder和encoder对称,是反卷积过程。
至此G的结构就看清楚了。下面看看D。
D仍然是一个类似于encoder的卷积网络,用来提取特征,最后做id和pose的分类,意思就是D就是个分类网络。这里Nd是训练样本中的人的数目,Np是这些样本人脸都呈现几种角度。论文中Np是9,Nd随数据集变换。还有一个超参数是Nz,为50,用于生成服从均匀分布从-1到1的长度为50的向量,就是noise z。
注意到身份分类那里,就是id那里,D要分类出Nd+1个类别。可是数据集中只有Nd个人,多出来的那个类别是什么呢?
多出来的那个类别代表了假样本。我们记生成的假图像为x~。
总的来看,D要把x~分到那个多余的身份类别上,把x都按照属于哪个人的人脸分类。再看pose这边,将x~和x都按照人脸是呈现哪种角度来分类。需要说明的是人脸的角度呈现9种离散值,可不是连续的哦。-60到+60,间隔为15度。
论文同时提出两种dr-gan,分别是single-image和multi-image。这两个gan仅在损失函数和处理fx上不同。
其中single-image的过程就是上述说的那样,输入的就是batch_size,channel,height,width的tensor,意思是batch中的图像都独立的,没联系。
multi-image的输入shape是[n* batch_size,channels, height, width],注意这个n意思是在一个mini batch中,同一个人脸有n张,有batch_size个人。先看同一个人的n张图像送进网络的过程。n张同一个人的脸通过encoder得到n个fx,需要一个fusion的过程,将这n个特征融合成一个特征。一种很容易想到的方法就是用1/n加权平均,论文并不是这么做的。再得到fx的同时,也用全连接层预测n个数字,代表了n个特征的confident coefficient(置信相关值?),用这n个值加权平均来得到最终的fx。
回顾一下过程,不难看出DR-GAN的亮点就在这个encoder之后,decoder之前的过程,将fx,z,pose code做处理的过程。
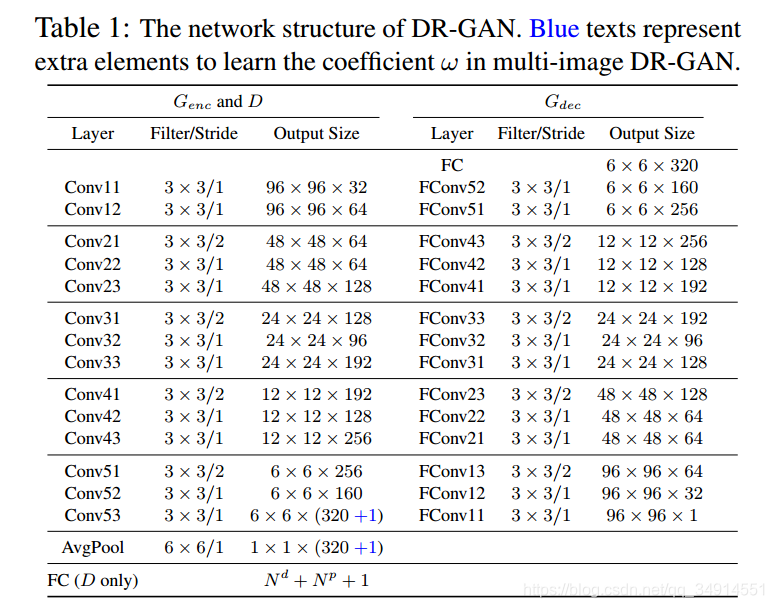
以上是全部的模型结构。注意到蓝色的+1,就是在预测那个confident coeffient。
思路来源
论文认为,人脸中通常存在扰乱的变化,因此通过encoder学习到的特征可能包含了这些干扰变换。例如encoder能对一个人的两张脸产生不同的身份特征,这些脸呈现0-90的变换。我认为这段意思就是说明明是相同的人的脸,仅仅是角度不同,我们使用诸如arcface,facenet,mobilefacenet获得的特征向量就不同了,指不定差异很大,这就是由于这些干扰变化导致的。
为了补救这个问题,论文采用side information,比如说pose code来学的一种具有判别力的表征。
损失函数
文中第三部分开头描述了下最初的gan所用的损失函数,并且指出G网络的损失函数不好,(因为在训练初期梯度小,关于GAN的损失函数发展历程以后会再写一篇汇总)。原始gan要优化的目标是。
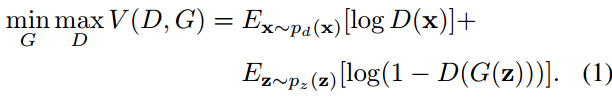
G要最小化第二项,因为G希望D(G(z))很大,希望D将Gz判断为正样本。DGZ越大,第二项就越小。
论文中更换的损失函数如下:
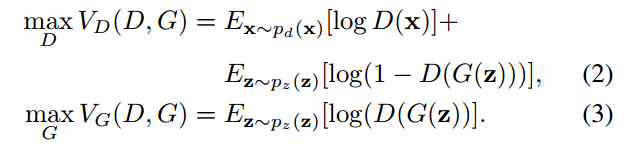
这两个函数最初并不是DR-Gan提出的。
现在就可以正式介绍DR-GAN所使用的损失函数了。
single-image dr-gan
一个样本x的标签是y={ yd,yp},yd是这个人的身份类别,yp是人脸呈现的角度类别(9类)。
D的输出是[ Nd+1+Np]维的向量。前Nd+1用来做身份分类,后面的Np大小的向量自然是用来做pose的分类。
D=![]()
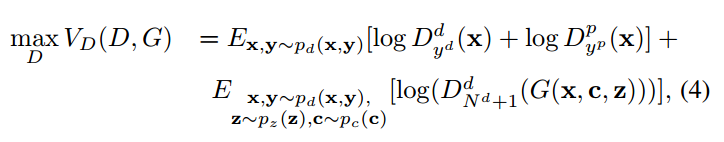
上面是D的损失函数,有点长。第一项对应真实数据x,第二项对应假的数据x~。先看第一项。
![]()
我打不出这些符号就先这么看吧。第一项其实就是对真实样本x进行身份分类和pose分类的交叉熵的相反数。
第二项中G(x,c,z)是生产的假图像x~,log里面的就是将假图像分类到假样本的交叉熵的相反数。注意到这里是不需要对假样本的pose进行分类的,假样本对应的pose code是人来提供的,是one hot编码。(至于为啥不需要呢?)
两项加在一起,最大化它们的和,就是最小化分类交叉熵。
再看看G的损失函数。
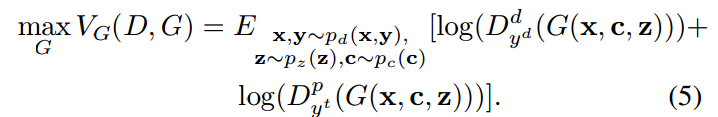
第一项是对假样本的分类,这里注意到G的目的是想混淆D,所以G想把假样本分类到对应的真实样本所属于的类上,所以第一项中的D的下标是yd,而不是Nd+1。第二项是想将假样本分类到正确的pose类别上。
这样假样本既能努力提升生成人脸的质量来混淆D的身份分类任务,也能获得具有期望的pose的人脸。
mutil-image dr-gan
略,因为损失函数虽然不同,但是也挺相似的。
实验结果
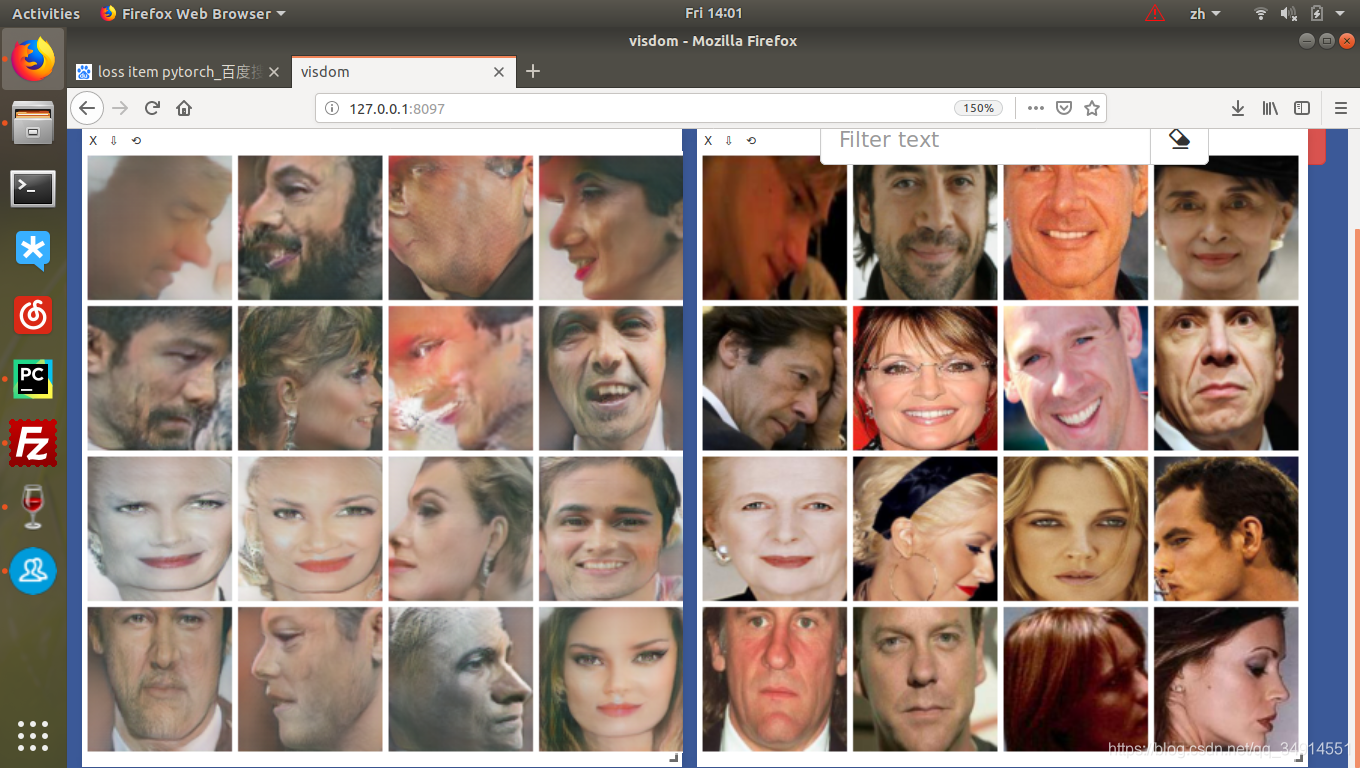
我仅仅在cfp 数据集中训练,因为数据集很小,没法获得很好的效果。
论文中使用cisia-webface数据集,同时使用了【12】【13】做出了pose label。cfp 仅仅有正脸和侧脸,所以我用的pose code就是[0 1] [1 0] 。下图左边是生产假数据,训练了1000个epoch的结果,还是很假。不过有些例子,确实能看到是保留了身份信息的,比如说第2行的第二张,第三行的第四张。
DR-GAN下载地址和代码片段解读见:
https://blog.csdn.net/qq_34914551/article/details/87381230