ת���ԣ�https://shartoo.github.io/RCNN-series/
һ ����֪ʶ
1.1 IOU�Ķ���
��������Ҫ��λ�������bounding box�����������ͼƬһ�������Dz���Ҫ��λ��������bounding box ���ǻ�Ҫʶ���bounding box �����������dz���������bounding box�Ķ�λ���ȣ���һ������Ҫ�ĸ����Ϊ�����㷨�����ܰٷְٸ��˹���ע��������ȫƥ�䣬��˾ʹ���һ����λ�������۹�ʽ��IOU��

IOU����������bounding box���ص��ȣ�����ͼ��ʾ:
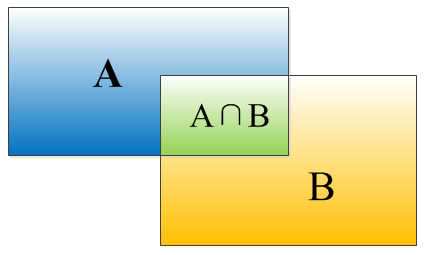
���ο�A��B��һ���غ϶�IOU���㹫ʽΪ��
IOU=(A��B)/(A��B)
���Ǿ��ο�A��B���ص����ռA��B�������������:
IOU=SI/(SA+SB-SI)
1.2 �Ǽ���ֵ����
RCNN�㷨�����һ��ͼƬ���ҳ�n�������������ľ��ο�Ȼ��Ϊÿ�����ο�Ϊ����������ʣ�

���������ͼƬһ������λһ������������㷨���ҳ���һ�ѵķ���������Ҫ�б���Щ���ο���û�õġ��Ǽ���ֵ���ƣ��ȼ�����6�����ο��ݷ��������������������С����ֱ����ڳ����ĸ��ʷֱ�ΪA��B��C��D��E��F��
-
�������ʾ��ο�F��ʼ���ֱ��ж�A~E��F���ص���IOU�Ƿ����ij���趨����ֵ;
-
����B��D��F���ص��ȳ�����ֵ����ô���ӵ�B��D������ǵ�һ�����ο�F�������DZ��������ġ�
-
��ʣ�µľ��ο�A��C��E�У�ѡ���������E��Ȼ���ж�E��A��C���ص��ȣ��ص��ȴ���һ������ֵ����ô���ӵ��������E�����DZ��������ĵڶ������ο�
������һֱ�ظ����ҵ����б����������ľ��ο�
1.3 һ��ͼ����RCNN
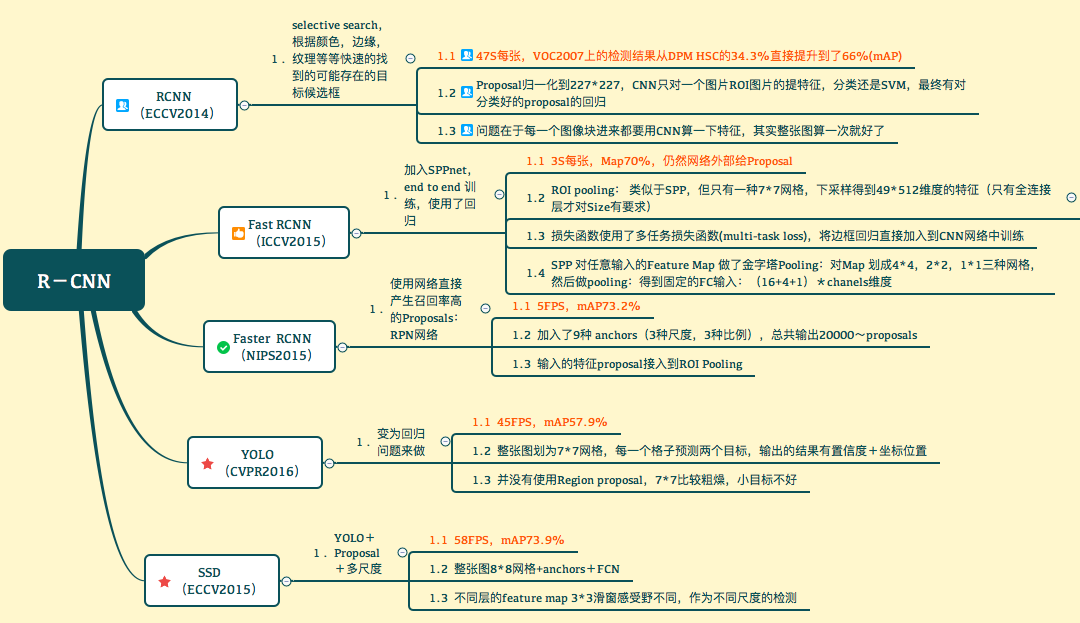
�� RCNN
�㷨��Ҫ����������һ��ͼƬ�������ȶ�λ��2000�������ѡ��Ȼ�����CNN��ȡÿ����ѡ����ͼƬ����������������������ά��Ϊ4096ά�����Ų���svm�㷨�Ը�����ѡ���е�������з���ʶ��Ҳ�����ܸ����̷�Ϊ��������a���ҳ���ѡ��b������CNN��ȡ����������c������SVM���������������ࡣ�������������ͼƬ��ʾ��
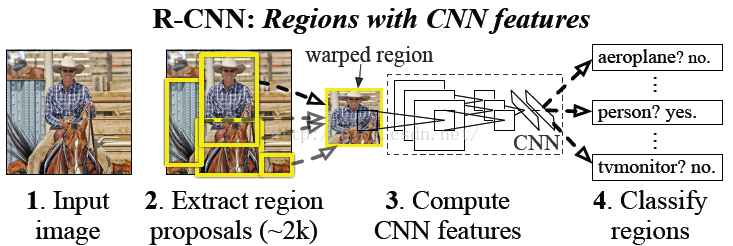
����ֱ�������衣
2.1 ��ѡ������
����������һ��ͼƬʱ������Ҫ���������п��������������������õķ����Ǵ�ͳ�����㷨selective search (github����Դ��)��ͨ������㷨����������2000����ѡ��Ȼ��������������ͼ�п��Կ������ѳ��ĺ�ѡ���Ǿ��εģ������Ǵ�С������ͬ��Ȼ��CNN������ͼƬ�Ĵ�С���й̶��ģ�������������ľ���ѡ�������������ӽ�CNN�У��϶����С���˶���ÿ������ĺ�ѡ����Ҫ���ŵ��̶��Ĵ�С���������ǽ���Ҫ��ô�������Ŵ�����Ϊ�˼�������Ǽ�����һ��CNN����Ҫ������ͼƬ��С�Ǹ�������ͼƬ227*227����Ϊ���Ǿ���selective search �õ����Ǿ��ο�paper���������ֲ�ͬ�Ĵ���������
(1)������������
���ַ����ܼ����Dz���ͼƬ�ij��������������Ƿ�Ť�����������ž����ˣ�ȫ�����ŵ�CNN����Ĵ�С227*227������ͼ(D)��ʾ��
(2)����ͬ������
��ΪͼƬŤ�����ƻ�Ժ���CNN��ѵ��������Ӱ�죬��������Ҳ�����ˡ�����ͬ�����š���������������ְ취
A. ֱ����ԭʼͼƬ�У���bounding box�ı߽������չ����������Σ�Ȼ���ٽ��вü�������Ѿ����쵽��ԭʼͼƬ����߽磬��ô����bounding box�е���ɫ��ֵ��䣻����ͼ(B)��ʾ;
B. �Ȱ�bounding boxͼƬ�ü�������Ȼ���ù̶��ı�����ɫ����������ͼƬ(������ɫҲ�Dz���bounding box��������ɫ��ֵ),����ͼ(C)��ʾ;

������������ԡ�ͬ�����ţ������и�padding�����������ʾ��ͼ�е�1��3�о��ǽ����padding=0,��2��4�н��ͼ����padding=16�Ľ���������������飬���߷��ֲ��ø����������š�padding=16�ľ�����ߡ�
���洦������Եõ�ָ����С��ͼƬ����Ϊ���Ǻ��滹Ҫ��������2000����ѡ��ͼƬ������ѵ��CNN��SVM��Ȼ���˹���ע������һ��ͼƬ�о�ֻ��ע����ȷ��bounding box����������������2000�����ο�Ҳ�����ܻ����һ�����˹���ע��ȫƥ��ĺ�ѡ�����������Ҫ��IOUΪ2000��bounding box���ǩ���Ա���һ��CNNѵ��ʹ�á���CNN�Σ������selective search��ѡ�����ĺ�ѡ����������˹���ע���ο���ص�����IoU����0.5����ô���ǾͰ������ѡ���ע��������𣬷������ǾͰ��������������
2.2 �������
����ܹ�������������ѡ��������һѡ���Alexnet���ڶ�ѡ��VGG16����������Alexnet����Ϊ58.5%��VGG16����Ϊ66%��VGG���ģ�͵��ص���ѡ��Ƚ�С�ľ����ˡ�ѡ���С�Ŀ粽���������ľ��ȸߣ�������������Alexnet��7��������Ϊ�˼���������Ǿ�ֱ��ѡ��Alexnet�������н��⣻Alexnet������ȡ���ְ�����5�������㡢2��ȫ���Ӳ㣬��Alexnet��p5����Ԫ����Ϊ9216�� f6��f7����Ԫ��������4096��ͨ���������ѵ����Ϻ������ȡ����ÿ�������ѡ��ͼƬ���ܵõ�һ��4096ά������������
2.2.1 �����ʼ��
ֱ����Alexnet�����磬Ȼ��������Ҳ��ֱ�Ӳ������IJ�������Ϊ��ʼ�IJ���ֵ��Ȼ����fine-tuningѵ����
�����Ż���⣺��������ݶ��½�����ѧϰ���ʴ�СΪ0.001��
2.2.2 fine-tuning��
���ǽ��Ų���selective search ���������ĺ�ѡ��Ȼ������ָ����СͼƬ������������Ԥѵ����cnnģ�ͽ���fine-tuningѵ��������Ҫ�������������N�࣬��ô���Ǿ���Ҫ������Ԥѵ���ε�CNNģ�͵����һ����滻�����滻��N+1���������Ԫ(��1����ʾ����һ������)��Ȼ����һ��ֱ�Ӳ��ò��������ʼ���ķ��������������IJ������䣻���žͿ��Կ�ʼ����SGDѵ���ˡ���ʼ��ʱ��SGDѧϰ��ѡ��0.001����ÿ��ѵ����ʱ������batch size��Сѡ��128������32����������96����������
�� Fast RCNN
3.1 ����ԭ��
FRCNN���RCNN��ѵ��ʱ��multi-stage pipeline��ѵ���Ĺ����кܺķ�ʱ��ռ��������иĽ�������Ҫ�ǽ��������ͺ����SVM�������������ϵ�һ��ʹ��һ���µ�����ֱ��������ͻع顣��Ҫ�����¸Ľ�:
-
���һ������������һ��ROI pooling layer��ROI pooling layer���ȿ��Խ�image�е�ROI��λ��feature map��Ȼ������һ�������SPP layer�����feature map patch�ػ�Ϊ�̶���С��feature֮���ٴ���ȫ���Ӳ㡣
-
��ʧ����ʹ���˶�������ʧ����(multi-task loss)�����߿�ع�ֱ�Ӽ��뵽CNN������ѵ����
3.2 ģ��
fast rcnn �Ľṹ����
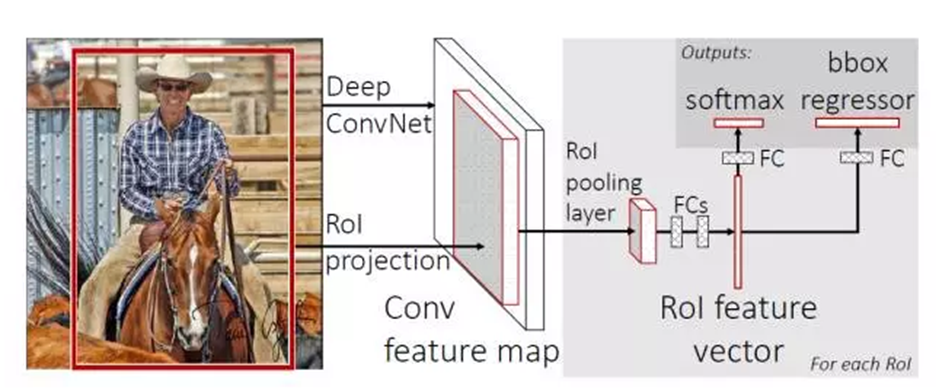
ͼ��ʡ����ͨ��ss���proposal�Ĺ��̣���һ��ͼ�к��������ݼ�Ϊͨ��ss��ȡ����proposal���м��һ���Ǿ�����Ⱦ���֮��õ���conv feature map��ͼ�л�ɫ�IJ��־������Ǻ���е�proposal��Ӧ��conv feature map�е�λ�ã�֮��������������ROI pooling layer������֮�����ȫ���ӡ�������õ���ROI feature vector���ձ�������һ������ȫ����֮��������softmax�ع飬�������з��࣬��һ������ȫ����֮��������bbox�ع顣
ע�⣺ ���м��Conv feature map����������ȡ��ÿһ������RoI pooling layer��FC layers�õ�һ�� �̶����� ��feature vector(������Ҫע����ǣ����뵽����RoI pooling layer��feature map����Conv feature map����ȡ�ģ�������������ȡ���̣�ֻ������һ�ξ�������Ȼ���ʼҲ��ȡ���˴�����RoI�������ǻ�����Ϊ�����������������ģ��ʼ��ȡ����RoI����ֻ��Ϊ������Bounding box �ع�ʱʹ�ã��������ԭͼ�е�λ��)��
3.3 SPP����
�������о�Ա��14��д�����ģ���Ҫ�ǰѾ����Spatial Pyramid Pooling�ṹ����CNN�У��Ӷ�ʹCNN���Դ�������size��scale��ͼƬ�����з������������˷����ȷ�ʣ����һ��dz��ʺ�Detection���Ⱦ����RNN����ȷ��
���IJ�������ϸ����SPP���磬ֻ�������е�SPP-layer������fast rcnn��ʹ�õ�SPP-layer��
SPP layer
����pooling����ÿ��pooling bin��window����Ӧһ���������������pooling�����������bin�ĸ��������������ľ��Ƿּ��̶�bin�ĸ���������bin�ijߴ���ʵ�ֶ༶pooling�̶������
��ͼ��ʾ��layer-5��unpooled FMά��Ϊ16*24������ͼ����ʾ��Ϊ3����
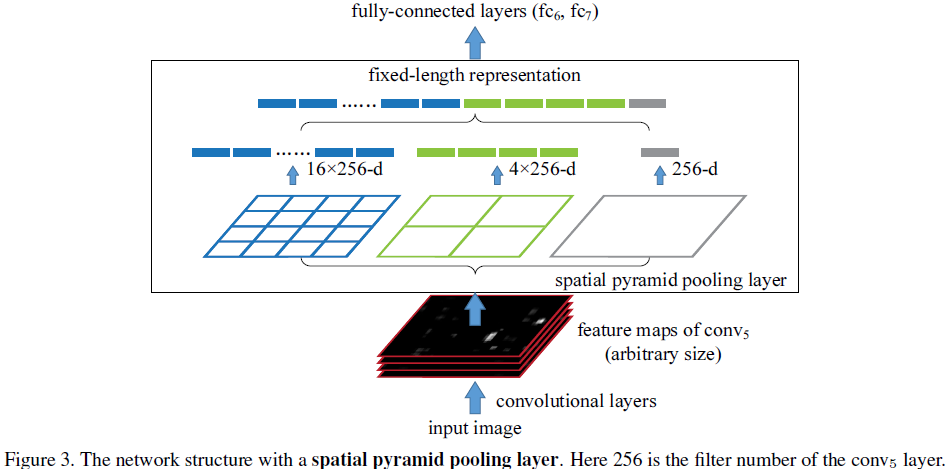
��һ��bin����Ϊ1�����ն�Ӧ��window��СΪ16*24��
�ڶ���bin����Ϊ4�������ն�Ӧ��window��СΪ4*8
������bin����Ϊ16�������ն�Ӧ��window��СΪ1*1.5��С����Ҫ���봦����
ͨ���ںϸ���bin�����������ÿһ��unpooled FM����SPP�����õ���1+4+16ά��SPPed FM��������������ںϺ������������
�����Ϳ�������������size��scale�»�ù̶����������ͬscale�����������ȡ��ͬ�߶ȵ������������ڷ��ࡣ
3.4 RoI pooling layer
ÿһ��RoI����һ����Ԫ�飨r,c,h,w����ʾ�����У�r��c����ʾ���Ͻǣ�����h��w��������߶ȺͿ��ȡ���һ��ʹ�����ػ���max pooling������RoI����ת���ɹ̶���С��HW������ͼ������һ��RoI�Ĵ��ڴ�СΪhw,��ת����HW֮��ÿһ��������һ��h/H * w/W��С���������������ػ�����������е�ֵӳ�䵽HW���ڼ��ɡ�Pooling��ÿһ������ͼͨ�����Ƕ����ģ�����SPP layer����������ֻ��һ��Ŀռ��������
3.5 ��Ԥѵ���������г�ʼ������
������Ԥѵ�������磺CaffeNet��VGG_CNN_M_1024��VGG-16�����Ƕ���5�����ػ����5��13�����ȵľ����㡣����������ʼ��Fast R-CNNʱ����Ҫ��������
�����һ���ػ��㱻RoI pooling layerȡ��
�����һ��ȫ���Ӳ��softmax���滻��֮ǰ���ܹ��������ֵܲ��в�
�����������������ݣ�һ��ͼƬ����ЩͼƬ��һ��RoIs
3.6 ������
ʹ��BP�㷨ѵ��������Fast R-CNN����Ҫ������ǰ���Ѿ�˵����SPP-net������spp��֮ǰ�IJ㣬��Ҫ����Ϊ��ÿһ��ѵ�����������ڲ�ͬ��ͼƬʱ������SPP���BP�㷨�Ǻܵ�Ч�ģ�����Ұ̫��. Fast R-CNN���SGD mini_batch�ֲ�ȡ���ķ������������ȡ��N��ͼƬ��Ȼ��ÿ��ͼƬȡ��R/N��RoIs e.g. N=2 and R=128 ���˷ֲ�ȡ��������һ������FRCN��һ�����������Ż�softmax��������bbox�ع飬����һ����ʵ�ʰ����˶�������ʧ��multi-task loss����С����ȡ����mini-batch sampling����RoI pooling��ķ�����backpropagation through RoI pooling layers����SGD��������SGD hyperparameters����
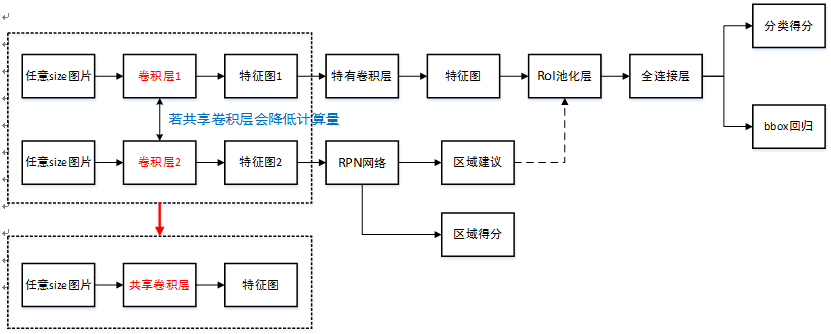
4 Faster RCNN
Faster R-CNNͳһ������ṹ����ͼ��ʾ�����Լ���RPN����+Fast R-CNN���硣
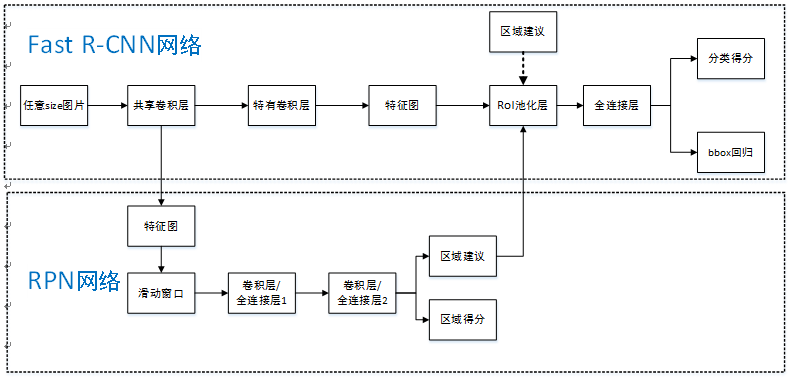
ԭ����������:
-
������CNN���硾ZF��VGG-16�����������СͼƬ��
-
����CNN����ǰ����������ľ����㣬һ����õ���RPN�������������ͼ����һ�������ǰ�������о����㣬��������ά����ͼ��
-
��RPN�������������ͼ����RPN����õ������������÷֣���������÷ֲ��÷Ǽ���ֵ���ơ���ֵΪ0.7���������Top-N������Ϊ300���÷ֵ��������RoI�ػ��㣻
-
��2���õ��ĸ�ά����ͼ�͵�3�������������ͬʱ����RoI�ػ��㣬��ȡ��Ӧ�������������
-
��4���õ�������������ͨ��ȫ���Ӳ�����������ķ���÷��Լ��ع���bounding-box��
4.1 ����RPN����ṹ
����RPN����ṹ����:
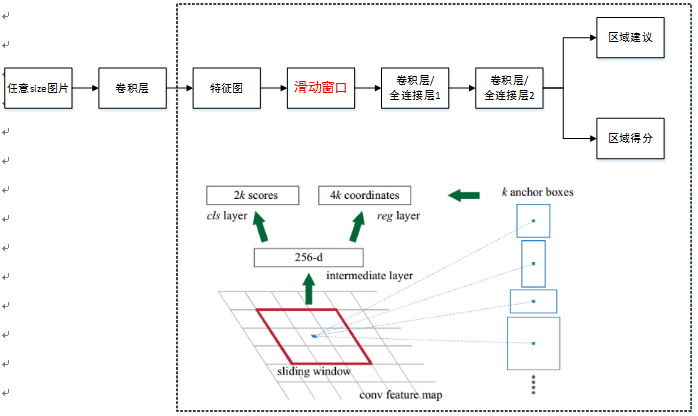
ע�⣺ ��ͼ�о�����/ȫ���Ӳ��ʾ���������ȫ���Ӳ㣬�����������б�ʾ������ʵ������ȫ���Ӳ㣬�������������л���λ�ù���ȫ���Ӳ㣬���Ժ���Ȼ����n��n�����ˡ����������Ϊ3��3�������������е�1��1������ʵ��
RPN��������RPN��CNN����������ӻ������ڲ����Լ�������������������鹦�ܣ���һ�������㽫����ͼÿ������λ�ñ����һ�������������ڶ����������Ӧÿ������λ�����k������÷ֺ�k���ع��������飬���Ե÷�������зǼ���ֵ���ƺ�����÷�Top-N������Ϊ300�������������Ӧ��ע����Щ��������ʵ����Selective Search��EdgeBoxes�ȷ����Ĺ��ܡ�
4.2 RPN��ľ�������
-
��������ImageNet�ϳ��õ�ͼ��������磬�������������������磺ZF��VGG-16����������������IJ��־��������ԭʼͼ�������ͼ��
-
����1������ͼ����n��n�����������Ϊ3��3��n=3��������С������Ҫ���ǵ����Ƿdz��߲��feature map����size����Ҳû�ж�����9�������У�ÿ�����δ����ǿ��Ը�֪���ܴ�Χ�ġ��Ļ�������������ͼ�ϻ���ɨ�衾�����˴�ԭʼͼ������ȡ��������ÿ������λ��ͨ��������1ӳ�䵽һ����ά������������ZF���磺256ά��VGG-16���磺512ά����ά�����������ͼ��СW��H��typically~60��40=2400�������ReLU����Ϊÿ������λ�ÿ���k�֡�������k=9�����ܵIJο����ڡ������г�Ϊanchors�����½������������ζ��ÿ������λ�û�ͬʱԤ�����9�������顾�����߽�IJ�������������һ��W��H������ͼ���ͻ����W��H��k�������飻
-
����2�еĵ�ά�����������������������ӵľ�����2��reg���ڻع�㡾λ�þ�������cls���ڷ���㣬�ֱ����ڻع����������bounding-box������ͼ��߽�IJü���ͼ���Եλ�����Ͷ��������Ƿ�Ϊǰ������֣���������ÿ������λ�ò���k�������飬����reg����4k����������롾ƽ�����Ų�����k������������꣬cls����2k���÷ֹ���k��������Ϊǰ�����߱����ĸ��ʡ�
4.3 Anchor
Anchors��һ���С�̶��IJο����ڣ����ֳ߶�{ 1282��2562��51221282��2562��5122 }�����ֳ�����{1:1��1:2��2:1}������ͼ��ʾ����ʾRPN�����ж�����ͼ����ʱÿ������λ������Ӧ��ԭͼ������9�ֿ��ܵĴ�С���൱��ģ�壬������ͼ�����⻬��λ�ö�����9��ģ�塣�̶�����ͼ���С���㻬�����ĵ��Ӧԭͼ��������ĵ㣬ͨ�����ĵ��size�Ϳ��Եõ�����λ�ú�ԭͼλ�õ�ӳ���ϵ���ɴ�ԭͼλ�ò�������Ground Truth�ظ�������������ǩ����RPNѧϰ��Anchors�Ƿ������弴�ɡ�����ÿ������λ�ã�����k=9��anchor����һ����СΪW*H�ľ���feature map���ܹ������WHk��anchor��
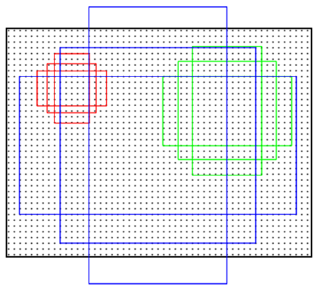
ƽ�Ʋ�����
Anchors���ַ�������ƽ�Ʋ����ԣ�����˵��ͼ����ƽ�������壬���ڽ���Ҳ�����ƽ�ơ�ͬʱ���ַ�ʽҲ����������ģ�͵�size������� 512��(4+2)��9=2.8��104512��(4+2)��9=2.8��104 ��������512��ǰһ������ά�ȣ�(4+2)��9��9��Anchors��ǰ�������÷ֺ�ƽ�����Ų���������MultiBox�� 1536����4+1����800=6.1��106��1536����4+1����800=6.1��106�� ����������С�IJ���������С���ݼ��ϼ��ٹ���Ϸ��ա�
��Ȼ����RPN����������ֻ��Ҫ�ҵ����µĵط���������λ�û��dzߴ磬����Ĺ�����������ɣ������Ļ�����С������м�ѧϰ�����ƺͲ²�࣬������50%���ʡ�����������������硾������ʵ�־������������̶��߶ȱ仯���̶������ȱ仯���̶�������ʽ�������ж��Ƿ��������Լ�����Ӧ��λ�ò����������Ӷȡ�
4.4 ��߶ȶ������
�����ַ��������߶ȶ��������:
-
ͼ�������:����������ͬsize������ͼ�����������ȡ����Ȼ��Ч���Ƿ�ʱ.
-
feature map��ʹ�ö�߶ȣ���/���ȣ��Ļ���:���磬DPM�ֱ�ʹ�ò�ͬ��С��filter��ѵ����ͬ�����ȵ�ģ�͡������ַ������������߶����⣬������Ϊ�ǡ�filter������(pyramid of filters)��
4.5 ѵ������
4.5.1 RPN����ѵ������
RPN���类ImageNet���硾ZF��VGG-16���������мලԤѵ����������ѵ���õ����������ʼ���� �ñ���0.01��ֵΪ0�ĸ�˹�ֲ��������IJ������ʼ����
4.5.2 Fast R-CNN����Ԥѵ��
ͬ��ʹ��mageNet���硾ZF��VGG-16���������мලԤѵ����������ѵ���õ����������ʼ����
4.5.3 RPN������ѵ��
PASCAL VOC ���ݼ��м�����������ǩ��Ҳ������λ�ñ�ǩ�� ����������ʾǰ��������������ʾ������ �ع������������������У� ѵ��ʱ�������г���ͼ��߽��anchors��������ѵ�������л�����ϴ����Դ�����������������ѵ�������������� ��ȥ�������߽���anchors�����÷Ǽ���ֵ���ƣ�����һ��ͼ��2000��anchors����ѵ������ϸ���¡��� ����ZF���������в㣬��VGG-16�������conv3_1��conv3_1���ϵIJ㣬�Ա��ʡ�ڴ档
SGD mini-batch������ʽ�� ͬFast R-CNN���磬��ȡ image-centric ��ʽ�����������ò�β������ȶ�ͼ��ȡ�����ٶ�anchorsȡ����ͬһͼ���anchors����������ڴ档ÿ��mini-batch������һ��ͼ�������ȡ��256��anchors��������������Ϊ1:1����Ȼ���Զ�һ��ͼ����anchors�����Ż��������ڸ�������������ģ�ͻ��������Ԥ��ȷ�ʺܵ͡�������һ��mini-batch����ʧ���������һ��ͼ�в���128�����������ø����������롣
ѵ��������ѡ�� ��PASCAL VOC���ݼ���ǰ60k�ε���ѧϰ��Ϊ0.001����20k�ε���ѧϰ��Ϊ0.0001����������Ϊ0.9��Ȩ��˥������Ϊ0.0005��
������Ŀ�꺯����������ʧ+�ع���ʧ���������£�
-
iΪһ��anchor��һ��mini-batch�е��±� -
pipi ��anchor iΪһ��object��Ԥ�������
-
p?ipi? Ϊground-truth��ǩ��������anchor��positive�ģ���ground-truth��ǩ p?ipi? Ϊ1������Ϊ0��
-
titi ��ʾ��ʾ������anchor��Ԥ������bounding box��4�����������꣬����anchorΪ���ı任��
-
t?iti? �����positive anchor��Ӧ��ground-truth box������anchorΪ���ı任��
-
LclsLcls �������ʧ��classification loss������һ����ֵ����������object���߲��ǣ���softmax loss���乫ʽΪ Lcls(pi,p?i)=?log[pi?p?i+(1?p?i)(1?pi)]Lcls(pi,pi?)=?log[pi?pi?+(1?pi?)(1?pi)]
-
LregLreg �ع���ʧ��regression loss����Lreg(ti,t?i)=R(ti?t?i)Lreg(ti,ti?)=R(ti?ti?) �����ֱ任֮��ԽСԽ�á�������R��Fast R-CNN�ж����robust ross function (smooth L1)��p?iLregpi?Lreg ��ʾ�ع���ʧֻ����positive anchor�� p?i=1pi?=1 )��ʱ��Żᱻ���cls��reg�������ֱ����{ pipi}��{ titi }��R�����Ķ���Ϊ: smoothL1(x)=0.5x2if�Ox�O<1otherwise�Ox�O?0.5smoothL1(x)=0.5x2if�Ox�O<1otherwise�Ox�O?0.5
-
�˲�������Ȩ�������ʧ LclsLcls �ͻع���ʧ LregLreg ��Ĭ��ֵ��=10������ʵ����� �˴�1�仯��100��mAPӰ�첻����1%����
-
NclsNcls �� NregNreg �ֱ���������������ʧ�� LclsLcls �ͻع���ʧ�� LregLreg��Ĭ����mini-batch size=256���� NclsNcls����anchorλ����Ŀ~2400��ʼ�� NregNreg������Ҳ˵���������������DZ���ģ����Լ�ʡ�ԡ�
4.5.4 RPN���硢Fast R-CNN��������ѵ��
ѵ������ṹʾ��ͼ������ʾ��
����ͼ��ʾ��RPN���硢Fast R-CNN��������ѵ����Ϊ�����������繲�������㣬���ͼ�������
����ͨ��4��ѵ���㷨�������Ż�ѧϰ������������
-
��������RPN����Ԥѵ��������������ΪĿ�ĵ�RPN����end-to-end��ѵ����
-
��������Fast R-CNN����Ԥѵ�����õڢٲ��еõ�������������Լ��ΪĿ�ĵ�Fast R-CNN����end-to-end��ѵ������ʱ���������㡿��
-
ʹ�õ�2���������Fast R-CNN�������³�ʼ��RPN���磬�̶����������㡾������ѧϰ��Ϊ0�������¡�������RPN������еIJ㡾��ʱ���������㡿��
-
�̶���3���й��������㣬���õڢ۲��еõ��������飬����Fast R-CNN���еIJ㣬�����γ�ͳһ��������ͼ��ʾ��
4.6 ��ؽ���
**RPN������bounding-box�ع���ô���⣿ͬFast R-CNN�е�bounding-box�ع������ʲô���� **
����bounding-box�ع飬�������¹�ʽ��
- t
- t?t?
���У�x��y��w��h��ʾ������������ʹ��ڵĿ��Ⱥ߶ȣ�����x��xaxa �� x?x? �ֱ��ʾԤ�ⴰ�ڡ�anchor���ں�Ground Truth�����y��w��hͬ�������������Ա���Ϊ��һ����anchor���ڵ�����Ground Truth��bounding-box �ع飻
RPN������bounding-box�ع��ʵ����ʵ���Ǽ����Ԥ�ⴰ�ڡ�������anchor����Ϊ��������Ground Truth�����ƽ�����ű仯�������Լ�Ԥ�ⴰ�ڡ����ܵ�һ�ε�������anchor�������ƽ�����Ų�������Ϊ����anchor����Ϊ��������ֻҪʹ���������Խ�ӽ����Դ˹���Ŀ�꺯������Сֵ����Ԥ�ⴰ�ھ�Խ�ӽ�Ground Truth���ﵽ�ع��Ŀ�ģ�
�����ᵽ�� Fast R-CNN�л���RoI��bounding-box�ع��������������������ͼ�϶�����size��RoIs����Pool������ȡ�ģ�����size RoI�����ع����������Faster R-CNN�У�����bounding-box�ع��������������������ͼ����ͬ�Ŀռ�size��3��3������ȡ�ģ�Ϊ�˽����ͬ�߶ȱ仯�����⣬ͬʱѵ����ѧϰ��k����ͬ�Ļع��������ζ�ӦΪ����9��anchors����k���ع�����������Ȩ�ء���˾���������ȡ�Ͽռ��ǹ̶��ġ�3��3����������anchors����ƣ����ܹ�Ԥ�ⲻͬsize�Ĵ��ڡ�
�����ᵽ�����ֹ������������ѵ����ʽ��
-
����ѵ��,ѵ��RPN���õ�����������ѵ��Fast R-CNN�������������ʱ����������ʼ��RPN���磬�����˹��̡���������ʵ����á���
-
��������ѵ��: ����ͼ��ʾ���ϲ������������ѵ����ǰ���������������鱻�̶���ѵ��Fast R-CNN��������㵽����������ʱRPN������ʧ��Fast R-CNN������ʧ���ӽ����Ż�������ʱ�������顾Fast R-CNN���룬��Ҫ�����ݶȲ����¡����ɹ̶�ֵ������������Fast R-CNNһ�����룺������ĵ�������������ѵ�������Գ�֮Ϊ��������ѵ����ʵ�鷢�֣����ַ����õ��ͽ���ѵ������Ľ�������ܼ���20%~25%��ѵ��ʱ�䣬������python������ʹ�����ַ�����
-
����ѵ�� ��ҪRoI�ػ���������������ҪRoI���β�ʵ�֣�������ο���Ƭpaper��Instance-aware Semantic Segmentation via Multi-task Network Cascades��
ͼ��Scaleϸ�����⣿
�����ᵽѵ���ͼ��RPN��Fast R-CNN��ʹ�õ�һ�߶ȣ�ͳһ����ͼ��̱���600���أ� �����ŵ�ͼ���ϣ�����ZF�����VGG-16��������������ܹ��IJ�����16���أ����������ǰ���͵�PASCALͼ���ϴ�Լ��10���ء�~500��375��600/16=375/10����
Faster R-CNN�����ֳ߶���ô���ͣ�
-
ԭʼ�߶���ԭʼ����Ĵ�С�������κ����ƣ���Ӱ�����ܣ�
-
��һ���߶�������������ȡ����Ĵ�С���ڲ���ʱ���ã�Դ����opts.test_scale=600��anchor������߶����趨�����������anchor����Դ�С��������Ҫ����Ŀ�귶Χ��
-
��������߶������������������Ĵ�С����ѵ��ʱ���ã�Դ����Ϊ224��224��
��������anchors����Ŀ
�����ᵽ����1000��600��һ��ͼ��Լ��20000(~60��40��9)��anchors�����Գ����߽��anchorsʣ��6000��anchors�����÷Ǽ���ֵ����ȥ���ص�����ʣ2000������������ѵ���� ����ʱ��2000����������ѡ��Top-N������Ϊ300��������������Fast R-CNN��⡣