《Latent Opinions Transfer Network for Target-Oriented Opinion Words Extraction》阅读笔记
AAAI 2020
1. 背景
从2019年作者Fan在论文 Target-oriented Opinion Words Extraction with Target-fused Neural Sequence Labeling 中定义了 TOWE(Target-oriented Opinion Words Extraction)任务,旨在从评论文本中抽取给定意见目标(opinion target)对应的观点词(opinion words)。
考虑到标注大量细粒度情感分析数据是耗时且困难的,这篇论文提出了从迁移学习的角度出发,提出潜在观点迁移网络,从资源丰富的评论情感分类中迁移潜在的观点知识来提升TOWE。
添加了一个评论情感分类模块,这个模块运行了两次,第一次是模型训练之前,先用情感分类模块训练大型的评论数据集,预训练结束后,情感分类模块中所有的参数固定。第二次运行是在训练时,用来获取输入的sentence中的意见词。
2. 介绍
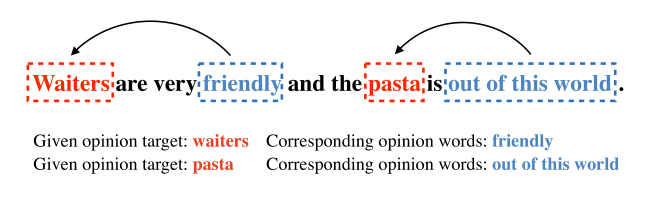
其中红色的表示opinion target 也就是我们平常说的aspect term。蓝色的情感词,箭头表示的是情感词指向的意见目标。
由于缺乏注释数据,TOWE数据集很少。注释者很难识别一个句子中所有的方面并定位到相应的意见词。所以这就限制了模型的有效性。
相比之下,有很多情感分类的数据集可以获取,里面包含了实质性的观点信息和语义模式。因此,作者建议把潜在的观点知识转移到TOWE中。但是还是有以下两个挑战:
- 情感分类数据集中的意见词是没有注释的,转移之前要找到他们。
- 因为评论的情感分类不考虑目标信息,因此获得的潜在意见信息是整个句子的,且与目标无关(句子级情感分类模块,所以不考虑目标信息)。因此这些信息不能直接被TOWE使用。
提出了Latent Opinions Transfer Network (LOTN)模型。
对于第一个问题,我们首先在评论情绪分类数据集上训练一个基于注意力的Bi-LSTM,通过概率权重提取可能的意见词(情感词)。第二个问题,提出了一种有效的转换方法(设置距离权重),将情感分类模型中所有单词的全局注意力分布转化为潜在的目标相关的观点词。
最后,我们通过辅助学习信号将这些捕获函数整合到我们的模型中。另外,我们加入了预训练模型的编码器,进一步引导TOWE模型学习潜在观点,证明了该方法的有效性。
主要贡献包括:
- 在解决注释数据不足的问题上,作者首次提出将潜在的观点知识从资源丰富的评论情绪分类数据集转移到TOWE的低资源任务中。
- 为了有效地传递意见信息,我们提出了一种新的模型,从情感分类模型中提取潜在的意见词,并通过辅助学习信号将其整合到TOWE中。
3. 模型
整理了一下模型的思路:首先,通过评论情感分类模块,使用Yelp等大型评论数据集进行训练,训练结束后,情感分类模块所有参数保持不变(这里体现了迁移学习思想,使用其他模块的数据集来训练模型)。其次,提出了模型LOTN,在模型运行时,同一个句子分别输入TOWE模块和情感分类模块,情感分类模块通过基于注意力机制的bilstm找到可能存在的意见词(目标无关)。提出了一种转移方法识别潜在的目标相关的意见词。又提出了一种辅助学习方法将识别到的潜在目标相关的意见词转移到TOWE中。最后通过解码层进行序列标记任务。
3.1 TOWE问题重述
给定一个评论S = { w1 ,w2,…wt,…,wn},它是由一个意见目标wt和n个词组成的。使用{BIO}进行标记。

其中下划线表示意见目标。
3.2 训练前情绪分类模型(固定参数)
评论情绪分类(句子级)目的是检测评论文本的总体的情绪极性。
给定了一个评论序列,S = { s1 ,s2…,sm},通过word embedding 映射成向量表示{ w1 ,w2…wm},然后利用Bi-LSTM网络对单词表示{ w1 ,w2…wm}进行编码,生成上下文表示{hsc1,hsc2,…,hscm}。
注意机制被用来捕捉潜在的和全局的意见词。hsci的注意力权重ai被定义为:
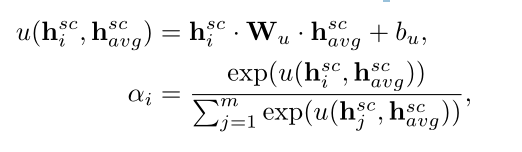
其中 hscavg 表示为所有隐藏状态的平均值,u()进行线性变化,转化为一个数,好计算注意力权重。下面是 hscavg 的计算过程:
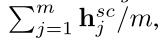
评论表示 rsc 是所有隐藏状态的加权和:
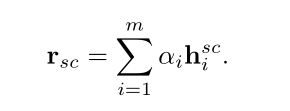
然后把 rsc 输入到一个线性层和softmax层来预测评论的情绪标签(积极,消极,中性)。我们通过最小化预测的情绪分布与真实情况之间的交叉熵损失来训练情绪分类模型。预训练结束后,情感分类模型中的所有参数都是固定的。
3.3 潜在意见转移网络(LOTN)

LOTN主要分为两部分,第一部分是TOWE模块,即基于位置嵌入的Bi-LSTM,第二部分是经过训练的情感分类模块,即基于注意力的Bi-LSTM。LOTN通过两种不同的方法将潜在的观点从情感分类模块转移到TOWE模块。
首先,预训练情感分类模块的BiLSTM层包含大量隐含的观点信息和语义模式。我们将这些信息整合到TOWE模块的编码层,引入外部意见知识。
其次,因为情感分类过程没有考虑目标的信息,所以预训练模块捕捉到的潜在观点词具有全局性、目标无关性。为了解决这个问题,提出了一个启发式转化方法,通过考虑目标和其他词的位置信息,将全局注意力权重转化为目标相关词,然后通过一个辅助学习信号合并到TOWE中。
3.3.1 基于位置嵌入的Bi-LSTM
给定一个句子 s={ w1 ,w2…wn} ,其中包含方面词 wt 。
首先生成句子中每个单词到目标词的相对距离,记为距离索引 li

然后通过通过距离索引去位置嵌入表 Epos ∈RL*d1 中获得位置嵌入,其中d1是嵌入维度,L是最大位置索引。
另外作者还是用了一个单词嵌入表 Eemb ∈R|V|*d2 获得词的语义表示。
每个单词 wi 的表示 ei 由字向量和对应该位置的位置向量串联而成:
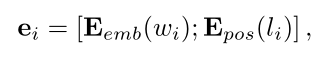
“;”表示的是串联运算。
最后通过Bi-LSTM捕捉每个单词的上下文信息:
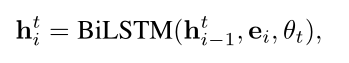
θt 是Bi-LSTM中的参数。
在基本的模型中,上下文表示 hit 可以用来预测给定目标的观点词(情感词)。
3.3.2 Transferring Pretrained Encoder(传输预训练编码器)
为了转移潜在的观点知识,将任务的句子s输入到预训练的情绪分类模块,生成对应的隐藏状态 {hsc1,hsc2,…,hscm} 和注意力权重 {a1,a2,…,an} 。
从语义层面上看,预训练情绪分类模型的编码器包含了大量的隐含意见信息。通过连接把两个隐藏状态进行整合。
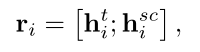
hisc 将句子s输入到情感分类模块得到的隐藏状态(包含了情感分类模块丰富的语义信息), hit 是通过基于位置嵌入的BILSTM得到的隐藏状态(包含了上下文信息)
所有这里的 ri 即包含了任务特定的上下文信息,也包含了来自情感分类模块的外部opinion知识。
3.3.3 转移潜在的观点词(情感词)
提出了两种方法:
- Transformation Method(识别潜在的目的相关的意见词)
- 辅助学习信号(将识别到的意见词转移到TOWE模块)
3.3.3.1 Transformation Method
情感分类模块中的注意力机制以概率权重的方式捕捉潜在的意见词(情感词),但是捕捉到的目标是全局的和目标无关的。
直观上来看,更接近意见目标的词更有可能成为目标的意见词(个人感觉使用距离权重的方法不是很严谨,)。因此,我们通过目标和相关距离权重 ci 将目标信息引入到注意分布中:
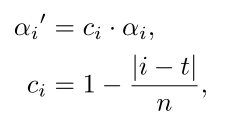
n 是输入句子的长度,ai 表示的是情感分类模块计算出的注意力权重,t表示的是opinion target 在文中的位置。 |i-t| 表示的是单词 wi 与意见目标 wt 之间的绝对距离。距离越近,权重越大。
为了重新获得概率注意力分布,进行归一化处理:
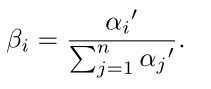
设置一个阈值 1/n 。从情感分类的角度看,如果大于阈值则表示这是一个潜在的,目标相关的观点词。
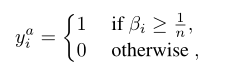
3.3.3.2 辅助学习信号
yia 是一个伪标签(不是最终的结果),代表情感分类模块中的观点知识,我们通过辅助学习信号将这些潜在的观点知识整合到TOWE模块中,这里的 La 就表示的是辅助学习信号。
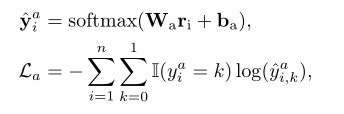
其中 Wa 和 ba 分别是权重矩阵和偏差矩阵,这里的 yia 冒 表示的是预测概率。Ⅱ(・)是指示函数(在这里 yia 用0或者1,表示是否是潜在的目的相关情感词)。LONE通过优化辅助损失La来包含这些潜在的观点知识。有助于TOWE更好地解码目标的意见信息(通过缩小损失函数,不断优化权重矩阵 Wa 和偏移值 ba )。
传统的二元交叉熵损失函数,上面的损失函数使另外一种写法(下面的公式与本论文无关,是用来理解二元交叉熵损失函数的):
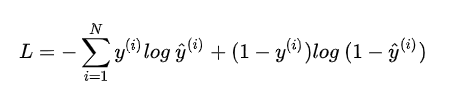
3.3.4 解码(Decoding)
LOTN通过 ri 来预测 wi 的标记 yi∈{B,I,O} ,可以看成一个三分类问题,我们使用一个线性层和softmax层来计算预测概率:
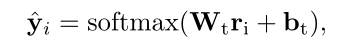
TOWE任务的交叉熵损失函数定义如下:
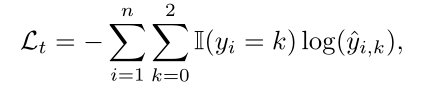
在这里{B,I,O}对应的转化为标签{1,2,3},其中 yi 表示真实的标签。
LOTN还通过辅助学习信号La来整合潜在的观点(这里就把前后都连接起来了),所以,最终的损失函数定义如下:
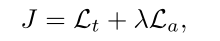
λ用来衡量辅助学习的重要性,可以手动调整,通过最小化损失函数J来获得最优的性能。
4 实验
4.1 数据集
数据集:SemEval 2014 , SemEval 2015, SemEval 2016
Yelp Review 和 Amazon Review 用于预训练情感分类模块

4.2 结果

5.总结
本文针对TOWE(Target-oriented Opinion Words Extraction)子任务,对现有的模型进行了改进,通过迁移学习的知识,把预训练的情感分类中得到的意见词(情感词)传递给TOWE模型,增强了模型的性能。同时与IOG相比,降低了复杂度。