本节课程内容包括:
- 多任务学习
- 问题陈述
- 模型,目标,优化
- 挑战
- 现实世界多任务学习的案例研究
- 迁移学习
- 预训练和微调 3个目标
- 课程的目标是:
- 了解构建多任务学习系统时的关键设计决策
- 了解多任务学习和迁移学习之间的区别
- 了解迁移学习的基础知识
由于课程内容较多,分为两个视频,所以笔记也是按照视频来写,第一小节的内容包含了多任务的所有内容。
符号定义
首先介绍符号意义,在后面的学习中也是用到的。
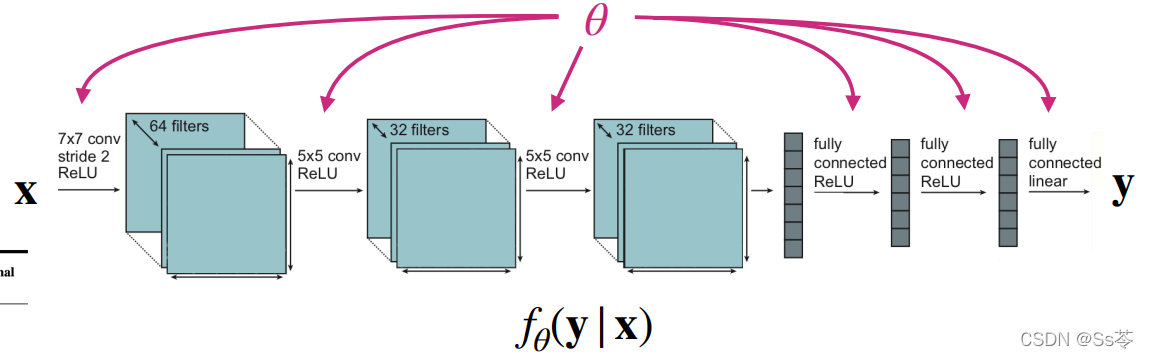
| 符号 | 意义 |
|---|---|
| x | 输入 |
| y | 输出,即标签 |
| 超参数,通过网络学习得来 | |
| f代表网络模型,整个表达式是给定输入x的标签y的求函数 | |
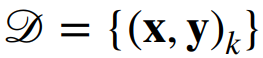 |
输入、输出对的数据集 |
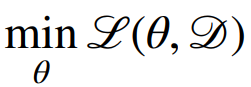 |
损失函数是关于数据集和的,目的更新,使尽可能小,典型的 损失函数可以定义为负对数似然函数:
|
| 某个任务,泛指第i个 | |
| 第i个任务输入的概率分布 | |
| 第i个任务给定输入的输出的概率分布 | |
| 第i个任务的训练数据集、测试数据集 | |
| 作为训练数据集简写 |
单任务
单任务(监督)学习就是已知训练数据集情况下,要尽可能地让损失函数小,最后输出标签y的概率分布,一个任务等价于三部分的内容,x的分布,给定x的y的分布,损失函数。
![]()
多任务是怎么样的?
多任务可以分为两种类型。
- 第一种:多任务分类;
- 第二种是多标签学习。
多任务分类就是有多个任务,每个任务共用相同的损失函数,但是它们的数据集是不同的,即x的分布、y的分布是不同的。
举例一:不同语种的手写数字识别,每个语种的字符(输入)形状都是不同的,并且对应类别(标签)也是不同的。比如英语和汉字的形状明显不同,且英语只有26个字母,汉字常用的有5000+。

举例二:个性化垃圾邮件识别,不同人对垃圾邮件的定义是不同的,比如运动员可能一些运动赛事的邮件对他们来说是重要邮件,但是对于一个不喜欢运动的人来说,就是垃圾邮件。
多标签学习就是同一个数据集,进行多个标签的学习,每个任务共用共用相同的损失函数、x的分布,但是y的分布是不同的。
举例一:名人特征的识别,比如一个标签是判断人是否戴了眼镜,这是一个任务;另一个标签是判断人是否戴了耳环,这是另外的任务。
举例二:场景理解,比如理解一个场景的图片,预测深度,或者预测表面法线。
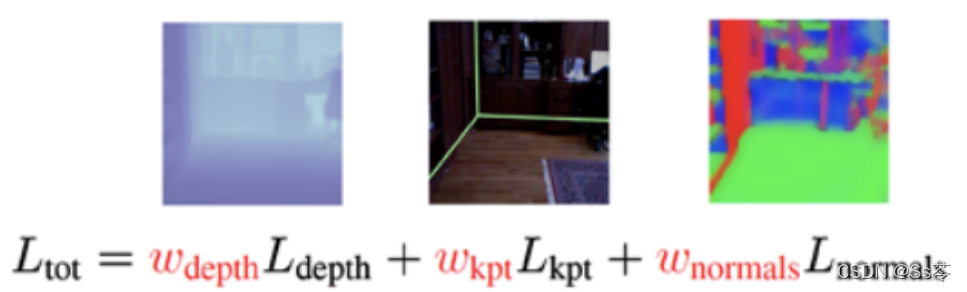
也有跨任务的损失函数不同的情况:
多任务中一些数据是离散的、一些数据是连续的;或者你关心不同的指标,对一个视频可能关心用户对它的满意度,另一个可能关心用户观看视频的时长。
多任务的损失函数是每个任务的损失函数的累加:
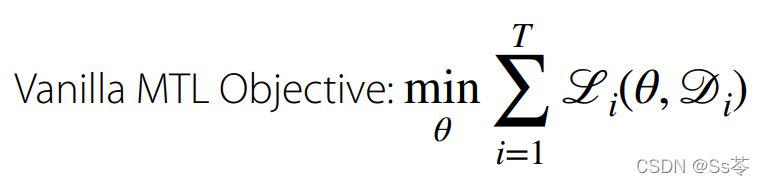
模型
一个模型如何知道当前训练的任务是哪个任务?
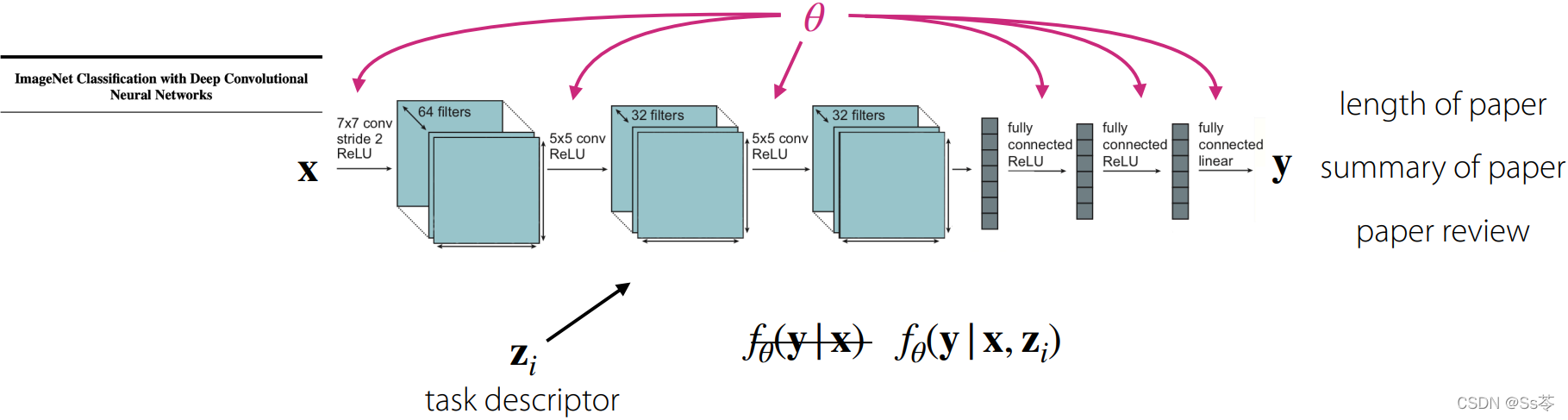
对于一个模型,此时需要一个任务描述符 z, 来告诉模型执行的是哪个任务。
比如我们的模型是对一个论文标题做一些任务训练,任务一是预测论文的长度,任务二是给出论文摘要,任务三是给出论文的评审,则可以用分别表示这三个任务的描述,z可以是one-hot vector形式,也可以是一些元数据,比如用户的信息或者特征或者属性,或者任务的语言描述“告诉我论文有几页”“给我一篇论文的摘要”“写一篇论文的评价”,或者是一些任务的正式规范。
任务描述符是如何加入到模型的?有哪些模型的参数是需要被共享?
假设z是one-hot vector。
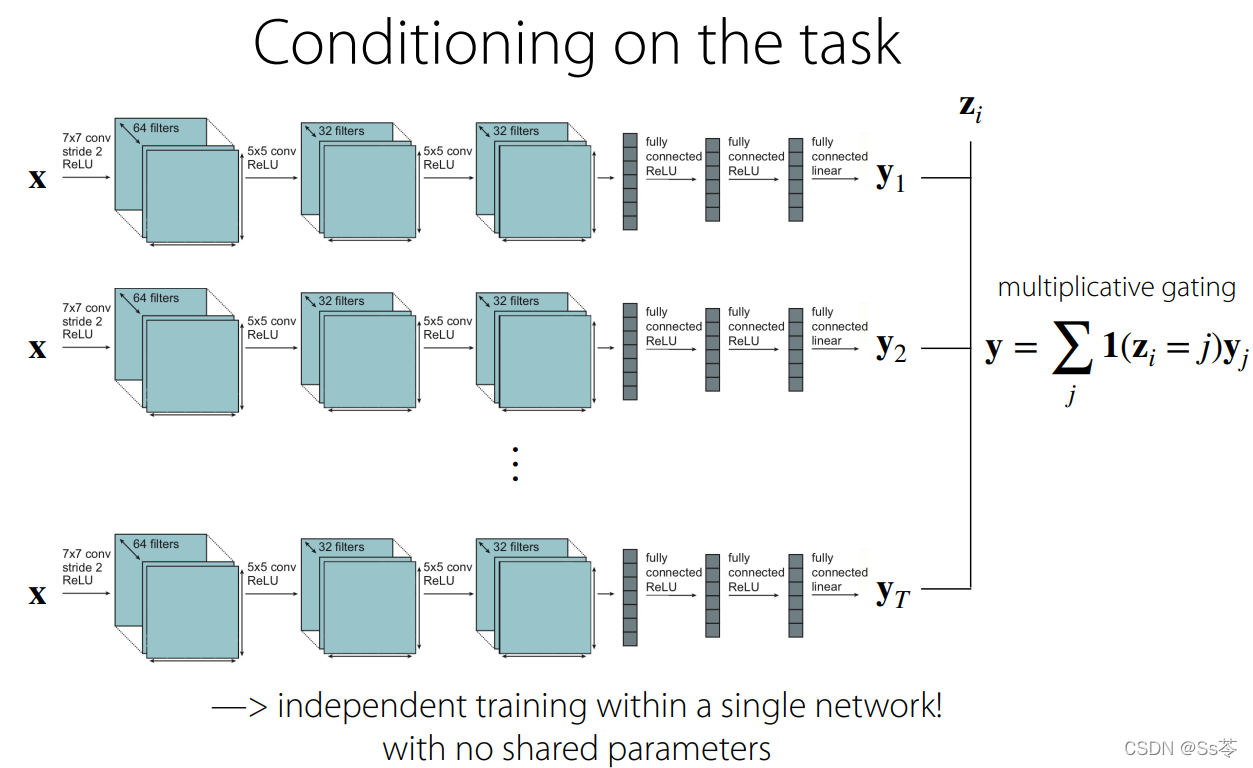
一种极端的情况是:每个任务不共享参数单独训练,在最后标签预测的时候加入z。如下图所示,有三个完全独立的网络,每个网络代表训练一个任务,并使用 one-hot 任务标识符来决定希望输出的是哪个神经网络。然后做乘法门控(0表示不起作用,1表示起作用)。
另一种极端的情况是:每个任务都共享参数,只有在加入z之后的参数不共享。z可以加入在某个激活函数之后,可以在前面,可以在中间,也可以在后面。
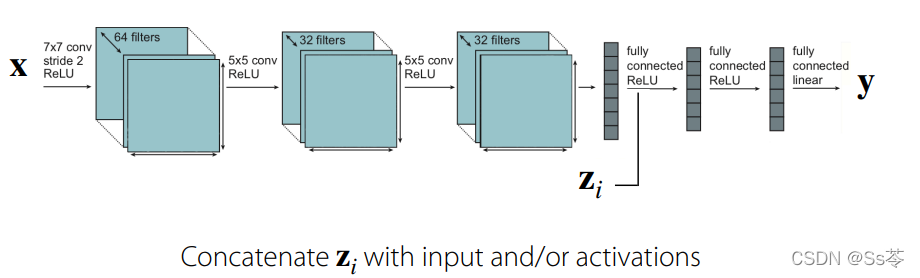
加入z之后的参数不共享的原因是,我们假定的z是one-hot vector,从下图可看出,在z拼接到激活函数的输出神经元,与权值矩阵w参与乘积运算时,权值矩阵w的一部分参数用于与输出神经元计算,一部分用于与z计算,那显然与z计算那部分参数就是用来控制特定任务的,是不共享的。
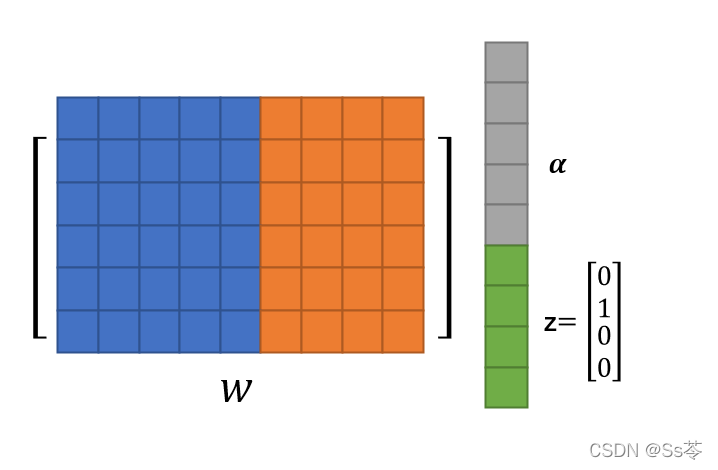
这种类型的多任务架构,可以找到一种替换的方案。
将权值分离为两部分,一部分是共享的权值,另一部分是特定任务的权值,因此目标函数变为:
选择如何以为条件调节 等价于 选择如何并在哪里共享权值。
常用的一些权值调节设计
第一种是基于拼接,第二种是基于附加,如图所示,思考:这两种方式本质上是等效的!为什么?
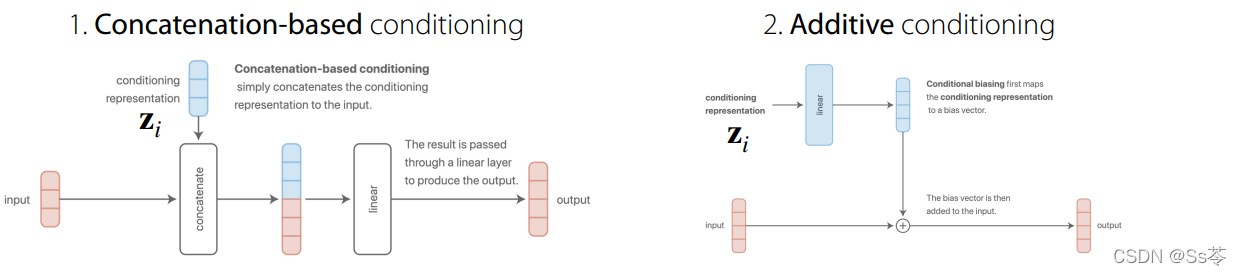
原因是,将两种方式都应用到接下来的全连接层之后,就会得到同样的结果,这是由乘积的计算过程导致的,矩阵的每一行与向量乘积后累计得到的都是一个数,基于拼接的方式中每一行乘积是一次性得到一个结果,基于附加的方式中是分了两步,先得到两个部分结果,在累加得到最后结果。
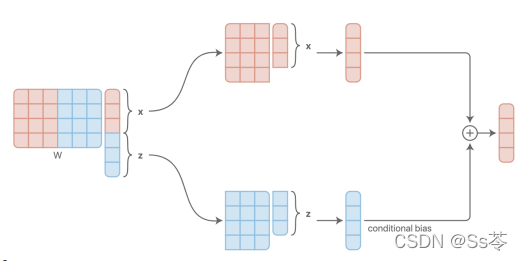
Diagram sources: distill.pub/2018/feature-wise-transformations/
第三种是基于多头的,第四种是基于乘法的。
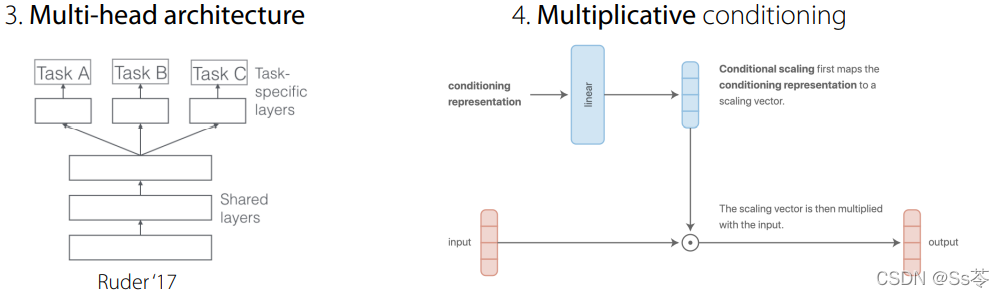 基于乘法的方法是比较好的一种,这是因为对于每一层,它能获得更多的表现力,在某些方面, 乘法条件泛化了独立网络、独立头等。
基于乘法的方法是比较好的一种,这是因为对于每一层,它能获得更多的表现力,在某些方面, 乘法条件泛化了独立网络、独立头等。
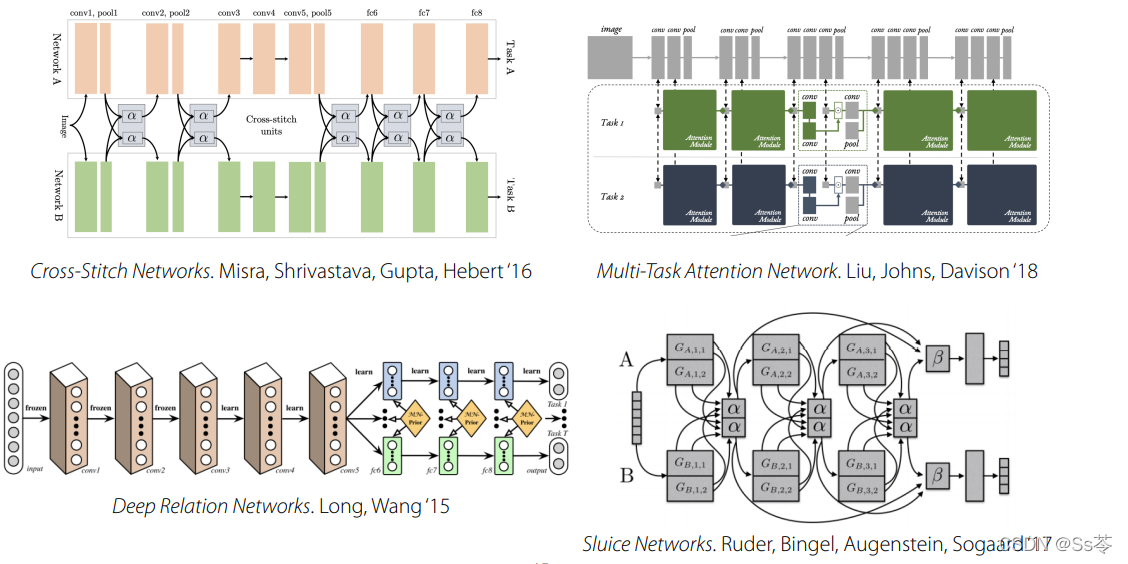
其他更为复杂的选择,如下图。
权值调节设计,就像神经网络的微调一样:
-- 往往相当依赖问题
-- 通常主要由直觉或问题的特定领域知识指导
-- 在许多方面, 它们目前更像是一门艺术而不是一门科学
目标函数
目标函数应该如何形成?
通常会给每个任务加上权重来区分他们的重要程度。
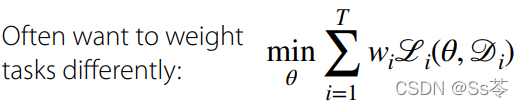
如何实际选择这些任务权重?
方法1:手工选择权重。可以基于人为定义的重要程度或者优先级,这显示不是一种很好的选择。
方法2:在训练过程中动态调整权重。这种方式有一个关键的问题是,如何在整个动态训练过程中调整?有以下几种方式。
- 各种启发性方法。比如在文献中相当流行的一种启发式方法,是鼓励梯度具有相似的幅度。这是 2018 年毕业规范论文中提出的内容。它相当受欢迎, 而且似乎运作良好。一种直觉的指导是,如果梯度具有相似的幅度,那么没有一项任务会占主导地位。
- 使用任务不确定性。如果希望不确定的任务的权重更高,则减少对这些任务的不确定性。有一种公式表达,如下公式(1)所示,假设对于每个任务 i,在给定 x 的情况下,你基本上有一个 y 的分布。如果进行回归,y的分布会设置为等于高斯分布,均值等于神经网络的输出,方差是每个任务的学习向量。这就是任务不确定性。
(1)
这里的方差称同方差不确定性。这与神经网络可能具有的典型不确定性形成对比,神经网络会为每个数据点输出不同的不确定性。这就是所谓的异方差不确定性。
公式中是同方差不确定性,因为它对于任务中的所有数据点都是相同的。并且这里要代表特定任务的不确定性,所以引入一个索引 i 。事实证明,如果最小化每个任务的每个数据点的负对数似然,如下公式(2)所示,基本上可以证明 ,这与公式(3)成正比。
(2)
(3)
所以这就是说,完全对应于。对于任务来说,标准差或方差越高,不确定性就会越高,因此应该对它们进行不同的加权。更小的不确定性应该设置更高的任务权重;更多的不确定性应该设置更小的任务权重。
- 将多目标优化单调改进为帕累托最优解。
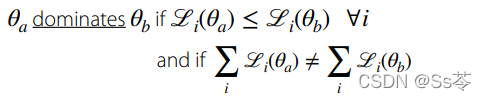
- 针对最坏情况的任务类别进行优化。i指的是情况最坏的任务。
![]()
优化
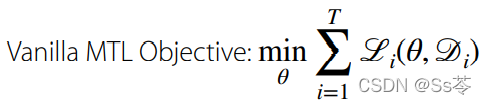
优化的基本过程如下:
- 从任务集中抽取一小批任务
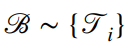 ,如果任务数量相对较少,那么可以对所有任务进行抽样。
,如果任务数量相对较少,那么可以对所有任务进行抽样。 - 为每个任务采样一小批数据点
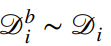 ,获取该任务的训练数据,并从该数据集中抽取一个小批量样本。
,获取该任务的训练数据,并从该数据集中抽取一个小批量样本。 - 使用损失函数计算该小批量的损失
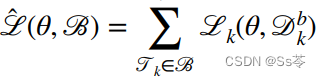 。
。 - 将每个小批量的损失反向传播到以计算梯度
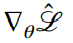 。
。 - 有了梯度,就可以使用最喜欢的神经网络优化器,比如 Adam,来更新你的神经网络。
这样做的目的是 ,本质上鼓励模型在每个小批量中考虑来自多个不同任务的数据,无论一项任务的数据是否多于另一项任务的数据,这种方式能够保证数据的统一采样。
此外,对于回归问题,要确保任务标签处于相同的规模。如果它们不在同一个范围内,则需要对损失函数加权,即对规模更大的损失进行加权。
挑战
1.负迁移 -- 在一个单一架构中进行多任务训练时,它的训练效果比训练独立网络时表现更差。
举个例子,查看 CIFAR-100 基准测试的多任务版本并查看最近的一些方法,如图所示,训练一个独立的网络得到 67.7,其他的架构,包括两种多头架构、十字绣架构,都比独立网络训练差。这三种架构都发生了负迁移。
 为什么会这样?
为什么会这样?
这可能由于几个不同的原因引起的。可能是不同梯度之间的干扰引起的优化问题;也可能是有限的表征能力问题,不同的任务可能以不同的速度学习引起,可能一个任务学习得更快,并且在学习另一个任务之前就耗尽了很多容量,这是一种能力有限的问题。通常情况下,多任务网络需要比其单任务对应更多的容量。这也可能与优化问题有关,因为如果有一个更大的网络,它可能更容易优化。
如何改变?
一是增加容量。二是改变优化,或者以某种方式改变架构,这两种方式都可以缓解负迁移的问题。
具体来说,可以减少跨任务共享。或者是进行软参数共享。可以用不同的特定于任务的参数,鼓励这些特定于任务的参数彼此更相似,这样可以最小化不同任务的参数差异范式。
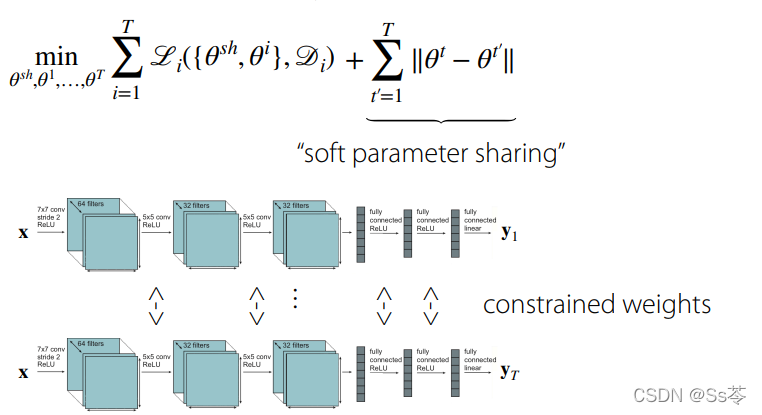
2.过拟合
当发生过度拟合时,实际上时没有共享足够的网络权重。多任务学习本质上可以被视为一种正则化形式,其中任务在进行正则化学习 ,学习另一个任务。
可以共享更多参数解决这个问题。
现实世界多任务学习的案例研究
略。