前言
在上一篇文章Spring Alibaba Cloud使用Seata实现分布式事务,Nacos作为配置中心(一)进行实战演示,这篇文章主要讲原理解释及流程分析,最好大家可以结合代码进行阅读
最好大家可以结合代码进行阅读分析
一. Seata 事务分组
1.什么是事务分组?
大家看完之后很疑惑 我配置
vgroup_mapping.prex_tx_group = "default"
这个事务组有什么用?
A:事务分组是 Seata 的资源逻辑,类似于服务实例。
service {#vgroup->rgroupvgroup_mapping.prex_tx_group = "default"#only support single nodedefault.grouplist = "127.0.0.1:8091"#degrade current not supportenableDegrade = false#disabledisable = false#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanentmax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"
}
file.conf 中,比如这种配置,这里的 fsp_tx_group 就是一个事务分组。一个 seata-server 可以管理多个事务分组。
2.通过事务分组如何找到后端集群?
A:首先程序中配置了事务分组(GlobalTransactionScanner 构造方法的 txServiceGroup 参数),程序会通过用户配置的配置中心去寻找 service.vgroup_mapping. 事务分组配置项,取得配置项的值就是 TC 集群的名称。拿到集群名称程序通过一定的前后缀+集群名称去构造服务名,各配置中心的服务名实现不同。拿到服务名去相应的注册中心去拉取相应服务名的服务列表,获得后端真实的 TC 服务列表。
3.为什么这么设计,不直接取服务名?
A:这里多了一层获取事务分组到映射集群的配置。这样设计后,事务分组可以作为资源的逻辑隔离单位,当发生故障时可以快速 failover。
4.我有 10 个微服务,那我要分 10 个组吗 ?
A:分组的含义就是映射到一套集群,所以你可以配一个分组也可以配置多个。如果你其他的微服务有独立发起事务可以配置多个,如果只是作为服务调用方参与事务那么没必要配置多个。
5.不知道分组的目的是什么?那不管什么情况我始终就一个分组有没问题?
A:没问题,分组是用于资源的逻辑隔离,多租户的概念。
6.是不是一个事务中所有的微服务都必须是同一组才行?
A:没有这个要求的。但是不同的分组需要映射到同一个集群上。
7.你说的集群是指 TC 集群吗?现在 TC 如何集群,我看配置里都是 default。
A:那个名字可以自己取,如果用文件形式你可以写多个地址列表,多台 server 以 DB 方式存储通过 DB 共享数据。如果用注册中心就可以自己发现,注册的时候定义了集群名。
备注:log_status 是 1,1 的是防御性的,是收到 globalrollback 回滚请求,但是不确定某个事务分支的本地事务是否已经执行完成了,这时事先插入一条 branchid 相同的数据,插入的假数据成功了,本地事务继续执行就会报主键冲突自动回滚。假如插入不成功说明表里有数据这个本地事务已经执行完成了,那么取出这条 undolog 数据做反向回滚操作
二. Seata 分布式事务原理解释
1. 相关概念
- XID:一个全局事务的唯一标识,由 ip:port:sequence 组成
- Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
- Transaction Manager ?: 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
- Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
2. 配置文件
seata 的配置文件入口为registry.conf查看代码ConfigurationFactory得知可以使用 seata.config.name 进行自定义配置文件,没有配置则默认使用registry.conf
static {String seataConfigName = System.getProperty("seata.config.name");if (null == seataConfigName) {seataConfigName = System.getenv("SEATA_CONFIG_NAME");}if (null == seataConfigName) {seataConfigName = "registry";}String envValue = System.getProperty("seataEnv");if (null == envValue) {envValue = System.getenv("SEATA_ENV");}CURRENT_FILE_INSTANCE = null == envValue ? new FileConfiguration(seataConfigName + ".conf") : new FileConfiguration(seataConfigName + "-" + envValue + ".conf");instance = null;}
在 registry 中可以指定具体配置的形式,这里使用默认的 file 形式。在 file.conf 中有 3 部分配置内容
- transport transport 部分的配置对应 NettyServerConfig 类,用于定义 Netty 相关的参数,TM、RM 与 seata-server 之间使用 Netty 进行通信。
transport {# tcp udt unix-domain-sockettype = "TCP"#NIO NATIVEserver = "NIO"#enable heartbeatheartbeat = true#thread factory for nettythread-factory {boss-thread-prefix = "NettyBoss"worker-thread-prefix = "NettyServerNIOWorker"server-executor-thread-prefix = "NettyServerBizHandler"share-boss-worker = falseclient-selector-thread-prefix = "NettyClientSelector"client-selector-thread-size = 1client-worker-thread-prefix = "NettyClientWorkerThread"# netty boss thread size,will not be used for UDTboss-thread-size = 1#auto default pin or 8worker-thread-size = 8}shutdown {# when destroy server, wait secondswait = 3}serialization = "seata"compressor = "none"
}
- service
service {#vgroup->rgroupvgroup_mapping.prex_tx_group = "default"#only support single node#配置Client连接TC的地址default.grouplist = "127.0.0.1:8091"#degrade current not supportenableDegrade = false#disabledisable = false#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanentmax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"
}
- client
client {
# RM接收TC的commit通知后缓冲上限async.commit.buffer.limit = 10000lock {retry.internal = 10retry.times = 30}report.retry.count = 5tm.commit.retry.count = 1tm.rollback.retry.count = 1
}
3. 启动 Server
启动成功输出 Server started
2019-11-27 12:53:59.089 INFO [main]io.seata.core.rpc.netty.AbstractRpcRemotingServer.start:156 -Server started ...
4. 启动 Client
对于 Spring boot 项目,启动运行 xxxApplication 的 main 方法即可,seata 的加载入口类位于
com.alibaba.cloud.seata.GlobalTransactionAutoConfiguration
@Configuration
@EnableConfigurationProperties({SeataProperties.class})
public class GlobalTransactionAutoConfiguration {private final ApplicationContext applicationContext;private final SeataProperties seataProperties;public GlobalTransactionAutoConfiguration(ApplicationContext applicationContext, SeataProperties seataProperties) {this.applicationContext = applicationContext;this.seataProperties = seataProperties;}@Beanpublic GlobalTransactionScanner globalTransactionScanner() {String applicationName = this.applicationContext.getEnvironment().getProperty("spring.application.name");String txServiceGroup = this.seataProperties.getTxServiceGroup();if (StringUtils.isEmpty(txServiceGroup)) {txServiceGroup = applicationName + "-seata-service-group";this.seataProperties.setTxServiceGroup(txServiceGroup);}return new GlobalTransactionScanner(applicationName, txServiceGroup);}
}可以看到支持一个配置项 SeataProperties,用于配置事务分组名称
spring.cloud.alibaba.seata.tx-service-group=prex_tx_group
如果不指定则用 spring.application.name+ -seata-service-group 生成一个名称,所以不指定 spring.application.name 启动会报错
@ConfigurationProperties("spring.cloud.alibaba.seata")
public class SeataProperties {private String txServiceGroup;public SeataProperties() {}public String getTxServiceGroup() {return this.txServiceGroup;}public void setTxServiceGroup(String txServiceGroup) {this.txServiceGroup = txServiceGroup;}
}
有了 applicationId 和 txServiceGroup 则创建 io.seata.spring.annotation.GlobalTransactionScanner 对象,主要看其中的 initClient 方法
private void initClient() {if (LOGGER.isInfoEnabled()) {LOGGER.info("Initializing Global Transaction Clients ... ");}if (!StringUtils.isNullOrEmpty(this.applicationId) && !StringUtils.isNullOrEmpty(this.txServiceGroup)) {//init TMTMClient.init(this.applicationId, this.txServiceGroup);if (LOGGER.isInfoEnabled()) {LOGGER.info("Transaction Manager Client is initialized. applicationId[" + this.applicationId + "] txServiceGroup[" + this.txServiceGroup + "]");}//init RMRMClient.init(this.applicationId, this.txServiceGroup);if (LOGGER.isInfoEnabled()) {LOGGER.info("Resource Manager is initialized. applicationId[" + this.applicationId + "] txServiceGroup[" + this.txServiceGroup + "]");}if (LOGGER.isInfoEnabled()) {LOGGER.info("Global Transaction Clients are initialized. ");}this.registerSpringShutdownHook();} else {throw new IllegalArgumentException("applicationId: " + this.applicationId + ", txServiceGroup: " + this.txServiceGroup);}}可以看到初始化了TMClient和RMClient,对于一个服务既可以是 TM 角色也可以是 RM 角色,至于什么时候是 TM 或者 RM 则要看在一次全局事务中@GlobalTransactional注解标注在哪。
Client 创建的结果是与 TC 的一个 Netty 连接,所以在启动日志中可以看到两个 Netty Channel,其中也标明了 transactionRole 分别为 TMROLE 和 RMROLE
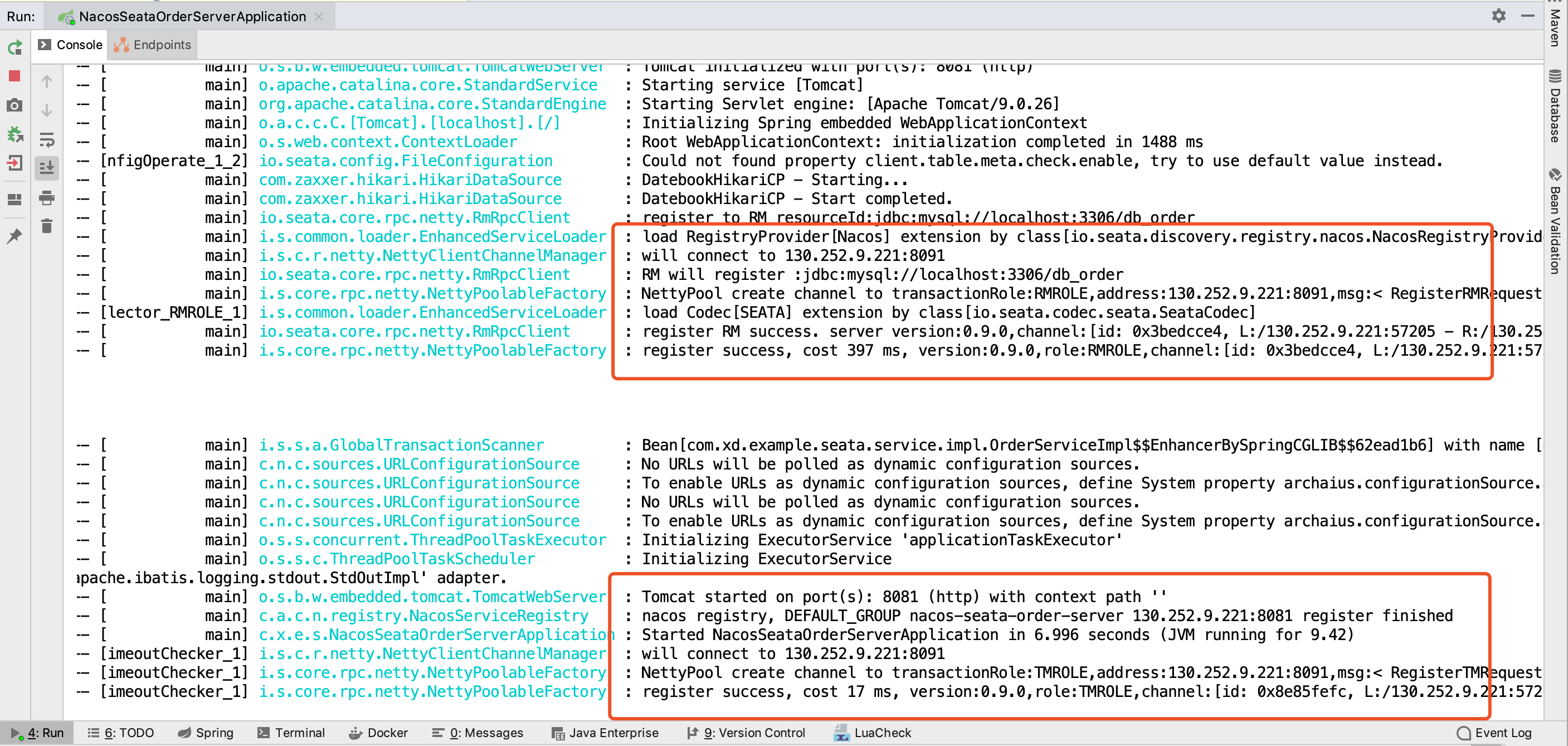
日志中可以看到创建连接后,发送了注册请求,然后得到了结果相应,RmRpcClient、TmRpcClient 成功实例化。
5. TM 处理流程
在本例中,TM 的角色是 nacos-seata-order-server,因为 nacos-seata-order-server 的 createOrder 方法标注了@GlobalTransactional
@Slf4j
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements IOrderService {@Autowiredprivate RemoteStorageService remoteStorageService;@Autowiredprivate RemoteAccountService remoteAccountService;@GlobalTransactional(name = "prex-create-order",rollbackFor = Exception.class)@Overridepublic void createOrder(Order order) {log.info("当前 XID: {}", RootContext.getXID());log.info("下单开始,用户:{},商品:{},数量:{},金额:{}", order.getUserId(), order.getProductId(), order.getCount(), order.getPayMoney());//创建订单order.setStatus(0);boolean save = save(order);log.info("保存订单{}", save ? "成功" : "失败");//远程调用库存服务扣减库存log.info("扣减库存开始");remoteStorageService.reduceCount(order.getProductId(), order.getCount());log.info("扣减库存结束");//远程调用账户服务扣减余额log.info("扣减余额开始");remoteAccountService.reduceBalance(order.getUserId(), order.getPayMoney());log.info("扣减余额结束");//修改订单状态为已完成log.info("修改订单状态开始");update(Wrappers.<Order>lambdaUpdate().set(Order::getStatus, 1).eq(Order::getUserId, order.getUserId()));log.info("修改订单状态结束");log.info("下单结束");}
}
我们只需要使用一个 @GlobalTransactional 注解在业务方法上就可以实现分布式事务
@GlobalTransactionalpublic void purchase(String userId, String commodityCode, int orderCount) {......}
不涉及到分布式事务的场景下,我们使用 spring 管理本地事务使用@Transactional注解,Seata 使用的是@GlobalTransactional注解,那么我们就从@GlobalTransactional注解入手,
它是在 GlobalTransactionalInterceptor 中被拦截处理
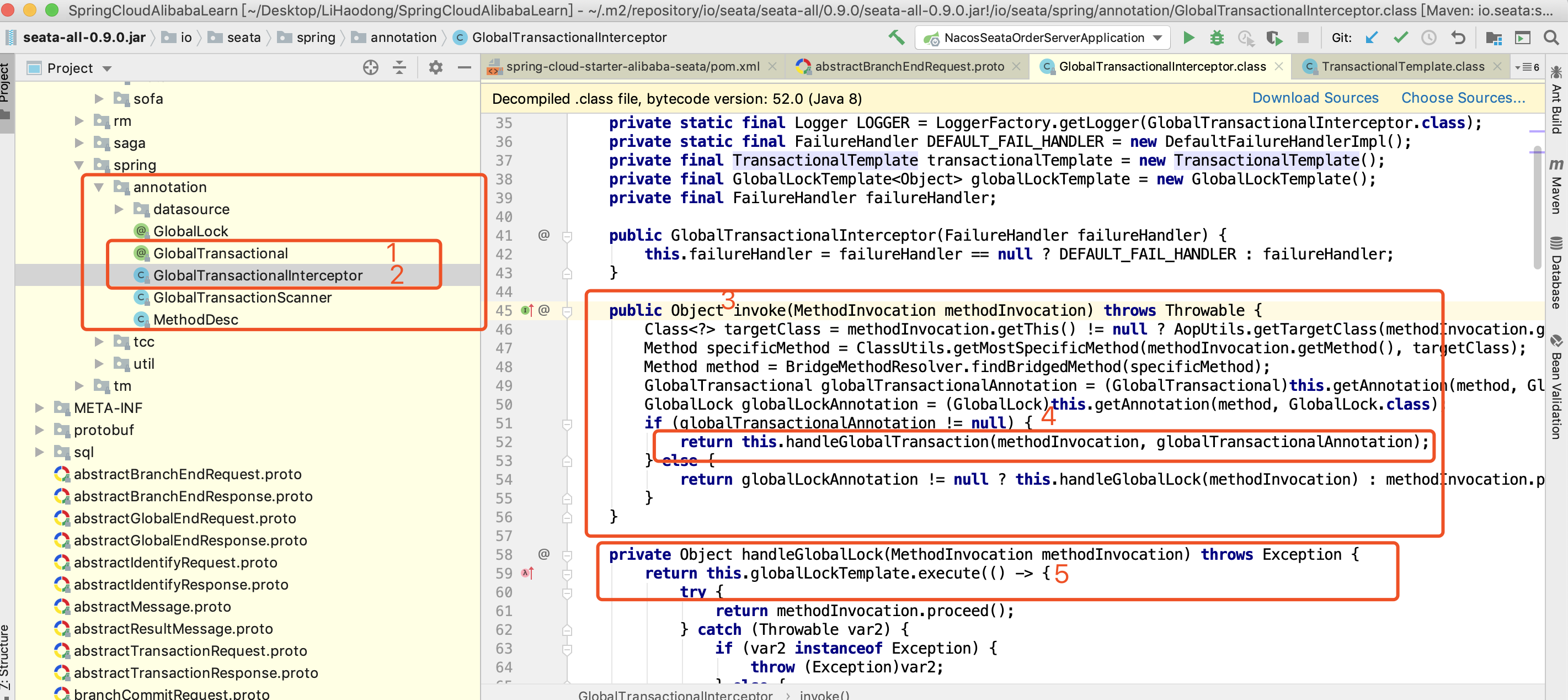
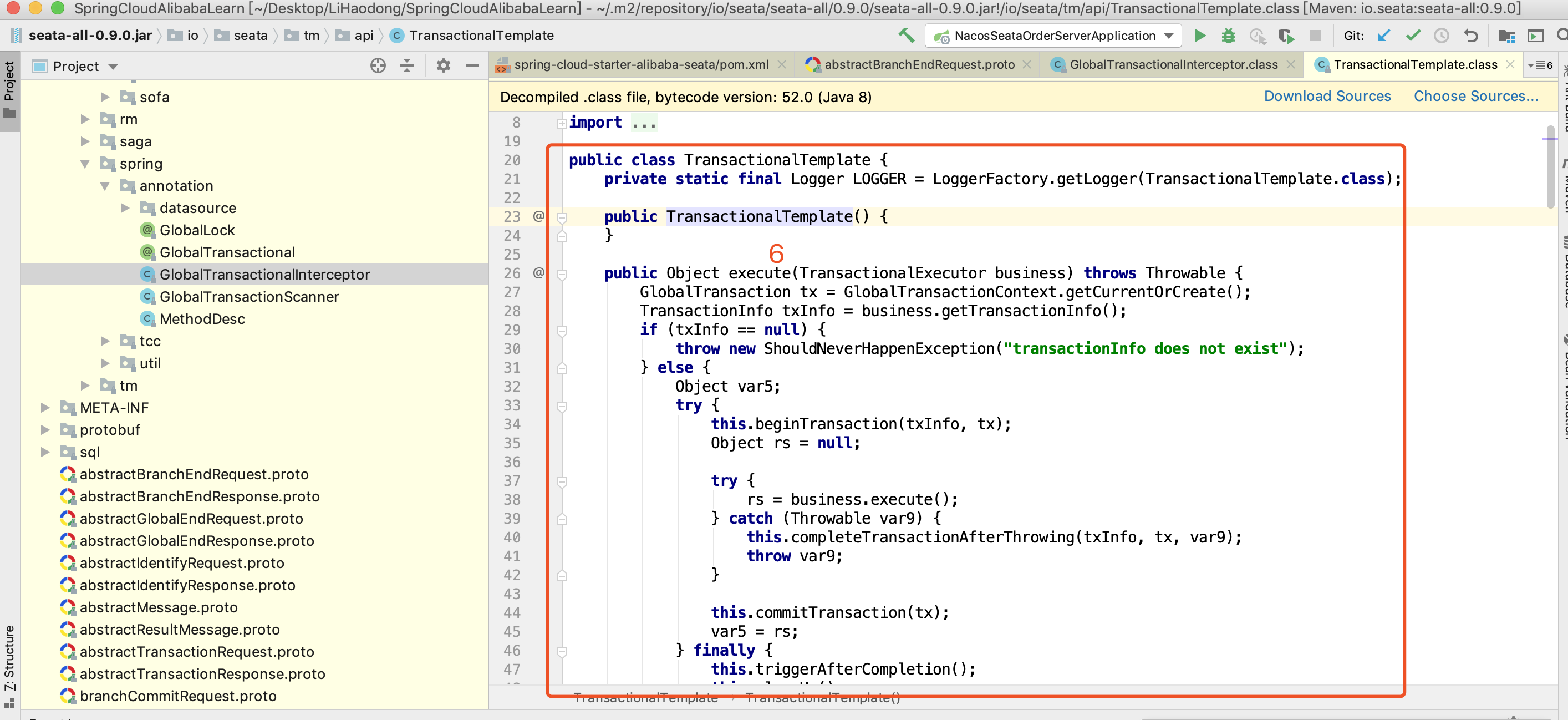
最终执行的是TransactionalTemplate方法
public class TransactionalTemplate {public Object execute(TransactionalExecutor business) throws Throwable {// 1. 获取当前全局事务实例或创建新的实例GlobalTransaction tx = GlobalTransactionContext.getCurrentOrCreate();//1.1 获取事务信息TransactionInfo txInfo = business.getTransactionInfo();if (txInfo == null) {throw new ShouldNeverHappenException("transactionInfo does not exist");} else {Object var5;try {// 2. 开启全局事务this.beginTransaction(txInfo, tx);Object rs = null;try {// 调用业务服务rs = business.execute();} catch (Throwable var9) {//3.回滚所需的业务异常。 this.completeTransactionAfterThrowing(txInfo, tx, var9);throw var9;}// 没有异常 提交事务this.commitTransaction(tx);var5 = rs;} finally {// 清除this.triggerAfterCompletion();this.cleanUp();}return var5;}}}
这个方法好像是整个全局分布式事务的流程
- 开始分布式事务
这里最终会调用 DefaultGlobalTransaction 的 begin 方法
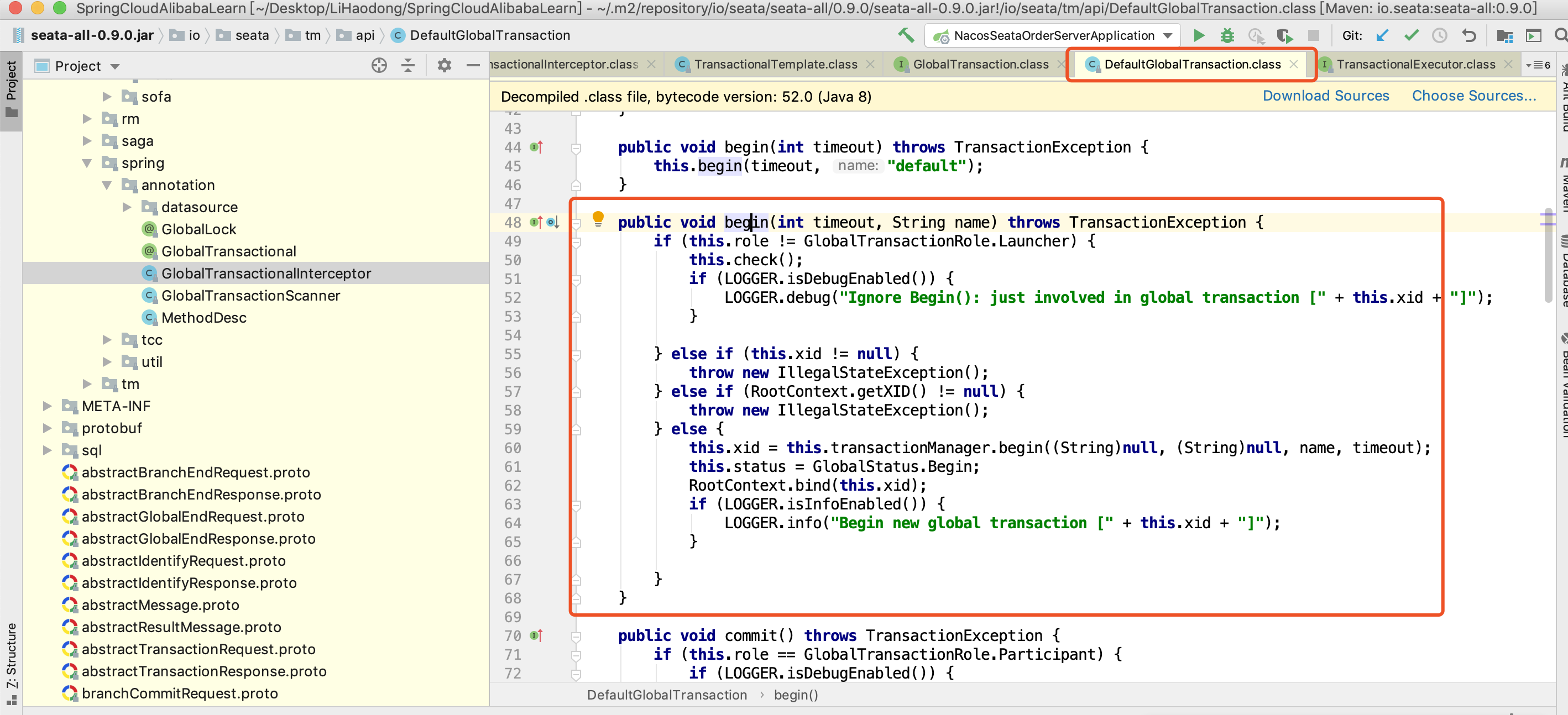
public void begin(int timeout, String name) throws TransactionException {// a//此处的角色判断有关键的作用//表明当前是全局事务的发起者(Launcher)还是参与者(Participant)//如果在分布式事务的下游系统方法中也加上GlobalTransactional注解//那么它的角色就是Participant,即会忽略后面的begin就退出了//而判断是发起者(Launcher)还是参与者(Participant)是根据当前上下文是否已存在XID来判断//没有XID的就是Launcher,已经存在XID的就是Participantif (this.role != GlobalTransactionRole.Launcher) {this.check();if (LOGGER.isDebugEnabled()) {LOGGER.debug("Ignore Begin(): just involved in global transaction [" + this.xid + "]");}} else if (this.xid != null) {throw new IllegalStateException();} else if (RootContext.getXID() != null) {throw new IllegalStateException();} else {// b 利用TmRpcClient 之前建立好的channel给tc发送请求,获取获取TC返回的全局事务XIDthis.xid = this.transactionManager.begin((String)null, (String)null, name, timeout);this.status = GlobalStatus.Begin;// cRootContext.bind(this.xid);if (LOGGER.isInfoEnabled()) {LOGGER.info("Begin new global transaction [" + this.xid + "]");}}}
- a.判断是不是分布式事务的发起者,GlobalTransactionRole.Launcher 就是事务发起者角色,如果不是就直接 return
- b.这个方法主要利用 TmRpcClient 之前建立好的 channel 给 tc 发送请求,获取全局事务 id
- c.将获取到到全局事务 id 放到 seata 上下文中
- 处理方法本身的业务逻辑
- 处理业务逻辑的时候报错了,则进行事务回滚,并抛出异常
DefaultTransactionManager 负责 TM 与 TC 通讯,发送 begin、commit、rollback 指令
至此拿到 TC 返回的 XID 一个全局事务就开启了,日志中也反应了上述流程
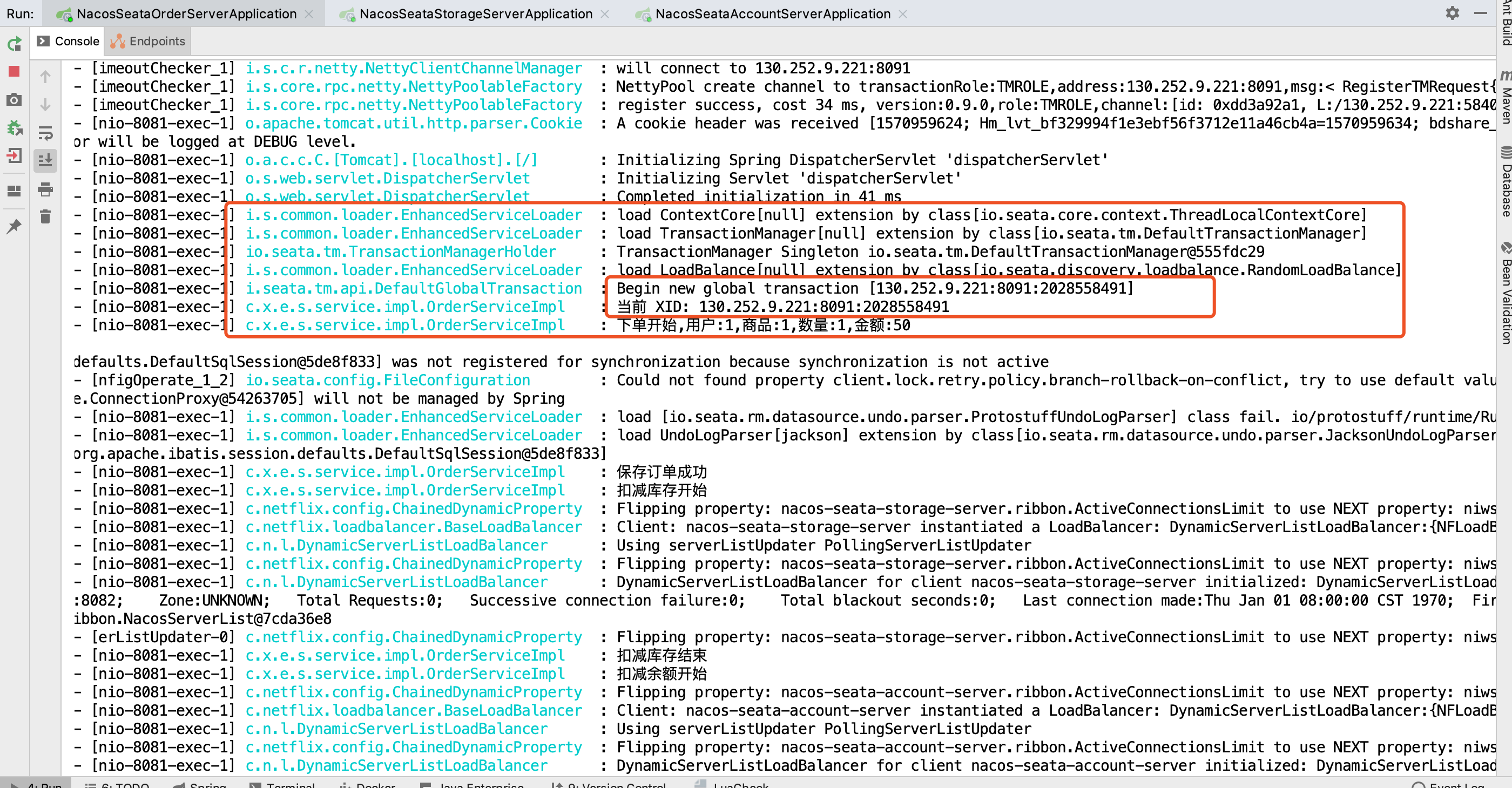
全局事务创建后,就开始执行 business.execute(),即业务代码 orderService.createOrder(order);;进入 RM 处理流程
6. RM 处理流程
@RestController
@RequestMapping("/account")
public class AccountController {@Autowiredprivate IAccountService accountService;@PostMapping("/reduceBalance")@ResponseBodypublic R reduceBalance(@RequestParam("userId") Integer userId, @RequestParam("money") BigDecimal money) throws Exception {return R.builder().success(accountService.reduceBalance(userId, money)).msg("扣款成功").build();}
}
account 的接口和 service 方法并未出现 seata 相关的代码和注解,那么它是如何加入到这次全局事务中的呢,答案是 ConnectionProxy 中,这也是前面说为什么必须要使用 DataSourceProxy 的原因,通过 DataSourceProxy 才能在业务代码的事务提交时,seata 通过这个切入点,来给 TC 发送 rm 的处理结果
由于业务代码本身的事务提交被 ConnectionProxy 代理,所以在提交本地事务时,实际执行的是 ConnectionProxy 的 commit 方法
public class ConnectionProxy extends AbstractConnectionProxy {public void commit() throws SQLException {try {LOCK_RETRY_POLICY.execute(() -> {this.doCommit();return null;});} catch (SQLException var2) {throw var2;} catch (Exception var3) {throw new SQLException(var3);}}private void doCommit() throws SQLException {//如果当前是全局事务,则执行全局事务的提交//判断是不是全局事务,就是看当前上下文是否存在XIDif (this.context.inGlobalTransaction()) {this.processGlobalTransactionCommit();} else if (this.context.isGlobalLockRequire()) {this.processLocalCommitWithGlobalLocks();} else {this.targetConnection.commit();}}private void processGlobalTransactionCommit() throws SQLException {try {//首先是向TC注册RM,拿到TC分配的branchIdthis.register();} catch (TransactionException var2) {this.recognizeLockKeyConflictException(var2, this.context.buildLockKeys());}try {if (this.context.hasUndoLog()) {//写入undolog UndoLogManagerFactory.getUndoLogManager(this.getDbType()).flushUndoLogs(this);}//提交本地事务,可以看到写入undolog和业务数据是在同一个本地事务中this.targetConnection.commit();} catch (Throwable var3) {LOGGER.error("process connectionProxy commit error: {}", var3.getMessage(), var3);//向TC发送rm的事务处理失败的通知this.report(false);throw new SQLException(var3);}//向TC发送rm的事务处理成功的通知this.report(true);this.context.reset();}// 注册RM,构建request通过netty向TC发送指令//将返回的branchId存在上下文中private void register() throws TransactionException {Long branchId = DefaultResourceManager.get().branchRegister(BranchType.AT, this.getDataSourceProxy().getResourceId(), (String)null, this.context.getXid(), (String)null, this.context.buildLockKeys());this.context.setBranchId(branchId);}
}
- 获取 business-service 传来的 XID
- 绑定 XID 到当前上下文中
- 执行业务逻辑 sql
- 向 TC 创建本次 RM 的 Netty 连接
- 向 TC 发送分支事务的相关信息
- 获得 TC 返回的 branchId
- 记录 Undo Log 数据
向 TC 发送本次事务 PhaseOne 阶段的处理结果 - 从当前上下文中解绑 XID
其中第 1 步和第 9 步,是在 FescarHandlerInterceptor 中完成的,该类并不属于 seata,而是 spring-cloud-alibaba-seata 中对 feign、rest 支持的实现。bind 和 unbind XID 到上下文中。到这里 RM 完成了 PhaseOne 阶段的工作,接着看 PhaseTwo 阶段的处理逻辑
7. 事务提交
由于这次请求是正常流程无异常的,所以分支事务会正常 commit。
在 storage-service 启动时创建了与 TC 通讯的 Netty 连接,TC 在获取各 RM 的汇报结果后,就会给各 RM 发送 commit 或 rollback 的指令

从日志中可以看到
- 收到 XID=130.252.9.221:8091:2028558491,branchId=2028558493 的 commit 通知
- 执行 commit 动作
- 将 commit 结果发送给 TC,branchStatus 为 PhaseTwo_Committed
具体看下执行 commit 的过程,在 AbstractRMHandler 类的 doBranchCommit 方法之前是接收 TC 消息包装处理路由的过程
io.seata.rm.AbstractRMHandler
//拿到通知的xid、branchId等关键参数
//然后调用RM的branchCommit
protected void doBranchCommit(BranchCommitRequest request, BranchCommitResponse response) throws TransactionException {String xid = request.getXid();long branchId = request.getBranchId();String resourceId = request.getResourceId();String applicationData = request.getApplicationData();if (LOGGER.isInfoEnabled()) {LOGGER.info("Branch committing: " + xid + " " + branchId + " " + resourceId + " " + applicationData);}BranchStatus status = this.getResourceManager().branchCommit(request.getBranchType(), xid, branchId, resourceId, applicationData);response.setXid(xid);response.setBranchId(branchId);response.setBranchStatus(status);if (LOGGER.isInfoEnabled()) {LOGGER.info("Branch commit result: " + status);}}最终会将 branceCommit 的请求调用到 AsyncWorker 的 branchCommit 方法。AsyncWorker 的处理方式是 seata 架构的一个关键部分,大部分事务都是会正常提交的,所以在 PhaseOne 阶段就已经结束了,这样就可以将锁最快的释放。PhaseTwo 阶段接收 commit 的指令后,异步处理即可。将 PhaseTwo 的时间消耗排除在一次分布式事务之外。
io.seata.rm.datasource.AsyncWorker
public class AsyncWorker implements ResourceManagerInbound {private static final Logger LOGGER = LoggerFactory.getLogger(AsyncWorker.class);private static final int DEFAULT_RESOURCE_SIZE = 16;private static final int UNDOLOG_DELETE_LIMIT_SIZE = 1000;private static int ASYNC_COMMIT_BUFFER_LIMIT = ConfigurationFactory.getInstance().getInt("client.async.commit.buffer.limit", 10000);private static final BlockingQueue<AsyncWorker.Phase2Context> ASYNC_COMMIT_BUFFER;private static ScheduledExecutorService timerExecutor;public AsyncWorker() {}public BranchStatus branchCommit(BranchType branchType, String xid, long branchId, String resourceId, String applicationData) throws TransactionException {if (!ASYNC_COMMIT_BUFFER.offer(new AsyncWorker.Phase2Context(branchType, xid, branchId, resourceId, applicationData))) {LOGGER.warn("Async commit buffer is FULL. Rejected branch [" + branchId + "/" + xid + "] will be handled by housekeeping later.");}return BranchStatus.PhaseTwo_Committed;}//通过一个定时任务消费list中的待提交XIDpublic synchronized void init() {LOGGER.info("Async Commit Buffer Limit: " + ASYNC_COMMIT_BUFFER_LIMIT);timerExecutor = new ScheduledThreadPoolExecutor(1, new NamedThreadFactory("AsyncWorker", 1, true));timerExecutor.scheduleAtFixedRate(new Runnable() {public void run() {try {AsyncWorker.this.doBranchCommits();} catch (Throwable var2) {AsyncWorker.LOGGER.info("Failed at async committing ... " + var2.getMessage());}}}, 10L, 1000L, TimeUnit.MILLISECONDS);}private void doBranchCommits() {if (ASYNC_COMMIT_BUFFER.size() != 0) {HashMap mappedContexts;AsyncWorker.Phase2Context commitContext;Object contextsGroupedByResourceId;for(mappedContexts = new HashMap(16); !ASYNC_COMMIT_BUFFER.isEmpty(); ((List)contextsGroupedByResourceId).add(commitContext)) {commitContext = (AsyncWorker.Phase2Context)ASYNC_COMMIT_BUFFER.poll();contextsGroupedByResourceId = (List)mappedContexts.get(commitContext.resourceId);if (contextsGroupedByResourceId == null) {contextsGroupedByResourceId = new ArrayList();mappedContexts.put(commitContext.resourceId, contextsGroupedByResourceId);}}Iterator var28 = mappedContexts.entrySet().iterator();while(true) {//一次定时任务取出ASYNC_COMMIT_BUFFER中的所有待办数据//以resourceId作为key分组待办数据,resourceId就是一个数据库的连接url//在前面的日志中可以看到,目的是为了覆盖应用的多数据源问题if (var28.hasNext()) {Entry<String, List<AsyncWorker.Phase2Context>> entry = (Entry)var28.next();Connection conn = null;try {DataSourceProxy dataSourceProxy;try { //根据resourceId获取数据源以及连接DataSourceManager resourceManager = (DataSourceManager)DefaultResourceManager.get().getResourceManager(BranchType.AT);dataSourceProxy = resourceManager.get((String)entry.getKey());if (dataSourceProxy == null) {throw new ShouldNeverHappenException("Failed to find resource on " + (String)entry.getKey());}conn = dataSourceProxy.getPlainConnection();} catch (SQLException var26) {LOGGER.warn("Failed to get connection for async committing on " + (String)entry.getKey(), var26);continue;}List<AsyncWorker.Phase2Context> contextsGroupedByResourceId = (List)entry.getValue();Set<String> xids = new LinkedHashSet(1000);Set<Long> branchIds = new LinkedHashSet(1000);Iterator var9 = contextsGroupedByResourceId.iterator();while(var9.hasNext()) {AsyncWorker.Phase2Context commitContext = (AsyncWorker.Phase2Context)var9.next();xids.add(commitContext.xid);branchIds.add(commitContext.branchId);int maxSize = xids.size() > branchIds.size() ? xids.size() : branchIds.size();if (maxSize == 1000) {try {UndoLogManagerFactory.getUndoLogManager(dataSourceProxy.getDbType()).batchDeleteUndoLog(xids, branchIds, conn);} catch (Exception var25) {LOGGER.warn("Failed to batch delete undo log [" + branchIds + "/" + xids + "]", var25);}xids.clear();branchIds.clear();}}if (!CollectionUtils.isEmpty(xids) && !CollectionUtils.isEmpty(branchIds)) {try {//执行undolog的处理,即删除xid、branchId对应的记录 UndoLogManagerFactory.getUndoLogManager(dataSourceProxy.getDbType()).batchDeleteUndoLog(xids, branchIds, conn);} catch (Exception var24) {LOGGER.warn("Failed to batch delete undo log [" + branchIds + "/" + xids + "]", var24);}continue;}} finally {if (conn != null) {try {conn.close();} catch (SQLException var23) {LOGGER.warn("Failed to close JDBC resource while deleting undo_log ", var23);}}}return;}return;}}}public BranchStatus branchRollback(BranchType branchType, String xid, long branchId, String resourceId, String applicationData) throws TransactionException {throw new NotSupportYetException();}static {ASYNC_COMMIT_BUFFER = new LinkedBlockingQueue(ASYNC_COMMIT_BUFFER_LIMIT);}}
所以对于 commit 动作的处理,RM 只需删除 xid、branchId 对应的 undolog 既可
8. 事务回滚
对于 rollback 场景的触发有两种情况:
- 分支事务处理异常,即
io.seata.rm.datasource.ConnectionProxy中 report(false)的情况 - TM 捕获到下游系统上抛的异常,即发起全局事务标有@GlobalTransactional 注解的方法捕获到的异常。在前面
io.seata.tm.api.TransactionalTemplate类的 execute 模版方法中,对 business.execute()的调用进行了 catch,catch 后会调用 rollback,由 TM 通知 TC 对应 XID 需要回滚事务
public void rollback() throws TransactionException {//只有Launcher能发起这个rollbackif (this.role == GlobalTransactionRole.Participant) {// Participant has no responsibility of committingif (LOGGER.isDebugEnabled()) {LOGGER.debug("Ignore Rollback(): just involved in global transaction [" + this.xid + "]");}} else if (this.xid == null) {throw new IllegalStateException();} else {int retry = ROLLBACK_RETRY_COUNT;try {while(retry > 0) {try {this.status = this.transactionManager.rollback(this.xid);break;} catch (Throwable var6) {LOGGER.error("Failed to report global rollback [{}],Retry Countdown: {}, reason: {}", new Object[]{this.getXid(), retry, var6.getMessage()});--retry;if (retry == 0) {throw new TransactionException("Failed to report global rollback", var6);}}}} finally {if (RootContext.getXID() != null && this.xid.equals(RootContext.getXID())) {RootContext.unbind();}}if (LOGGER.isInfoEnabled()) {LOGGER.info("[" + this.xid + "] rollback status:" + this.status);}}}
TC 汇总后向参与者发送 rollback 指令,RM 在 AbstractRMHandler 类的 doBranchRollback 方法中接收这个 rollback 的通知
protected void doBranchRollback(BranchRollbackRequest request, BranchRollbackResponse response) throws TransactionException {String xid = request.getXid();long branchId = request.getBranchId();String resourceId = request.getResourceId();String applicationData = request.getApplicationData();if (LOGGER.isInfoEnabled()) {LOGGER.info("Branch Rollbacking: " + xid + " " + branchId + " " + resourceId);}BranchStatus status = this.getResourceManager().branchRollback(request.getBranchType(), xid, branchId, resourceId, applicationData);response.setXid(xid);response.setBranchId(branchId);response.setBranchStatus(status);if (LOGGER.isInfoEnabled()) {LOGGER.info("Branch Rollbacked result: " + status);}}
然后将 rollback 请求传递到 io.seata.rm.datasource.DataSourceManager 类的 branchRollback 方法
public BranchStatus branchRollback(BranchType branchType, String xid, long branchId, String resourceId, String applicationData) throws TransactionException {//根据resourceId获取对应的数据源DataSourceProxy dataSourceProxy = this.get(resourceId);if (dataSourceProxy == null) {throw new ShouldNeverHappenException();} else {try {UndoLogManagerFactory.getUndoLogManager(dataSourceProxy.getDbType()).undo(dataSourceProxy, xid, branchId);} catch (TransactionException var9) {if (LOGGER.isInfoEnabled()) {LOGGER.info("branchRollback failed reason [{}]", var9.getMessage());}if (var9.getCode() == TransactionExceptionCode.BranchRollbackFailed_Unretriable) {return BranchStatus.PhaseTwo_RollbackFailed_Unretryable;}return BranchStatus.PhaseTwo_RollbackFailed_Retryable;}return BranchStatus.PhaseTwo_Rollbacked;}}
最终会执行 io.seata.rm.datasource.undo.UndoLogManager 类的 undo 方法,这个 undo,其实就是通过 undolog 来反向生成一个回滚 sql,然后执行这个回滚 sql 来达到 rollback 的效果
public void undo(DataSourceProxy dataSourceProxy, String xid, long branchId) throws TransactionException {Connection conn = null;ResultSet rs = null;PreparedStatement selectPST = null;boolean originalAutoCommit = true;while(true) {try {conn = dataSourceProxy.getPlainConnection();if (originalAutoCommit =conn.getAutoCommit()) {// 整个撤消过程应在本地事务中运行conn.setAutoCommit(false);}selectPST = conn.prepareStatement(SELECT_UNDO_LOG_SQL);selectPST.setLong(1, branchId);selectPST.setString(2, xid);rs = selectPST.executeQuery();boolean exists = false;while(rs.next()) {exists = true;int state = rs.getInt("log_status");if (!canUndo(state)) {if (LOGGER.isInfoEnabled()) {LOGGER.info("xid {} branch {}, ignore {} undo_log", new Object[]{xid, branchId, state});}return;}String contextString = rs.getString("context");Map<String, String> context = this.parseContext(contextString);Blob b = rs.getBlob("rollback_info");byte[] rollbackInfo = BlobUtils.blob2Bytes(b);String serializer = context == null ? null : (String)context.get("serializer");UndoLogParser parser = serializer == null ? UndoLogParserFactory.getInstance() : UndoLogParserFactory.getInstance(serializer);BranchUndoLog branchUndoLog = parser.decode(rollbackInfo);try {setCurrentSerializer(parser.getName());List<SQLUndoLog> sqlUndoLogs = branchUndoLog.getSqlUndoLogs();if (sqlUndoLogs.size() > 1) {Collections.reverse(sqlUndoLogs);}Iterator var19 = sqlUndoLogs.iterator();while(var19.hasNext()) {SQLUndoLog sqlUndoLog = (SQLUndoLog)var19.next();TableMeta tableMeta = TableMetaCacheFactory.getTableMetaCache(dataSourceProxy).getTableMeta(dataSourceProxy, sqlUndoLog.getTableName());sqlUndoLog.setTableMeta(tableMeta);AbstractUndoExecutor undoExecutor = UndoExecutorFactory.getUndoExecutor(dataSourceProxy.getDbType(), sqlUndoLog);undoExecutor.executeOn(conn);}} finally {removeCurrentSerializer();}}if (exists) {this.deleteUndoLog(xid, branchId, conn);conn.commit();if (LOGGER.isInfoEnabled()) {LOGGER.info("xid {} branch {}, undo_log deleted with {}", new Object[]{xid, branchId, AbstractUndoLogManager.State.GlobalFinished.name()});break;}} else {this.insertUndoLogWithGlobalFinished(xid, branchId, UndoLogParserFactory.getInstance(), conn);conn.commit();if (LOGGER.isInfoEnabled()) {LOGGER.info("xid {} branch {}, undo_log added with {}", new Object[]{xid, branchId, AbstractUndoLogManager.State.GlobalFinished.name()});break;}}return;} catch (SQLIntegrityConstraintViolationException var44) {if (LOGGER.isInfoEnabled()) {LOGGER.info("xid {} branch {}, undo_log inserted, retry rollback", xid, branchId);}} catch (Throwable var45) {if (conn != null) {try {conn.rollback();} catch (SQLException var42) {LOGGER.warn("Failed to close JDBC resource while undo ... ", var42);}}throw new BranchTransactionException(TransactionExceptionCode.BranchRollbackFailed_Retriable, String.format("Branch session rollback failed and try again later xid = %s branchId = %s %s", xid, branchId, var45.getMessage()), var45);} finally {try {if (rs != null) {rs.close();}if (selectPST != null) {selectPST.close();}if (conn != null) {if (originalAutoCommit) {conn.setAutoCommit(true);}conn.close();}} catch (SQLException var41) {LOGGER.warn("Failed to close JDBC resource while undo ... ", var41);}}}}
- 根据 xid 和 branchId 查找 PhaseOne 阶段提交的 undolog
- 如果找到了就根据 undolog 中记录的数据生成回放 sql 并执行,即还原 PhaseOne 阶段修改的数据
- 第 2 步处理完后,删除该条 undolog 数据
- 如果第 1 步没有找到对应的 undolog,就插入一条状态为 GlobalFinished 的 undolog.
出现没找到的原因可能是 PhaseOne 阶段的本地事务异常了,导致没有正常写入。因为 xid 和 branchId 是唯一索引,所以第 4 步的插入,可以防止 PhaseOne 阶段后续又写入成功,那么 PhaseOne 阶段就会异常,这样业务数据也是没有提交成功的,数据最终是回滚了的效果
参考资料:
http://seata.io/zh-cn/
https://url.cn/51xbqna
https://url.cn/5QaYJWh