��DO DIFFERENT TRACKING TASKS REQUIRE DIFFERENT APPEARANCE MODELS?�������Ķ��ʼ�
Paper��https://arxiv.org/pdf/2107.02156.pdf
Github ��https://github.com/Zhongdao/UniTrack
ժҪ��
������Ƶ�и���Ȥ�Ķ����Ǽ�����Ӿ��������к���㷺���õ�����֮һ��Ȼ�������Ž�Щ��ķ�չ���������ڰ��������ݼ�����̽���Ѿ������������ɢ���˲�ͬ��ʵ�������С���ˣ�����Ҳ����Ƭ���ģ���������������·���ͨ��ֻר���ʺ�һ���ض������á�Ϊ����������רҵ���ڶ��̶����DZ�Ҫ�ģ���������У����������UniTrack��һ�ֽ����ͬһ����ڽ�������ͬ����Ľ��������UniTrack��һ����һ�ĺ��������ص����ģ����ɣ��������Լල�����Ҽල�ķ�ʽѧϰ���Լ������ͷ�����������������Ҳ���Ҫѵ��������չʾ��������������ڽ����������������ҿ���ʹ����ͬ�����ģ��������������ǵ��������������ض��������о����������ܡ��ÿ�ܻ��������Ƿ���ʹ�����µ��Լල������õ����ģ�ͣ��Ӷ���������չ���ǵ������ͱȽϵ��������Ҫ���⡣
? JDEͬ���ߵ�һƪ���£���һ�ο���ժҪ��ʱ��о����ܾ��ޣ������뽫���е�tracking����������һ������У��Ҳ�ͬѵ�����Ͼ����ޡ���Ϊ����tracking�������ʱ��ͨ��������Ҫ�������������һ���������ԱȽϹ�����MOT������˵����Ԥ�������Ե�λ�ã�SOT������һ���ǿ����mask�Ļع飬������Ҫ����ͨ�����е�����о���ͦ�ѵġ�
1��ժҪ��
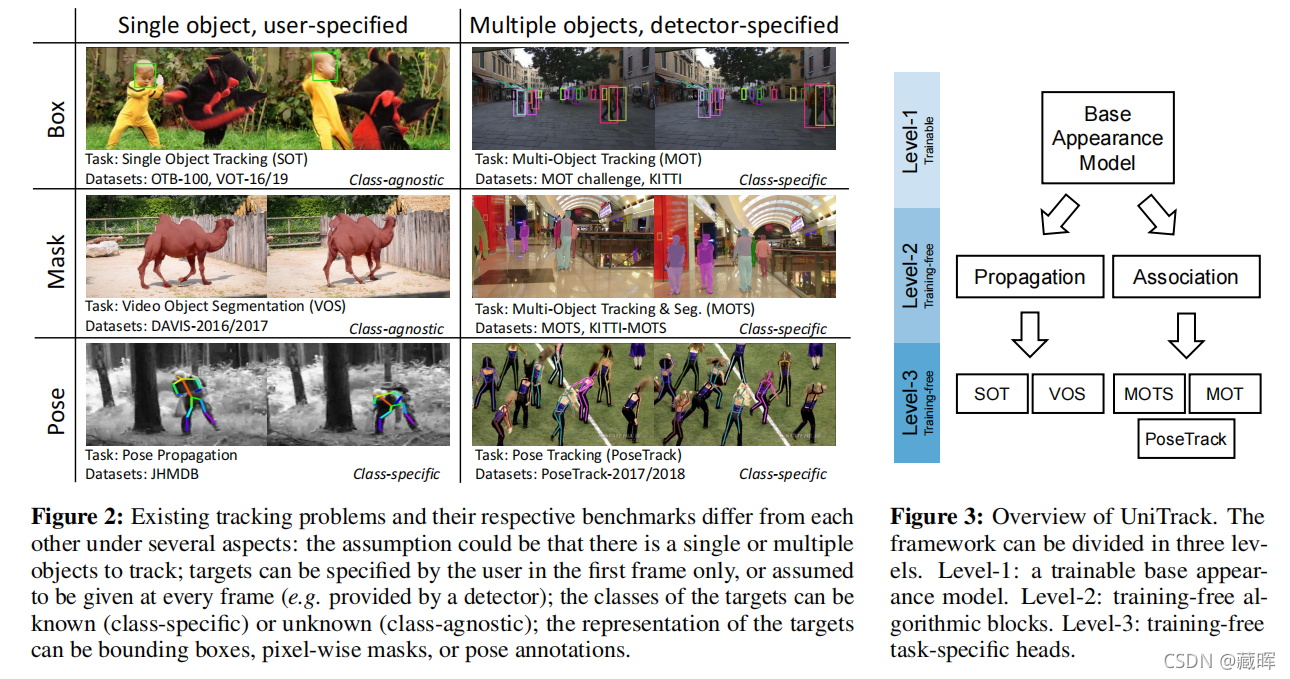
�ڷ����У����߽����еĸ���������Ϊ���������������⡣������Ϊ���������ʱ��SOT��VOS����������Ҫͨ����һ֡��������Ϣ����λ��ǰ֡Ŀ���λ�á��෴���ڹ�������(MOT��MOTS��PoseTrack)�У�������֮ǰ�͵�ǰ֡�е�Ŀ��״̬����Ŀ����ȷ������۲���֮��Ķ�Ӧ��ϵ������չʾ��Ŀǰ�����п��ǵĴ��������������ο��ԼشӴ���������ij��Կ�ʼ��ʾ�����ڴ����������Dz��������еĿ��mask�����㷨��SiamFC��DCF�������ڹ����������������һ���µĻ����ؽ��Ķ�����������ϸ���ȶ�Ӧ�������۲���֮��������ԡ�
������Ŀ���У�ÿ���������������һ��ר�ŵġ�ͷ�����������ʵ��ĸ�ʽ��ʾ����������ػ��ϵ����м������бȽϡ�
��ע�⣬������������ԭ���������Լ��ض��������ͷ������������ѧϰ�IJ�����ֻ�л������ģ�Ϳ���ѧϰ����Ҫ���ǣ����Dz��ڵ���Ŀ��������ѵ�����ģ�͡��෴�����Dz����������������е�������֪�ļල�����Ҽලģ�ͣ���Щģ���Ѿ��ڻ���ͼ���������֤�������ǵ���Ч�ԡ�ͨ�����ַ�ʽ�����ǵĹ��������������ͱȽϴ����Ҽලѧϰ��������ͼ1���л�õ����ģ�ͣ������������г��������Ļ���ͼ������⼯��
? ���߽��������ͳһ��һ������е�˼·������һ������ѧϰ���磬ͨ�����������ѧϰ��������������������Ϣ��Ȼ��ͨ����ͬ��head��ʵ�ֲ�ͬ������
2��The UniTrack Framework��
1��Overview
�ڼ�����еĸ�������ͻ�����ʱ������ע����ǵIJ�����Դ��¿��ĸ�����з��࣬��ͼ2��ʾ����ϸ˵�����£�
1������Ҫ���ٵ�������(SOT[32]��[82]��VOS[54])��������Ҫ���ٶ������(MOT[54]��MOTS[69]��PoseTrack[1])��
2��Ŀ����ֻ���û�ֻ�ڵ�һ֡��(SOT��VOS)ָ����������ÿ֡�и��������硣ͨ��Ԥ��ѵ����̽����(MOT��MOTS��PoseTrack)��
3��Ŀ��������ɱ߽��SOT��MOT�������ؼ����루VOS��MOTS��������̬ע��(PoseTrack)��ʾ��
4�������Ƿ��������֪�ۡ�Ŀ�������������κ��ࣨSOT��VOS�������ߣ������������Ԥ������༯��MOT��MOTS��PoseTrack����
ͼ3�������������UniTrack��ܵ�ʾ��ͼ����������������Ϊ�ڸ����Ϸ�Ϊ���������𡱡�
��һ�������ģ�ͱ�ʾ�����������֡����ȡ�߷ֱ��ʵ�����ͼ����2.2�ڣ���
�ڶ��������������㷨�����ɣ�����������propagation����2.3�ڣ�������association����2.4�ڣ���
������һ������ֱ��ʹ�õڶ�����������ж���ض���������㷨��
2���������ģ�ͣ�Base appearance model��
�������ģ�ͦ��Զ�άͼ��I��Ϊ���룬���������ͼX=��(I)��RH��W��C��������������£����ڶ������������ģ��Ӧ���ܹ�����ͼ��֮���ϸ���������Ӧ������ѡ��һ��С����Ϊr=8�����磬ʹ���������ռ��е����������Խϴ�ķֱ��ʡ����ǽ�����ͼ�е���������������ŵ�ά������Ϊ��������������������ͼX1�еĵ�����xi1��RC��X2�еġ�����ƥ�䡱������xi2���кܸߵ������ԡ�����X2�����еġ���ƥ�䡱������xj2����Զ����������s(xi1, xi2) > s(xi1, xj2), ?j = ?i,����s��ʾ�����Լ��㷽�̡�
Ϊ��ѧϰϸ���ȵĶ�Ӧ��ϵ����ȫ�ල�ķ���ֻ�����ںϳ����ݼ���������ʵ��������ݣ���������ȫ�ල�ķ�ʽ��������ؼ��Ķ�Ӧ��Ǻ�ѵ��ģ�͡�Ϊ�˿˷���һ�ϰ��������ڱ�����̽�������ֿ��ܵĽ����������һ�������������֮ǰ�Ĺ�������Щ����ָ����ϸ���ȶ�Ӧ����γ������в������еġ���ˣ�һ����ǰѵ�����ķ�������ѧϰģ�Ϳ�����Ϊ���ǵĻ������ģ�͡��ڶ�����������Լලѧϰ�����Ľ�չ���÷���ר���������ؼ���pretext�����ڱ����У�����ͨ�����������������ͬ�ĸ��������ϵ�������ͨ������̽�����ֱ�ʾ����õġ�
?������Щ�Լල�����õĹ��������������ѧ�����о������棬֪������һЩ�ܽ�����Ҳ������https://zhuanlan.zhihu.com/p/150224914?from_voters_page=true��������һ�������ԼලΪɶ����ѧ����Щ��ʾ�Ŀ��Բο�һ�£���ţ������
3��������Propagation��
SOT��VOS�еĴ������Ǹ�������һ֡�Ĺ۲���Ϊ���룬Ȼ��Ԥ������һ֡�и������λ����Ϣ�� ���߽����ִ�����Ϊ������������ʾ�����߽�ָ���ģ�����ƹǼܡ�
Mask propagation
Ϊ�˴�����ģ�������������������Ƶ���Ҽල�������ƹ�ģ�����ע�����ģ�����������һ������֡Xt-1��Xt������ͼ�����Ƕ�����RsxC,�Լ�ǰһ֡��mask zt-1��[0,1]s������s = H x W��ʾ�ռ�ֱ��ʡ����Ǽ���Ǩ�ƾ���Ktt?1=[ki,j]s��s��ΪXt?1��Xt֮����;���ÿ��Ԫ��ki,j��������Ϊ:
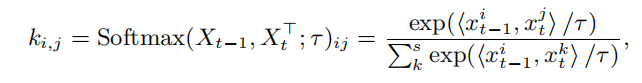
����Ktt?1��ֻ����ÿ�е�top k��ֵ����������ֵ����Ϊ0��Ȼ��ͨ������֮ǰ��Ԥ�⣺zt=Ktt?1zt-1��Ԥ�ǰt֡����ģ�����봫����ѭ����ʽ���У���ǰ֡���������������һ��֡�����롣
Pose propagation
Ϊ�˱�ʾ��̬�ؼ��㣬����ʹ���˹㷺���õĸ�˹����ͼ��Gaussian belief maps��������һ���ؼ���p��������һ����ֵ���ڹؼ����λ�úͷ����������ߵ����ͳ����ȵĸ�˹���ߣ��õ���һ������ͼzp��[0,1]s��Ϊ�˴���һ����̬�����ǿ��Ե���������ģ������ͬ�ķ�ʽ����ÿ������ͼ��ͬ����zt=Ktt?1zt-1��
Box propagation
�����λ��Ҳ��������ά����z=(u��v��w��h)���ر�ʾ������(u��v)�DZ߽�����ĵ����꣬(w��h)�����Ŀ��Ⱥ߶ȡ��������ǿ���ͨ���ؽ��߽��ת��Ϊ���ؼ������������������ԣ������ǹ۲쵽��ʹ�����ֲ��Իᵼ�²�ȷ��Ԥ�⡣�෴������ʹ��SiamFC�ķ�������������Ŀ��ģ��zt?1��Xt֮֡��ִ�л����(XCORR)����Ѱ��Ŀ����t֡����λ�á�������ڲ�ͬ�ij߶���ִ�У��Ա�߽���ʾ������Ӧ�ص�����С�����ǻ��ṩ��һ��������ع��������������(DCF)����Ҳ���漰�κ�ѵ����
4��������Association��
���������������MOT��MOTS��PoseTrack����������������£�������֡{I?t}Tt=1�Ĺ۲���Ϊ{Z?t}Tt=1��ͨ����Ԥ��ѵ���ļ�����ṩ�������Ŀ����ͨ����������֡�Ĺ۲������γɹ켣��
Association algorithm
�������е�JDE�ķ���������������˵�����Ǽ������Ѿ����ڵ�N���켣���������һ������֡��M�����¡������֮���N����M���������Ȼ�������Ծ������Ϊ���룬ʹ���������㷨������ȷ���켣�ͼ��֮���ƥ���ϵ��Ϊ�˵õ����㷨��ʹ�õľ���������Ǽ����˿����˶�������������������������ϡ�����ǰ�ߣ����Ǽ���һ������ָʾһ�����Ŀ������뿨�����˲���Ԥ���Ŀ��״̬��Ӧ��
? ������Բο���֮ǰ��һƪ���£�https://blog.csdn.net/qq_34919792/article/details/107633874
���ں��ߣ���������ʹ�ÿ�֡�۲���Ӿ�����������ģ�һ�������Ŀ�������ɻ������ģ�ʹ������Ի��һ��֡��������ӳ�䡣Ȼ����Ȼͨ���ü�֡������ӳ�����ֱ�ӻ��������ģ��ʾ��Ӧ�Ķ�����������������ͨ����̬��ʾʱ��������Ҫ����ת��Ϊ��ģ��
�˳�����һ���ؼ���������ζ���ʵ��������֮��������ԡ����Ƿ������еķ�������һ���ľ����ԡ����ȣ�ͨ��ͨ����ÿһ��Ŀ�������ӳ��ϲ�Ϊһ���������������ı����������������ƶȣ������Ƚ϶���֮��Ĺ�ϵ��Ȼ����ƽ���ػ������϶����˾ֲ���Ϣ�������ϸ����ʶ�����Ҫ����Щ������ij�̶ֳ��ϱ�����ϸ���ȵ���Ϣ��������Щ���㣨��ƽ) ����ӳ������������Եķ�������֧�־��в�ͬ��С��ʾ�Ķ���(����������ؼ�������������Ϊ��Ӧ���������ƣ����������һ�ֻ����ؽ������ƶȶ��������ܹ�������ͬ�Ĺ۲��ʽ��ͬʱ��Ȼ����ϸ���ȵ���Ϣ��
Reconstruction Similarity Metric (RSM)
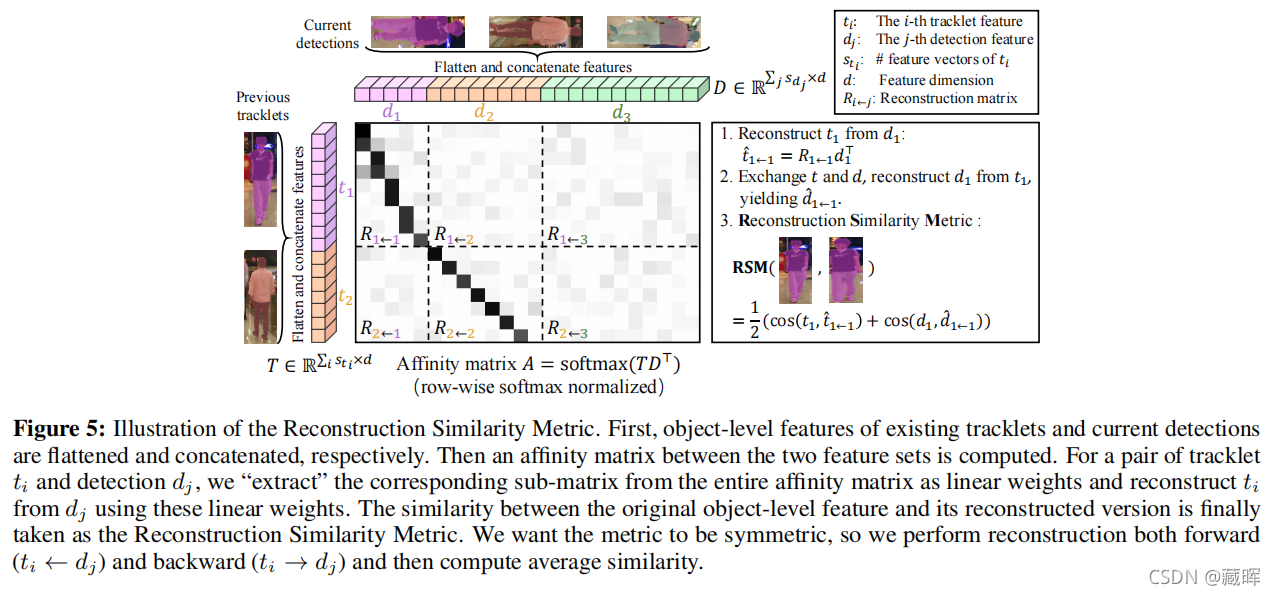
��{ti}Ni=1��ʾN�����й켣�����弶������ti��Rsti��C��sti��ʾ����Ŀռ��С���������mask�ڵ������������Ƶģ�{dj}Mj=1��ʾM���¼��Ķ���������Ϊ�˼��������ԣ����һ��N��M�;����ṩ���������㷨�����������һ���µĻ����ؽ������ƶȶ���(RSM)������ֵ�ļ������£�
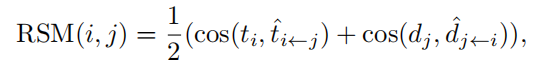
����t?i��j��ʾdj�ؽ���ti��d?j��i��ʾti�ؽ���dj���ڶ������ٳ����У�����Ƶ�����ڵ����۲������Dz������ġ���ˣ�ֱ�ӱȽ�����֮�䲻�����������Ĺ۲����������ھֲ�����֮���ʧ����ʧ�ܡ�����dj��һ������һ���˵İ������ļ�����������켣��������һ���˵����壬�������ֱ�Ӽ���������(e.g.ʹ�����Ҷ���)�����ǵ������Կ����൱С��RSMͨ�������ؽ����������������⣬���������Ϊһ��������̡��ؽ��������Ĺ��ֲ��ֱ����룬������յ������Ա�ø������塣
�ع��Ķ�������ͼt?i��j��dj��һ�������Ա任���� t?i��j=Ri��jdj������Ri��j��Rsti��sdj��һ���任���õ����¡��������Ƚ����ж������Ա�ƽ������Ϊһ����������������һ�������Ӧ�Ĺ۲⼯����һ����һ����������T��ͬ�������ǵõ���һ���µļ��D�����ж�������ͼ��֮�����Ǽ�����;���A=Softmax��TDT��,������ȡ������Ri��jӳ����ΪA������Ӧ�ģ�i��j�����ټ��Ե��Ӿ����йظղ������Ĺ��̵�ʾ��ͼ����μ�ͼ5��
RSM���Դ�ע�����ĽǶ������͡����ع��Ĺ켣ͼ������ͼ���Կ�����һ���ѯ����Դ���������dj����ͬʱ����Ϊ����ֵ����Ŀ����ͨ����Щֵ����������������ѯ��������ϣ�ע�⣩Ȩ����ʹ�ò�ѯ�ͼ�֮�������������ġ�������˵���������ȼ���ti������dj��j=0,1,��,M��֮���ȫ���;���Ȼ����ȡti��dj��Ӧ���Ӿ�����Ϊע��Ȩֵ�����ǵĹ�ʽ�õ���һ�����������ʣ����ע����Ȩֵ�ӽ��㣬��Ӧ���ع����������ӽ������������ti��dj֮���RSM�������㡣
ͨ���ؽ�����������������������ʾѧϰ�����Ҽලѧϰ��������ʶ��������к����С�Ȼ�����ؽ�ͨ��������Ϊһ�����ع�������������⡣RSM����ع����Ч(����ʱ������O(n2)���Ӷȣ�����ع������ͨ���и��ߵĸ��Ӷ�)�������ڼ����������������Earth Moving Distance�ļ��������ơ�
?�ڶ�Ŀ��������У������ܸ��ӹ�ע���ǹ������⣬�����������Ŀ�ܵ�box�����FairMOT������mask�����COSTA������û�е������ɡ���ʵ��������˵������imgenet��Ԥѵ����ģ�ͣ���Ȼû��ȡ�����ŵ����ܣ�����һ����ܿ��������ô��������������Ҳ�Ǿ��к�ǿ�ľ�����������ʵ�����ͷ����Ƽ�ȥ�Ķ�ԭ�ġ�
�ܽ��£����Ľ������������ͳһ��һ�����UniTrack�н��н��������������imagenet�����Լලѧϰ�������ģ��Ϊʲô�ܾ��������������������Ķ�������ѧϰ���˺ܶࡣ��ʵ���ϣ���Ȼ��һ�������ƣ������ָ�������ݼ��Ͻ���ר�ŵ�ѵ�����ܻ���Ը�һЩ�������ǿ���ͬʱ��ɶ�������о������ġ���Ȼ��������һ�������ƣ������������������ɶ��tracking�����ڶ�Ŀ������еĿ��mask�����õ����еĽ����ֻ��ע��ƥ������Ҳϣ�������й�����������box��mask��key points��Ԥ��Ҳunity��һ��