���ɷַ��������ִ�����
- 4. ���ɷַ��������ִ����� Principal Component Analysis and Its Modern Interpretations
-
- 4.1 ����ѧ����
-
-
- Theorem 4.1
-
- 4.2 ͳ��ѧ����
- 4.3 ���ģ�ͽ��� ��Error Model Interpretation��
-
-
- Theorem 4.2.
-
- 4.4 Relation to Autoencoders
-
-
- Theorem 4.3
-
- 4.5 PCA ʵ��
-
- Task 1.
- Task 2.
4. ���ɷַ��������ִ����� Principal Component Analysis and Its Modern Interpretations
�ල��ѧϰ����
���������X��RnX\in \mathbb{R}^{n}X��Rn����������ǻ�ԭ����S��RkS\in \mathbb{R}^{k}S��Rk��SSS��ͨ��ij��ӳ��fff��XXX�м�������ģ���ӳ��ʹ�ض�����ʧ����L(f(X))L(f(X))L(f(X))��С���ලѧϰ�е���ʧ����ּ�ڼ��� ����������ķֲ�����������ζ��f(X)f(X)f(X)������������һ����XXX������С�ö������С�����������£�����ͨ�����ල�Ľ�ά��ʵ�ֵģ���ͨ��ѡ��С��nnn��kkk�����⣬���࣬��SSS������ľ���������ɣ�����������ֲ��������
�������ල��ά�����У����ɷַ�����PCA������������һ�֡�������˵���ලѧϰ��������ָ�����Dz���ѧϰ�㷨֮ǰ�����ݲ���Ҫ����ǣ��ɼල�ߣ���
PCA�ijɹ����������ļ��Ժ���������ʵ�������ݷ��������еĹ㷺�����ԡ���������������������ԭ����ɢ��Karhunen-Lo��ve�任��Hotelling�任���ʵ��������ֽ⡣���ĺ��ļ�����ԭʼ���ݵķֲ�������ij����άƽ���ϣ�����˵�������еĴַ������ͨ���������ƽ���ϵ�ͶӰ������������
4.1 ����ѧ����
PCA�ļ��ν����ǣ���ͨ�������е�����Ͷ�䵽һ���ϵ�ά�ȵ��ӿռ�������ά�ȣ����ø��ӿռ���ʵ��Ļ�����������ͼ4.1˵�������ֽ��͡�
���ǿ��Խ���һ������ʽ�����¡���k<pk<pk<p��ͨ����k?pk\ll pk?p����X=[x1,��,xn]��\mathbf{X}=\left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right] \inX=[x1?,��,xn?]�� Rp��n\mathbb{R}^{p \times n}Rp��n�Ǿ��еĹ۲���ع�һ�£����е���˼�� ��ixi=0\sum_{i} \mathbf{x}_{i}=0��i?xi?=0��������1{ }^{1}1ͶӰ��U:Rp��Rp\pi_{\mathcal{U}}: \mathbb{R}^{p} \rightarrow \mathbb{R}^{p}��U?:Rp��Rp��kkkά���ӿռ�U?Rp\mathcal{U} \subset \mathbb{R}^{p}U?Rp�����Խ���U\mathcal{U}U��������������Rp\mathbb{R}^{p}Rp���Ӽ�����ȷ�е�˵����������þ���Uk��Rp��k\mathbf{U}_{k} \in \mathbb{R}^{p \times k}Uk?��Rp��k����ʾ�������������������Uk?Uk=Ik\mathbf{U}_{k}^{\top} \mathbf{U}_{k}=\mathbf{I}_{k}Uk??Uk?=Ik? )��ͶӰ�����¹�ʽ����
��U(x)=UkUk?x(4.1)\pi_{\mathcal{U}}(\mathbf{x})=\mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{x}\tag{4.1} ��U?(x)=Uk?Uk??x(4.1)
1{ }^{1}1 �����������˵�����������ǹ��ڱ������ij˻���

ͼ 4.1: PCA�ļ��ν��ͣ��ҵ�һ��kkkά���ӿռ䣬�Բ����ݵĴַ����һ��PC\mathrm{PC}PC��ʾΪ��ɫ�����ڶ�������ʾΪ��ɫ��
��ˣ����ǿ��Խ��������Ϊ���ҵ�һ������Uk��Rp��k\mathbf{U}_{k} \in \mathbb{R}^{p \times k}Uk?��Rp��k���þ�����б��������У���ʹͶӰ���ƽ��֮����С��
J(Uk)=��i=1n��xi?UkUk?xi��22(4.2)J\left(\mathbf{U}_{k}\right)=\sum_{i=1}^{n}\left\|\mathbf{x}_{i}-\mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{x}_{i}\right\|_{2}^{2}\tag{4.2} J(Uk?)=i=1��n?����?xi??Uk?Uk??xi?����?22?(4.2)
��������������������ľ���������ҵ�2{ }^{2}2��
2{ }^{2}2 ����֮���Կ���˵�����������ױ��ҵ�������Ϊ�ڹ�ȥ�ļ�ʮ����о���Ա�Ѿ������˸�Ч�ɿ����㷨��������������ֵ�ֽ⡣�Ⲣ����ζ����һ������£������ľ���������ּ��㡣
Theorem 4.1
�����Ĺ۲����X\mathbf{X}X������ֵ�ֽ�Ϊ
X=UDV?(4.3)\mathbf{X}=\mathbf{U D V}^{\top} \tag{4.3} X=UDV?(4.3)
������ֵd1��?��dn��0d_{1} \geq \cdots \geq d_{n} \geq 0d1?��?��dn?��0�����������Uk\mathbf{U}_{k}Uk? ��ʾU\mathbf{U}U��ǰkkk�У���ôUk\mathbf{U}_{k}Uk?������С����4.2�������⣬���ٵ�kkk�����ľ���Э�������S:=Uk?X\mathbf{S}:=\mathbf{U}_{k}^{\top} \mathbf{X}S:=Uk??X�ǶԽǾ���Ҳ����˵��ͨ��PCA��ȡ�������Dz���صġ�
Proof.
���ȣ���Qk��Rp��k\mathbf{Q}_{k} \in \mathbb{R}^{p \times k}Qk?��Rp��k ��Qk?Qk=Ik\mathbf{Q}_{k}^{\top} \mathbf{Q}_{k}=\mathbf{I}_{k}Qk??Qk?=Ik?����Ҫע����ǣ��� ��xi?QkQk?xi��22=\left\|\mathbf{x}_{i}-\mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i}\right\|_{2}^{2}=����?xi??Qk?Qk??xi?����?22?= ��xi��22?xi?QkQk?xi\left\|\mathbf{x}_{i}\right\|_{2}^{2}-\mathbf{x}_{i}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i}��xi?��22??xi??Qk?Qk??xi?��ʼ����С��JJJ�ȼ��� ��ixi?QkQk?xi\sum_{i} \mathbf{x}_{i}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i}��i?xi??Qk?Qk??xi?��Ȼ��������
��i=1nxi?QkQk?xi=tr?(Qk?XX?Qk)=tr?(Qk?UDD?U?Qk)=tr?(U?QkQk?U?[d12?dn2])\begin{aligned} \sum_{i=1}^{n} \mathbf{x}_{i}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i} &=\operatorname{tr}\left(\mathbf{Q}_{k}^{\top} \mathbf{X} \mathbf{X}^{\top} \mathbf{Q}_{k}\right) \\ &=\operatorname{tr}\left(\mathbf{Q}_{k}^{\top} \mathbf{U D D}^{\top} \mathbf{U}^{\top} \mathbf{Q}_{k}\right) \\ &=\operatorname{tr}\left(\mathbf{U}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{U}^{\top}\left[\begin{array}{ccc} d_{1}^{2} & & \\ & \ddots & \\ & & d_{n}^{2} \end{array}\right]\right) \end{aligned} i=1��n?xi??Qk?Qk??xi??=tr(Qk??XX?Qk?)=tr(Qk??UDD?U?Qk?)=tr???U?Qk?Qk??U????d12????dn2?????????
n��nn \times nn��n ����U?QkQk?U\mathbf{U}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{U}U?Qk?Qk??U��һ����Ϊkkk��ͶӰ����������ĶԽ������0��1֮�䡣Ϊ��˵����һ�㣬��P\mathbf{P}P��һ������ͶӰ�������ĵ�iii���Խ�����Ŀ�� ei?Pei\mathbf{e}_{i}^{\top} \mathbf{P e}_{i}ei??Pei?������ei\mathbf{e}_{i}ei?�ǵ�iii����������������P\mathbf{P}P��һ��������ͶӰ����������
ei?Pei=ei?P2ei=��Pei��2.(4.4)\mathbf{e}_{i}^{\top} \mathbf{P e}_{i}=\mathbf{e}_{i}^{\top} \mathbf{P}^{2} \mathbf{e}_{i}=\left\|\mathbf{P e}_{i}\right\|^{2} . \tag{4.4} ei??Pei?=ei??P2ei?=��Pei?��2.(4.4)
����P\mathbf{P}P ������ͶӰ��(I?P)(\mathbf{I}-\mathbf{P})(I?P)�Ƕ�����������ͶӰ��Rn\mathbb{R}^{n}Rn�е�ÿ������������д��ͶӰ�ռ���Ԫ�ص�Ψһ��ϡ��ر��Ƕ��ڱ���������˵����һ������ȷ�ģ���
1=��ei��2=��Pei+(I?P)ei��2=��Pei��2+��(I?P)ei��2+2?Pei,(I?P)ei?=��Pei��2+��(I?P)ei��2.(4.5)\begin{aligned} 1 &=\left\|\mathbf{e}_{i}\right\|^{2}=\left\|\mathbf{P e}_{i}+(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2} \\ &=\left\|\mathbf{P e}_{i}\right\|^{2}+\left\|(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2}+2\left\langle\mathbf{P e}_{i},(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\rangle \\ &=\left\|\mathbf{P e}_{i}\right\|^{2}+\left\|(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2} . \end{aligned} \tag{4.5}1?=��ei?��2=��Pei?+(I?P)ei?��2=��Pei?��2+��(I?P)ei?��2+2?Pei?,(I?P)ei??=��Pei?��2+��(I?P)ei?��2.?(4.5)
����Pei\mathrm{Pe}_{i}Pei?��(I?P)ei(\mathbf{I}-\mathbf{P}) \mathrm{e}_{i}(I?P)ei?��������ģ��������һ����ʽ������ ������������Pei��2\left\|\mathbf{P e}_{i}\right\|^{2}��Pei?��2�� ��(I?P)ei��2\left\|(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2}��(I?P)ei?��2 ����������������Ϊ1����ˣ���Pei��2\left\|\mathbf{P e}_{i}\right\|^{2}��Pei?��2 ��������iii��λ��[0,1][0,1][0,1]�����ڡ����⣬P\mathbf{P}P�ļ��������жԽ���Ԫ��֮�͵���kkk����ˣ������ܴﵽ�����ֵ������Qk=Uk\mathbf{Q}_{k}=\mathbf{U}_{k}Qk?=Uk?����Ϊ��ʱ���ͶӰ��U?UkUk?U=[Ik000]\mathbf{U}^{\top} \mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{U}=\left[\begin{array}{cc}\mathbf{I}_{k} & 0 \\ 0 & 0\end{array}\right]U?Uk?Uk??U=[Ik?0?00?]��
Ҫ������ԭ�ı���S:=Uk?X\mathbf{S}:=\mathbf{U}_{k}^{\top} \mathbf{X}S:=Uk??X�Dz���صģ�����ע�����X\mathbf{X}X�Ǿ��еģ�����S\mathbf{S}SҲ�Ǿ��еģ�������ľ���Э�������Ϊ
cov?(S):=1nSS?=1nUk?XX?Uk=1n[d12?dk2](4.6)\operatorname{cov}(\mathbf{S}):=\frac{1}{n} \mathbf{S S}^{\top}=\frac{1}{n} \mathbf{U}_{k}^{\top} \mathbf{X X}^{\top} \mathbf{U}_{k}=\frac{1}{n}\left[\begin{array}{lll} d_{1}^{2} & & \\ & \ddots & \\ & & d_{k}^{2} \end{array}\right] \tag{4.6}cov(S):=n1?SS?=n1?Uk??XX?Uk?=n1????d12????dk2?????(4.6)
����S\mathbf{S}S��(i,j)(i, j)(i,j)����Ŀ��Ϊ��iii���ɷ�(principal component) �ĵ�jjj�÷֣������ľ���Ϊ�÷־���(score matrix) ������U\mathbf{U}UҲ������Ϊ���ؾ���(loadings matrix)��3{ }^{3}3��
3{ }^{3}3 ���ؾ���Ķ����������в���һ�¡���ʱ������L:=UD\mathbf{L}:=\mathbf{U D}L:=UD����Ϊloading matrix��U\mathbf{U}U����ʾΪ����/����ľ���
ע�⣬S\mathbf{S}S����ֱ��ͨ��X\mathbf{X}X��SVD�õ�����Ϊ
S=Uk?UDV?=[d1?dk]Vk?=DkVk?,(4.7)\mathbf{S}=\mathbf{U}_{k}^{\top} \mathbf{U D V}^{\top}=\left[\begin{array}{ccc} d_{1} & & \\ & \ddots & \\ & & d_{k} \end{array}\right] \mathbf{V}_{k}^{\top}=\mathbf{D}_{k} \mathbf{V}_{k}^{\top}, \tag{4.7}S=Uk??UDV?=???d1????dk?????Vk??=Dk?Vk??,(4.7)
����Vk\mathbf{V}_{k}Vk?����V\mathbf{V}V��ǰkkk�С�
��Ȼ���ٵı�������ͨ�� Uk?X\mathbf{U}_{k}^{\top} \mathbf{X}Uk??X�����㣬����ʵ��Ӧ�������Dz����еģ���ΪUk\mathbf{U}_{k}Uk?��X\mathbf{X}X�����ܼ���(����S��Ҫ(2p?1)nk(2 p-1) n k(2p?1)nk������)��ʹ��DkVk?\mathbf{D}_{k} \mathbf{V}_{k}^{\top}Dk?Vk??�����ܶ�, ��ΪDk\mathbf{D}_{k}Dk?�ǶԽǾ���Vk?\mathbf{V}_{k}^{\top}Vk??ֻ��kkk�У�����S\mathbf{S}S��Ҫnkn knk�����㡣��ע��nnnΪ����������kkkΪͶӰ����ӿռ�ά��, pppΪԭʼ�ռ�ά�ȣ�
4.2 ͳ��ѧ����
������С���ؽ����J(Uk)J\left(\mathbf{U}_{k}\right)J(Uk?)����(4.2)�����壬PCA���Դ�ͳ��ѧ�ĽǶ������͡����X��RpX\in \mathbb{R}^{p}X��Rp��ʾһ����ά���������PCAѰ��һ�������任��һ���µ�����ϵ����
Y=U?X(4.8)Y=\mathbf{U}^{\top} X \tag{4.8}Y=U?X(4.8)
��U?U=Ip\mathbf{U}^{\top} \mathbf{U}=I_{p}U?U=Ip?������YYY��Э��������ǶԽ��ߵģ����Ҹ����ֵķ������٣���var?(Y1)��?��var?(Yp)\operatorname{var}\left(Y_{1}\right) \geq \cdots \geq \operatorname{var}\left(Y_{p}\right)var(Y1?)��?��var(Yp?)��
����Э�������var?(X)=E[(X?��)(X?��)?]\operatorname{var}(X)=\mathbb{E}\left[(X-\mu)(X-\mu)^{\top}\right]var(X)=E[(X?��)(X?��)?]��������=E[X]\mu=\mathbb{E}[X]��=E[X]���ǶԳƵ��������ɶȣ������Ա��Խǻ�����һ����������U����
D=U?var?(X)U=E[U?(X?��)(X?��)?U]=E[(U?X?U?��)(U?X?U?��)?]=var?(Y)(4.9)\begin{aligned} \mathbf{D} &=\mathbf{U}^{\top} \operatorname{var}(X) \mathbf{U}=\mathbb{E}\left[\mathbf{U}^{\top}(X-\mu)(X-\mu)^{\top} \mathbf{U}\right] \\ &=\mathbb{E}\left[\left(\mathbf{U}^{\top} X-\mathbf{U}^{\top} \mu\right)\left(\mathbf{U}^{\top} X-\mathbf{U}^{\top} \mu\right)^{\top}\right]=\operatorname{var}(Y) \end{aligned} \tag{4.9}D?=U?var(X)U=E[U?(X?��)(X?��)?U]=E[(U?X?U?��)(U?X?U?��)?]=var(Y)?(4.9)
�Ǿ��еݼ�������ĶԽ����������ǿ��Ǿ���Э���������ôU\mathbf{U}U�ɾ��й۲�����SVD��������Ϊ �������������μ���4.3����
4.3 ���ģ�ͽ��� ��Error Model Interpretation��
�ѹ۲쵽������X\mathbf{X}X������λ��ij��kkkά�ӿռ��һЩ�ɾ�����L\mathbf{L}L��һЩ���������N\mathbf{N}N�ĵ��ӣ���
X=L+N(4.10)\mathbf{X}=\mathbf{L}+\mathbf{N} \tag{4.10}X=L+N(4.10)
����ʽ�Ͽ���Ҫ��L\mathbf{L}L������λ��ij��kkkά���ӿռ��У��൱��Ҫ��L\mathbf{L}L�ĵȼ����ڻ����kkk�����ǽ��������п���������PCA����һ�ַ�ʽ������Ҫ�ָ�L\mathbf{L}L��������N\mathbf{N}N���Ӹ������������Ǹ��Զ����ĸ�˹�ֲ�������¡�������������N\mathbf{N}N��ÿ����Ŀ�Ǹ��ݾ�ֵΪ0������Ϊ1�ĸ�˹�ֲ�������ȡ�ġ�������ģ�ͼ����£������۲�ֵX\mathbf{X}X�������Ȼ����L\mathbf{L}LΪ��
L^=arg?min?rank L��k��X?L��F. (4.11)\hat{\mathbf{L}}=\arg \min _{\text {rank } \mathbf{L} \leq k}\|\mathbf{X}-\mathbf{L}\|_{F} \text {. } \tag{4.11}L^=argrank L��kmin?��X?L��F?. (4.11)
�����PCA�ṩ���������Ľ��������
Theorem 4.2.
��X=UDV?\mathbf{X}=\mathbf{U D V}^{\top}X=UDV?Ϊ�۲����X\mathbf{X}X������ֵ�ֽ⣬����ֵΪd1��?��dp��0d_{1}\geq \cdots \geq d_{p} \geq 0d1?��?��dp?��0�����������Uk\mathbf{U}_{k}Uk?��ʾU\mathbf{U}U��ǰkkk�У���Vk\mathbf{V}_{k}Vk?��ʾV\mathbf{V}V��ǰkkk�У���ôL^=Ukdiag?(d1,��,dk)Vk?\hat{\mathbf{L}}=\mathbf{U}_{k} \operatorname{diag}\left(d_{1}, \ldots, d_{k}\right) \mathbf{V}_{k}^{\top}L^=Uk?diag(d1?,��,dk?)Vk?? ��С��(4.11)��
Proof.
��L\mathbf{L}L��(4.11)����С������ע�⣬����L\mathbf{L}L���ȵ��ڻ����kkk�����ҽ�������li\mathbf{l}_{i}li?λ��kkkά���ӿռ��У�����L\mathcal{L}L������ÿһ��Ii\mathbf{I}_{i}Ii?������xi\mathbf{x}_{i}xi?��L\mathcal{L}L��ͶӰ���������ǿ����ڲ������OX?L��F2=��i�Oxi?1i��2|\mathbf{X}-\mathbf{L}\|_{F}^{2}=\sum_{i}\left|\mathbf{x}_{i}-1_{i}\right\|^{2}�OX?L��F2?=��i?�Oxi??1i?��2�������ȡ��L\mathbf{L}L����ĵ�iii�С����
min?rkL��k��X?L��F2=min?dim?(L)=k��i��xi?��L(xi)��2,(4.12)\min _{\mathrm{rkL} \leq k}\|\mathbf{X}-\mathbf{L}\|_{F}^{2}=\min _{\operatorname{dim}(\mathcal{L})=k} \sum_{i}\left\|\mathbf{x}_{i}-\pi_{\mathcal{L}}\left(\mathbf{x}_{i}\right)\right\|^{2}, \tag{4.12}rkL��kmin?��X?L��F2?=dim(L)=kmin?i��?��xi??��L?(xi?)��2,(4.12)
�Ӷ���4.1���Կ�����L\mathcal{L}L��X\mathbf{X}X��ǰkkk��������Uk\mathbf{U}_{k}Uk?���ųɣ�������kkk-�Ƚ���ֵΪ
L^=UkUk?X=Ukdiag?(d1,��,dk)Vk?(4.13)\hat{\mathbf{L}}=\mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{X}=\mathbf{U}_{k} \operatorname{diag}\left(d_{1}, \ldots, d_{k}\right) \mathbf{V}_{k}^{\top} \tag{4.13}L^=Uk?Uk??X=Uk?diag(d1?,��,dk?)Vk??(4.13)
4.4 Relation to Autoencoders
PCA��һ���ر����������ʽ������أ�����ν���Զ����������Զ���������Ŀ����������ͨ��һ����ά�ռ���ܺõ��ؽ����룬���߸���ʽ��˵��pppά���������ʵ��x1,��,xnx_{1}, \ldots, x_{n}x1?,��,xn?����ͨ������fff��ӳ�䵽��ά�ռ�Rk\mathbb{R}^{k}Rk��Ȼ����Щͼ���ٴα�ӳ�䵽Rp\mathbb{R}^{p}Rp����ͼ���ʺ�ԭʼ���롣
g?f(xi)��xi.(4.14)g \circ f\left(\mathbf{x}_{i}\right) \approx \mathbf{x}_{i} . \tag{4.14}g?f(xi?)��xi?.(4.14)
�Զ���������ͼΪ������ҵ���ѵ�һ�Ժ���(f,g)(f, g)(f,g)�����뷨�ǣ���Ȥ��Ϣ�ĺ������ְ����ڼ��ٵ�����f(xi)f\left(\mathbf{x}_{i}\right)f(xi?)�С����������Ǽ���fff��ggg�����Եģ��ɾ���V��Rk��p\mathbf{V} \in \mathbb{R}^{k \times p}V��Rk��p ��W��Rp��k\mathbf{W} \in \mathbb{R}^{p \times k}W��Rp��k ����ôg?f(xi)=WVxig \circ f\left(\mathbf{x}_{i}\right)=\mathbf{W} \mathbf{V} \mathbf{x}_{i}g?f(xi?)=WVxi?���������ͨ��ƽ������֮���������ؽ�����
J(W,V)=��i=1n��xi?WVxi��2(4.15)J(\mathbf{W}, \mathbf{V})=\sum_{i=1}^{n}\left\|\mathbf{x}_{i}-\mathbf{W} \mathbf{V} \mathbf{x}_{i}\right\|^{2} \tag{4.15}J(W,V)=i=1��n?��xi??WVxi?��2(4.15)
���ǿ���֤�������ŵ�V\mathbf{V}Vֻ���ɹ۲����X=[x1,��,xn]\mathbf{X}=\left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right]X=[x1?,��,xn?]��ǰkkk����������������
Theorem 4.3
��Uk\mathbf{U}_{k}Uk?Ϊ�۲����X\mathbf{X}X��ǰkkk��������������ôV=Uk?\mathbf{V}=\mathbf{U}_{k}^{\top}V=Uk??��W=Uk\mathbf{W}=\mathbf{U}_{k}W=Uk?ʹ���Ա��������ؽ������С��4.15����
Proof.
����V\mathbf{V}V��W\mathbf{W}W��ά����ƽ������WV\mathbf{W} \mathbf{V}WV��������kkk���ȡ����ԣ�����WVxi\mathbf{W} \mathbf{V} \mathbf{x}_{i}WVxi?λ��һ��kkkά���ӿռ��У�����γ�һ�������Ϊkkk�ľ��������ڶ���4.2�п�����LLL����Сֵ����V=Uk?\mathbf{V}=\mathbf{U}_{k}^{\top}V=Uk??��W=Uk\mathbf{W}=\mathbf{U}_{k}W=Uk?ʵ�֡�
ͨ�����������Ժ��������ַ���������Ȥ����չ����ʵ��Ӧ���зdz��ɹ�����f(x):=��(Vx)f(\mathbf{x}):=\sigma(\mathbf{V} \mathbf{x})f(x):=��(Vx)��ʽ�ĺ���������V\mathbf{V}V����������µľ�����\sigma����һ��������������������Ը�����Ϊ�㣬�������������ı䡣�����ַ����������У����������Ż�����û�з��ʽ�Ľ��������������Ҫ�Ż������������ݶ��½����������Ƶػ��һ����ѽ��������
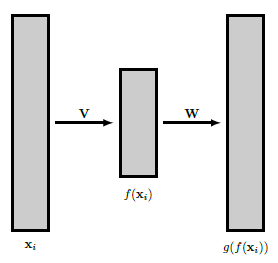
ͼ4.2��һ�����Զ����������� V��Rk��p,W��Rp��k,k<p\mathbf{V} \in \mathbb{R}^{k \times p}, \mathbf{W} \in \mathbb{R}^{p \times k}, k<pV��Rk��p,W��Rp��k,k<p��
4.5 PCA ʵ��
Task 1.
In this task, we will once again work with the MNIST training set as provided on Moodle. Choose three digit classes, e.g. 1,2 and 3 and load N=1000N=1000N=1000 images from each of the classes to the workspace. Store the data in a floating point matrix XXX of shape (784,3?N)(784,3 * \mathrm{~N})(784,3? N) normalized to the number range [0,1][0,1][0,1]. Furthermore, generate a color label matrix C of dimensions (3?N,3)(3 * N, 3)(3?N,3) . Each row of C assigns an RGB color vector to the respective column of XXX as an indicator of the digit class. Choose [0,0,1],[0,1,0][0, 0,1],[0,1,0][0,0,1],[0,1,0] and [1,0,0][1,0,0][1,0,0] for the three digit classes.
a) Compute the row-wise mean mu of XXX and subtract it from each column of XXX . Save the results as XcX_cXc?.
b) Use np. linalg.svd with full_matrices=False to compute the singular value decomposition [U,Sigma,VT][U , Sigma, VT ][U,Sigma,VT] of XCX_{C}XC? . Make sure the matrices are sorted in descending order with respect to the singular values.
c) Use reshape in order to convert mu and the first three columns of U to (28,28) -matrices. Plot the resulting images. What do you see?
d) Compute the matrix S=np?dot?(np?diag?(Sigma),VT)S=n p \cdot \operatorname{dot}(n p \cdot \operatorname{diag}( Sigma ), V T)S=np?dot(np?diag(Sigma),VT) . Note that this yields the same result as S=np?dot?(U?T,X?C)S=n p \cdot \operatorname{dot}\left(U \cdot T, X_{-} C\right)S=np?dot(U?T,X??C) . The S matrix contains the 3?N3 *\mathrm{N}3?N scores for the principal components 1 to 784 . Create a 2D scatter plot with C as its color parameter in order to plot the scores for the first two principal components of the data.
import numpy as np
import matplotlib.pyplot as pltimport imageio# define to image paths which to import
data_folder = './mnist/'
N = 1000
X = np.zeros((784, 3 * N))for n in range(N):# define the images' pathimpath0 = data_folder + 'd1/d1_{}.png'.format(str(n + 1).zfill(4))impath1 = data_folder + 'd2/d2_{}.png'.format(str(n + 1).zfill(4))impath2 = data_folder + 'd3/d3_{}.png'.format(str(n + 1).zfill(4))# import and convert to numpy arrayI0 = np.array(imageio.imread(impath0)).astype(np.float64).reshape(784, ) / 255I1 = np.array(imageio.imread(impath1)).astype(np.float64).reshape(784, ) / 255I2 = np.array(imageio.imread(impath2)).astype(np.float64).reshape(784, ) / 255X[:, n] = I0X[:, n + N] = I1X[:, n + 2 * N] = I2C = np.zeros((3 * N, 3))
C[0:N, :] = [0, 0, 1]
C[N:2 * N, :] = [0, 1, 0]
C[2 * N:3 * N, :] = [1, 0, 0]mu = np.mean(X, axis=1)
X_c = X - np.expand_dims(np.mean(X, axis=1), axis=1) \\
# singular decomposition
[U, Sigma, VT] = np.linalg.svd(X_c, full_matrices=False)# the resulting images
plt.figure(1)
plt.subplot(1, 4, 1)
plt.title('mu')
plt.imshow(mu[:, ].reshape(28, 28))
for n in range(3):plt.subplot(1, 4, n + 2)plt.title('U[:, {}]'.format(n))plt.imshow(U[:, n].reshape(28, 28))
plt.show()# calculate the projection
S = np.dot(np.diag(Sigma), VT) # Using Sigma*V.T is more efficientidx_new = np.arange(3 * N).reshape(3, N).T.ravel()plt.figure(2)
# using the first two features to scatter the points,
# the parameters are (feature 1, feature 2, color) of a specific point
plt.scatter(S[0, idx_new], S[1, idx_new], c=C[idx_new])
plt.show()
the outputs are,


Task 2.
In this task, we consider the problem of choosing the number of principal vectors. Assuming that X��Rp��N\mathbf{X} \in \mathbb{R}^{p \times N}X��Rp��N is the centered data matrix and P=UkUk?\mathbf{P}=\mathbf{U}_{k} \mathbf{U}_{k}^{\top}P=Uk?Uk?? is the projector onto the k -dimensional principal subspace, the dimension kkk is chosen such that the fraction of overall energy contained in the projection error does not exceed ?\epsilon? , i.e.
��X?PX��F2��X��F2=��i=1M��xi?Pxi��2��i=1N��xi��2��?\frac{\|\mathbf{X}-\mathbf{P X}\|_{F}^{2}}{\|\mathbf{X}\|_{F}^{2}}=\frac{\sum_{i=1}^{M}\left\|\mathbf{x}_{i}-\mathbf{P} \mathbf{x}_{i}\right\|^{2}}{\sum_{i=1}^{N}\left\|\mathbf{x}_{i}\right\|^{2}} \leq \epsilon��X��F2?��X?PX��F2??=��i=1N?��xi?��2��i=1M?��xi??Pxi?��2?��?
where ?\epsilon? is usually chosen to be between 0.01 and 0.2 .
The MIT VisTex database consists of a set of 167 RGB texture images of sizes (512,512,3) .
a) After preprocessing the entire image set (converting to normalized grayscale matrices), divide the images into non overlapping tiles of sizes (64,64) and create a centered data matrix X_c of size (p,N)(p, N)(p,N) from them, where p=64*64 and N=167 *(512 / 64) *(512 / 64) .
b) Compute the SVD of X_c and make sure the singular values are sorted in descending order.
c) Plot the fraction of signal energy contained in the projection error for the principal subspace dimensions 0 to p. How many principal vectors do you need to retain 80%, 90%, 95 % or 99 % of the original signal energy?
d) Discuss: Can you imagine a scenario, where signal energy is a bad measure of useful information?
import os, glob
import matplotlib.pyplot as plt
import imageio
import numpy as npdef rgb2gray(rgb):r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]gray = 0.2989 * r + 0.5870 * g + 0.1140 * breturn grayif __name__ == '__main__':# define data directorydata_dir = 'VisTex_512_512'# change to correct directoryfiles = glob.glob(data_dir+'/*.ppm')# define number of filesimg_N = len(files)p = 64 * 64 # tiles sizeN = np.uint16(167 * (512/64) * (512/64)) # Number of tilesX = np.zeros((p, N))for f in range(img_N):img = imageio.imread(files[f])img = rgb2gray(np.array(img)/255.0)for k in range(0, 8):for j in range(0, 8):x_tmp = img[k*64:(k+1)*64, j*64:(j+1)*64].ravel()X[:, np.uint16(f*(512/64)**2 + k*8 + j)] = x_tmp# a) centered data matrixmu = np.mean(X, axis=1)X_c = X - np.expand_dims(mu, 1)# b) the SVD of X_c[U, Sigma, VT] = np.linalg.svd(X_c, full_matrices=False) # full_matrices?[U_x, Sigma_x, VT_x] = np.linalg.svd(X, full_matrices=False)# c) the preserved energy'''Remark : Sigma can be described the values which contains the energy of each subspace. If we accumulate all sigma, then we can get the whole energy of the original matrix.'''p_steps = np.arange(p+1)proj_error = np.array([(1.0 - np.sum(Sigma[:i]**2)/np.sum(Sigma**2))*100.0 for i in p_steps])plt.plot(p_steps, proj_error)plt.xlabel('Dimension'); plt.ylabel('Projection Error (%)')plt.show()print('Required dimension of subspace for Preservation of 80% of the energy:', np.sum(np.uint16(proj_error>=20))+1)print('Required dimension of subspace for Preservation of 90% of the energy:', np.sum(np.uint16(proj_error>=10))+1)print('Required dimension of subspace for Preservation of 95% of the energy:', np.sum(np.uint16(proj_error>=5))+1)print('Required dimension of subspace for Preservation of 99% of the energy:', np.sum(np.uint16(proj_error>=1))+1)proj_error_x = np.array([(1.0-np.sum(Sigma_x[:i]**2)/np.sum(Sigma_x**2))*100.0 for i in p_steps])plt.plot(p_steps, proj_error_x)plt.xlabel('Dimension'); plt.ylabel('Projection Error (%)')plt.show()print('Required dimension of subspace for Preservation of 80% of the energy:', np.sum(np.uint16(proj_error_x>=20))+1)print('Required dimension of subspace for Preservation of 90% of the energy:', np.sum(np.uint16(proj_error_x>=10))+1)print('Required dimension of subspace for Preservation of 95% of the energy:', np.sum(np.uint16(proj_error_x>=5))+1)print('Required dimension of subspace for Preservation of 99% of the energy:', np.sum(np.uint16(proj_error_x>=1))+1)Using the centered observation matrix:
Required dimension of subspace for Preservation of 80% of the energy: 98
Required dimension of subspace for Preservation of 90% of the energy: 335
Required dimension of subspace for Preservation of 95% of the energy: 694
Required dimension of subspace for Preservation of 99% of the energy: 1651Without the centered observation matrix:
Required dimension of subspace for Preservation of 80% of the energy: 2
Required dimension of subspace for Preservation of 90% of the energy: 17
Required dimension of subspace for Preservation of 95% of the energy: 121
Required dimension of subspace for Preservation of 99% of the energy: 877
the outputs are,


d)
A typical situation that arises with machine learning on natural images is that lighting conditions vary heavily. Often, the overall brightness of a picture does not add any discriminative value to it. For instance, a face recognition system should not care about whether a picture was taken at day or at night. However, if the overall brighness varies over a set of images that is processed by PCA, the first principal components will mostly contain the brightness information.
s^=arg?max?ss.t. ��s��=1s?����?s=arg?max?ss.t. ��s��=1�O�Os���O�O2=arg?max?ss.t. ��s��=1�O�Osdiag?(��1,1,...,��p,p)�O�O2\begin{aligned} \hat{\mathrm{s}} &=\underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ \mathrm{s}^{\top} \Sigma \Sigma^{\top} \mathrm{s}\\ &= \underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ ||\mathrm{s}\Sigma||^2 \\ &= \underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ ||\mathrm{s} \operatorname{diag}(\sigma_{1,1}, ...,\sigma_{p,p})||^2 \\ \end{aligned} s^?=s s.t. ��s��=1argmax? s?����?s=s s.t. ��s��=1argmax? �O�Os���O�O2=s s.t. ��s��=1argmax? �O�Osdiag(��1,1?,...,��p,p?)�O�O2?
s^=arg?max?ss.t. ��s��=1s?����?s\hat{\mathrm{s}}=\underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ \mathrm{s}^{\top} \Sigma \Sigma^{\top} \mathrm{s} s^=s s.t. ��s��=1argmax? s?����?s.