rocketmq
消息队列应用场景
在实际应用中常用的使用场景:异步处理、应用解耦、流量削锋和消息通讯四个场景
场景一:异步处理
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
- 串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
- 并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150),并行方式处理的请求量是10次(1000/100)
小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:

按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。
场景二:应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。假如库存系统无法访问,则订单减库存将失败,从而导致订单失败,缺点在于订单系统与库存系统耦合。
如何解决以上问题呢?引入应用消息队列后的方案,如下图:

- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
假如:在下单时库存系统不能正常使用,也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
场景三:流量削锋(一般在秒杀或团抢活动中使用广泛)
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列:可以控制活动的人数、可以缓解短时间内高流量压垮应用。用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面,秒杀业务根据消息队列中的请求信息,再做后续处理。

场景四:消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等
点对点通讯:客户端A和客户端B使用同一队列,进行消息通讯。
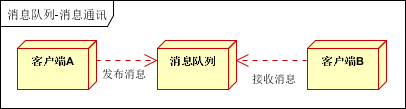
聊天室通讯:客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
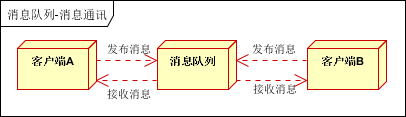
以上实际是消息队列的两种消息模式,点对点或发布订阅模式。模型为示意图,供参考。
RocketMQ的核心组件概念如下:
-
Producer:生产发送消息
-
Consumer:从Broker拉取消息并进行消费
-
Broker:存储Producer发送过来的消息
- 是RocketMQ的核心负责消息的发送、接收、高可用等(真正干活的)
需要定时发送自身情况到NameServer,默认10秒发送一次,超时2分钟会认为该broker失效。
- 是RocketMQ的核心负责消息的发送、接收、高可用等(真正干活的)
-
NameServer:为Producer或Consumer路由到Broker
-
集群架构中的组织协调员
收集broker的工作情况不负责消息的处理
-
NameServer集群、Broker集群、生产者、消费者
注意
1.RocketMQ的Consumer获取消息是通过向Broker发送拉取请求获取的,而不是由Broker发送Consumer接收的方式。
2.Consumer每次拉取消息时消息都会被均匀分发到消息队列再进行传输
RocketMq消息模型(专业术语)
Group
组,可分为ProducerGroup生产者组和ConsumerGroup消费者组,1.ProducerGroup(生产者组):一个生产者组,代表着一群topic相同的Producer。即一个生产者组是同一类Producer的组合。2.ConsumerGroup(消费者组):一个消费者组,代表着一群topic相同,tag相同(即逻辑相同)的Consumer。通过一个消费者组,则可容易的进行负载均衡以及容错
Message
就是要传输的消息,一个消息必须有一个主题,一条消息也可以有一个可选的Tag(标签)和额外的键值对,可以用来设置一个业务的key,便于开发中在broker服务端查找消息。
Message Queue
在默认的情况下消息发送会采取Round Robin轮询方式把消息发送到不同的queue(分区队列);而消费消息的时候从多个queue上拉取消息(broker上的writeQueueNums/readQueueNums),比如设置每次从队列拉取的消息数为16一个topic下有2个broker,broker上writeQueueNums=readQueueNums=4的环境下每次拉取的消息理论数值为16 * 2 * 4 = 128
Topic
主题,是消息的第一级类型,每条消息都有一个主题,就像信件邮寄的地址一样。主题就是我们具体的业务,比如一个电商系统可以有订单消息,商品消息,采购消息,交易消息等。Topic和生产者和消费者的关系非常松散,生产者和Topic可以是1对多,多对1或者多对多,消费者也是这样。
Tag
标签,是消息的第二级类型,可以作为某一类业务下面的二级业务区分,它的主要用途是在消费端的消息过滤。比如采购消息分为采购创建消息,采购审核消息,采购推送消息,采购入库消息,采购作废消息等,这些消息是同一Topic和不同的Tag,当消费端只需要采购入库消息时就可以用Tag来实现过滤,不是采购入库消息的tag就不处理。
补:到底什么时候该用 Topic,什么时候该用 Tag?
1、**消息类型是否一致:**如普通消息,事务消息,定时消息,顺序消息,不同的消息类型使用不同的 Topic,无法通过 Tag 进行区分。
2、**业务是否相关联:**没有直接关联的消息,如淘宝交易消息,京东物流消息使用不同的 Topic 进行区分;而同样是天猫交易消息,电器类订单、女装类订单、化妆品类订单的消息可以用 Tag 进行区分。
3、**消息优先级是否一致:**如同样是物流消息,盒马必须小时内送达,天猫超市 24 小时内送达,淘宝物流则相对会会慢一些,不同优先级的消息用不同的 Topic 进行区分。
**4、消息量级是否相当:**有些业务消息虽然量小但是实时性要求高,如果跟某些万亿量级的消息使用同一个 Topic,则有可能会因为过长的等待时间而『饿死』,此时需要将不同量级的消息进行拆分,使用不同的 Topic。
文字描述
-
导入MQ客户端依赖
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId><version>4.4.0</version> </dependency> -
消息发送者步骤分析
1.创建消息生产者producer,并制定生产者组名 2.指定Nameserver地址 3.启动producer 4.创建消息对象,指定主题Topic、Tag和消息体 5.发送消息 6.关闭生产者producer -
消息消费者步骤分析
1.创建消费者Consumer,制定消费者组名 2.指定Nameserver地址 3.订阅主题Topic和Tag 4.设置回调函数,处理消息 5.启动消费者consumer
Java调用/ssm
maven/pom.xml
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId><version>4.3.0</version>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version>
</dependency>
生产者测试类
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
//声明并初始化一个producer//需要一个producer group名字作为构造方法的参数DefaultMQProducer producer = new DefaultMQProducer("javasm_producer");//设置NameServer地址,此处应改为实际NameServer地址,多个地址之间用;分隔//producer.setNamesrvAddr("192.168.13.141:9876;192.168.13.137:9876");producer.setNamesrvAddr("192.168.13.141:9876");//调用start()方法启动一个producer实例producer.start();//发送10条消息到Topic为TopicTest,tag为TagAfor (int i = 0; i < 10; i++) {
try {
Message msg = new Message("TopicTest",// topic"TagA",// tag("Hello Javasm RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)// body);//调用producer的send()方法发送消息//这里调用的是同步的方式,所以会有返回结果SendResult sendResult = producer.send(msg);//打印返回结果,可以看到消息发送的状态以及一些相关信息System.out.println(sendResult);} catch (Exception e) {
e.printStackTrace();Thread.sleep(1000);}}//发送完消息之后,调用shutdown()方法关闭producerproducer.shutdown();}
}
消费者测试类
public class Consumer {public static void main(String[] args) throws InterruptedException, MQClientException {//声明并初始化一个consumer//需要一个consumer group名字作为构造方法的参数DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("javasm_consumer");//设置NameServer地址//consumer.setNamesrvAddr("192.168.13.141:9876;192.168.13.137:9876");consumer.setNamesrvAddr("192.168.13.141:9876");//这里设置的是一个consumer的消费策略//CONSUME_FROM_LAST_OFFSET 默认策略,从该队列最尾开始消费,即跳过历史消息//CONSUME_FROM_FIRST_OFFSET 从队列最开始开始消费,即历史消息(还储存在broker的)全部消费一遍//CONSUME_FROM_TIMESTAMP 从某个时间点开始消费,和setConsumeTimestamp()配合使用,默认是半个小时以前consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);//设置consumer所订阅的Topic和Tag,*代表全部的Tagconsumer.subscribe("TopicTest", "*");//设置一个Listener,主要进行消息的逻辑处理consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);for(MessageExt messageExt : msgs){System.out.println(new String(messageExt.getBody()));}//返回消费状态//CONSUME_SUCCESS 消费成功//RECONSUME_LATER 消费失败,需要稍后重新消费return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});//调用start()方法启动consumerconsumer.start();System.out.println("Consumer Started.");}
}
springboot调用
导入依赖
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.1.0</version>
</dependency>
添加配置信息
###比较详细 找的
###producer
#该应用是否启用生产者
rocketmq:producer:isOnOff: on#发送同一类消息的设置为同一个group,保证唯一,默认不需要设置,rocketmq会使用ip@pid(pid代表jvm名字)作为唯一标示groupName: ${
spring.application.name}#mq的nameserver地址namesrvAddr: 127.0.0.1:9876#消息最大长度 默认1024*4(4M)maxMessageSize: 4096#发送消息超时时间,默认3000sendMsgTimeout: 3000#发送消息失败重试次数,默认2retryTimesWhenSendFailed: 2###consumer##该应用是否启用消费者consumer:isOnOff: ongroupName: ${
spring.application.name}#mq的nameserver地址namesrvAddr: 127.0.0.1:9876#该消费者订阅的主题和tags("*"号表示订阅该主题下所有的tags),格式:topic~tag1||tag2||tag3;topic2~*;topics: futaotopic~*;consumeThreadMin: 20consumeThreadMax: 64#设置一次消费消息的条数,默认为1条consumeMessageBatchMaxSize: 1reConsumerTimes: 3
生产者测试类(同步消息为例)
//1.同步发送字符串
@RestController
public class ProducerController {
@AutowiredRocketMQTemplate rocketMQTemplate;@GetMapping("/send")public String sendMessage(){
//发送同步消息-字符串//javasmTopic主题名字rocketMQTemplate.syncSend("javasmTopic","同步发送的字符串");return "success";}
}//2.同步发送对象
@GetMapping("/send")
public String sendMessage(){
rocketMQTemplate.syncSend("javasmTopic", new MessageModel());return "success";
}
消费者测试类
//1.消费者Listener-字符串
@Component
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "javasmTopic")
public class ConsumerListener implements RocketMQListener<String> {
@Overridepublic void onMessage(String s) {
System.out.println(s);}
}//2.消费者Listener-对象
@Component
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "javasmTopic")
public class ConsumerListener implements RocketMQListener<MessageModel> {
@Overridepublic void onMessage(MessageModel s) {
System.out.println(s);}
}
消息发送样例
同步消息(sync message )
producer向 broker 发送消息,执行 API 时同步等待, 直到broker 服务器返回发送结果 。
异步消息(async message)
producer向 broker 发送消息时指定消息发送成功及发送异常的回调方法,调用 API 后立即返回,producer发送消息线程不阻塞 ,消息发送成功或失败的回调任务在一个新的线程中执行 。
@GetMapping("/send")
public String sendMessage(){rocketMQTemplate.asyncSend("javasmTopic", "异步发送的字符串", new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {//发送成功执行}@Overridepublic void onException(Throwable throwable) {//发送异常执行}});return "success";
}
单向消息(oneway message)
producer向 broker 发送消息,执行 API 时直接返回,不等待broker 服务器的结果 。
rocketMQTemplate.sendOneWay("javasmTopic", "单向消息");
顺序消息
// hashkey相同的消息会发送到同一个queue
rocketMQTemplate.syncSendOrderly("javasmTopic", "顺序消息1","abc");
rocketMQTemplate.syncSendOrderly("javasmTopic", "顺序消息2","abc");
rocketMQTemplate.syncSendOrderly("javasmTopic", "顺序消息3","abc");
// 消费者-Listener也要修改
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "javasmTopic",consumeMode = ConsumeMode.ORDERLY)//consumeMode 消费模式
默认值 ConsumeMode.CONCURRENTLY 并行处理
ConsumeMode.ORDERLY 按顺序处理
延时消息
//现在RocketMq并不支持任意时间的延时,需要设置几个固定的延时等级,从1s到2h分别对应着等级1到18
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";//timeout连接超时的时间
//delayLevel延时的等级
rocketMQTemplate.syncSend("javasmTopic", MessageBuilder.withPayload("延迟消息").build(), 3000, 3);
批量消息
import org.springframework.messaging.Message;List<Message> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {list.add(MessageBuilder.withPayload("批量消息"+i).build());
}
rocketMQTemplate.syncSend("javasmTopic",list,4000);
消息过滤
消息过滤的方式 :
- 设置Tag
- SQL表达式 (只有使用push模式的消费者才能用使用SQL92标准的sql语句)
tag 过滤:简单过滤
同一个应用尽可能使用同一个topic,不同的消息子类型使用不同的tag标识
每个message只能使用一个tag
//ssm
Message message=new Message("topic","tagA","hello world".getBytes()); //消息标识tagDefaultMQPushConsumer consumer = new DefaultMQPushConsumer("消费者组名");
consumer.subscribe("TOPIC", "TAGA || TAGB || TAGC"); //订阅TAGA、TAGB、TAGC标识消息
consumer.subscribe("TOPIC", "*"); //订阅所有标识的消息//springboot
SendResult result=rocketMQTemplate.syncSend("topic主题名字:tag",MessageBuilder.withPayload("hello 瓜田李下 tag").build()); //设置标签:tag
@RocketMQMessageListener(consumerGroup = "consumerGroup",topic = "topic",selectorExpression = "tag")
SQL表达式
RocketMQ只定义了一些基本语法来支持这个特性。你也可以很容易地扩展它。
- 数值比较,比如:>,>=,<,<=,BETWEEN,=;
- 字符比较,比如:=,<>,IN;
- IS NULL 或者 IS NOT NULL;
- 逻辑符号 AND,OR,NOT;
常量支持类型为:
- 数值,比如:123,3.1415;
- 字符,比如:‘abc’,必须用单引号包裹起来;
- NULL,特殊的常量
- 布尔值,TRUE 或 FALSE
//ssm
msg.putUserProperty("a", "2"); //设置消息属性
consumer.subscribe("TopicTest", MessageSelector.bySql("a between 0 and 3"); //sql过滤,a在0、3之间//springboot
//设置userProperty:num = 2
SendResult result=rocketMQTemplate.syncSend("topic-test",MessageBuilder.withPayload("hello 瓜田李下 num=2").setHeader("num","2").build());
//设置userProperty:name=瓜田李下
SendResult result=rocketMQTemplate.syncSend("topic-test",MessageBuilder.withPayload("hello 瓜田李下 name=瓜田李下").setHeader("name","瓜田李下").build()); //sql过滤,num>4
@RocketMQMessageListener(consumerGroup = "consumerGroup4",topic = "topic-test",selectorType = SelectorType.SQL92,selectorExpression = "num>4")//sql过滤,name='瓜田李下'
@RocketMQMessageListener(consumerGroup = "consumerGroup5",topic = "topic-test",selectorType = SelectorType.SQL92,selectorExpression = "name='瓜田李下'")
事务消息(略)
redis
添加依赖
<!--集成redis-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-redis</artifactId><version>1.4.1.RELEASE</version>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.3</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId>
</dependency>
在配置中心里添加redis配置
spring.redis.host=127.0.0.1
#Redis服务器连接端口
spring.redis.port=6379
#Redis服务器连接密码(默认为空)
spring.redis.password=
#连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
#连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.pool.max-idle=8
#连接池中的最小空闲连接
spring.redis.pool.min-idle=0
#连接超时时间(毫秒)
spring.redis.timeout=30000
使用
@Autowired
private RedisTemplate redisTemplate;//写入缓存(string)
redisTemplate.opsForValue().set(key, value);
//删除对应的value
redisTemplate.delete(key);
//判断缓存中是否有对应的valuereturn redisTemplate.hasKey(key);
//读取缓存
redisTemplate.opsForValue().get(key);
//更新缓存
redisTemplate.opsForValue().getAndSet(key, value);
//写入缓存设置时效时间
redisTemplate.opsForValue().set(key, value);
redisTemplate.expire(key, expireTime, timeUnit);
//批量删除对应的value(传入keys)
for (String key : keys) {
remove(key);
}
//批量删除key
Set<Serializable> keys = redisTemplate.keys(pattern);
if (keys.size() > 0){
redisTemplate.delete(keys);
}//哈希 添加(hash)
redisTemplate.opsForHash().put(key,hashKey,value);
//哈希获取数据
redisTemplate.opsForHash().get(key,hashKey);
//列表添加(list)
redisTemplate.opsForList().rightPush(k,v);
//列表获取 获取指定区间的值
redisTemplate.opsForList().range(K key, long start, long end);
//集合添加(set)
redisTemplate.opsForSet().add(key,value);
//集合获取
redisTemplate.opsForSet().members(key);
//有序集合添加(zset)
redisTemplate.opsForZSet().add(key,value,scoure);
//有序集合获取 根据设置的score获取区间值。
redisTemplate.opsForZSet().rangeByScore(K key, double min, double max);
mysql
sql语句*
-- 新建表
CREATE TABLE table_name(column1 datatype,column2 datatype,column3 datatype,.....columnN datatype,PRIMARY KEY( one or more columns )
);-- 1. 新增 insert(1行记录受影响)
1.1 语法: insert into 表名 values (数据1,数据2,...数据n),(); 对表的所有的字段赋值
insert into tb_student values (2, 'jim1', 'n',90,200,'2020-01-01','2020-01-01 12:00:00','2020-01-01 12:00:00');1.2 语法: 指定字段新增(推荐)
insert into 表名 (字段1,字段2...字段n) values (数据1,数据2,...数据n);
mysql> insert into tb_student (id,stuname,score,createtime) values (4,'lucy',100,now());1.3 添加多条数据
insert into
items(name,city,price,number,picture)
VALUES
('耐克运动鞋','广州',500,1000,'003.jpg'),
('耐克运动鞋2','广州2',500,1000,'002.jpg');
这样,就实现了一次性插入了2条数据
--2. 删除 delete(>=0条记录受影响的)语法: delete from 表名 [where (字段)条件 and/or]; 条件删除delete from tb_student;-- 清空表数据mysql> delete from tb_student where id =3;mysql> delete from tb_student where id =1 and stuname ='jim1';
-- 3. 修改 update(>=0条记录受影响的)
语法:1. update 表名 set 字段名1=新值,字段名2=新值...字段名n=新值 [where (字段)条件 and/or];update tb_student set gender ='f';mysql> update tb_student set money=1000,birthday='2020-01-01', updatetime=now() where id=4;
select * from 表名;-- *: 通配的所有的字段名称
语法:(只要是查询一般后面都会where/order by/limit)select 字段名称1, 字段名称2,....from 表1,表2,.....[where 条件1 and/or 条件2]-- 过滤不符合条件的行记录[group by 字段1] -- 分组[having 条件]-- 对分组之后的数据进行过滤[order by 字段 asc/desc ]-- 对行记录进行排序 默认是升序 asc 降序: desc[limit start,size;]-- 限定查询的行记录 代表从第start条记录开始查询 查询size
//1. 条件查询 where
?条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
?=、!=、<>、<、<=、>、>=;
?BETWEEN…AND;是否满足一个区间范围 >= <=
?IN(set);条件的集合
?IS NULL;
?AND; 连接多个条件的查询
?OR;or 满足其中一个条件就可以
?NOT;-- ?查询年龄在20到40之间的学生记录
-- select * from stu where age>=20 and age <=40;
-- select * from stu where age BETWEEN 20 and 40; -- 查询学号为S_1001,S_1002,S_1003的记录
-- select * from stu where sid in ('s_1001','s_1002','s_1003');
-- ?查询学号不是S_1001,S_1002,S_1003的记录
-- select * from stu where sid not in ('s_1001','s_1002','s_1003');-- ?查询年龄为null的记录(字段值null is)
-- select * from stu where age is null;
-- 查询年龄不为null的学生记录
-- select * from stu where age is not null;//2. 模糊查询 like-- ?查询姓名由5个字母构成的学生记录 (模糊通配字母: _ )
-- select * from stu where sname like '_____';
-- ?查询姓名以“z”开头的学生记录(%: 通配任意量的内容)
-- select * from stu where sname like 'z%';
-- ?查询姓名中第2个字母为“i”的学生记录
-- select * from stu where sname like '_i%';//3.字段控制查询
-- 3.1 去重 distinct (单列)
-- 查询学生表里面所有的性别。
-- select DISTINCT gender from stu;
-- 3.2 null值运算
-- 把学生的年龄都+5(字段值null,算术运算 最后的结果都是null)
-- 需求: null-->0 ifnull(字段,新值)
-- select sid,sname,age, (ifnull(age,0)+5) from stu;
-- 查询员工的月薪和佣金之和
-- select empno,ename,sal,comm,sal+IFNULL(comm,0) from emp;
-- 3.3 别名查询 as(可以省略) 字段/表名 起别名查询(表名别名: 多表)
-- select e.empno,e.ename,e.sal,comm,sal+IFNULL(comm,0) as '月薪和佣金之和' from emp e;//4. 排序 order by
-- 按照多个字段值进行升序或者降序排列。 默认是升序 asc 降序: desc
-- ?查询所有学生记录,按年龄降序排序
-- SELECT * FROM stu ORDER BY age desc;
-- 查询所有雇员,按月薪降序排序,如果月薪相同时,按编号降序排序
-- SELECT * FROM emp ORDER BY sal desc,empno desc;//5. 分组查询
?COUNT():统计指定列不为NULL的记录行数;
?MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
?MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
?SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
?AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;-- count(参数) 统计表里面行记录(参数: 字段(一般都是主键列))
-- ?查询emp表中记录数:
-- select count(empno) as total,count(*),count(1) from emp;
-- ?统计月薪与佣金之和大于2500元的人数:
-- select count(*) from emp where sal+IFNULL(comm,0)>2500;
-- ?查询最高工资和最低工资
-- select max(sal)'最高工资',min(sal) '最低工资' from emp;
-- ?查询所有雇员月薪和,所有雇员佣金和,所有雇员月薪+佣金和 统计所有员工平均工资: :
-- select sum(sal),sum(IFNULL(comm,0)),sum(sal+IFNULL(comm,0)),avg(sal) from emp;
-- ?查询每个部门的部门编号以及每个部门的人数:
-- select deptno,count(*) from emp GROUP BY deptno;
-- ?查询每个部门的部门编号以及每个部门员工工资大于1500的人数:
-- select deptno,count(*) from emp where sal>1500 GROUP BY deptno;
-- ?查询工资总和大于9000的部门编号以及工资和:
-- ?where 不能与聚合函数使用 Invalid use of group function
-- ?分组之后的数据进行顾虑 having
-- select deptno,sum(sal) sum from emp GROUP BY deptno having sum>9000;//6. 关联查询
-- 关联查询(多表之间数据查询)---> 推荐
-- ?1.等值连接(连接的条件是=)
-- 查询员工信息,要求显示员工号,姓名,月薪,部门名称
-- 2张表 至少有1个条件 3张表 至少2个条件
-- select e.empno,e.ename,e.sal,d.dname,d.loc from emp e,dept d where e.deptno = d.deptno;
-- ?2.不等值连接(连接的条件不是=)
-- 查询员工信息,要求显示:员工号,姓名,月薪,薪水的级别
-- select e.empno,e.ename,e.sal,s.GRADE from emp e,salgrade s where e.sal BETWEEN s.LowSAL and s.HISAL;
-- select e.empno,e.ename,e.sal,d.dname,d.loc,s.GRADE from emp e,dept d,salgrade s where e.deptno = d.deptno and e.sal BETWEEN s.LowSAL and s.HISAL;
-- ?3.外连接
-- 查询每个部门的部门编号和每个部门的工资和: 基表: dept
-- 因为员工表没有员工在40号部门
-- ?a.内连接 inner join on/where ==> 等值连接
-- select d.*,count(*),sum(sal) from dept d INNER JOIN emp e where e.deptno = d.deptno GROUP BY e.deptno;
-- ?b.左外连接 以左表为基准 右表没有的数据以null进行填充 LEFT JOIN on
-- select d.*,count(e.empno),IFNULL(sum(e.sal),0) from dept d LEFT JOIN emp e on e.deptno = d.deptno GROUP BY e.deptno ORDER BY d.deptno;
-- ?c.右外连接 以右表为基准 左表没有的数据以null进行填充 RIGHT JOIN on
-- select d.*,count(e.empno),IFNULL(sum(e.sal),0) from emp e RIGHT JOIN dept d on e.deptno = d.deptno GROUP BY e.deptno ORDER BY d.deptno;
-- ?5. 子查询(查询条件的数据是未知的 级别最高)
-- 查询工资为20号部门平均工资的员工信息. 使用1条sql
-- select * from emp where sal = (select avg(sal) from emp where deptno = 20);
-- ?6.集合查询 union vs union all
-- 分库分表 mycat: 用户表: tb_user1 tb_user2 DISTINCT(单列)
-- 去除重复的行记录(多个列的数据)
-- select * from tb_user1
-- UNION
-- select * from tb_user2
-- UNION
-- select * from tb_user3;
-- 通过1条sql语句 查询3张表的数据。 union去除重复的行记录 union all 不去重
Mysql常用函数有哪几类
- 聚合函数
- 流程控制函数
- 数值型函数
- 字符串型函数
- 日期时间函数
聚合函数
MAX:查询指定列的最大值
MIN:查询指定列的最小值
COUNT:统计查询结果的行数
SUM:求和,返回指定列的总和
AVG:求平均值,返回指定列数据的平均值
流程控制函数
-
if:判断,流程控制
语法格式:
IF(expr,v1,v2)语法格式说明
- expr:表达式,返回 true、false、null
- v1:当expr = true时返回 v1
- v2:当expr = false、null 时返回v2
select name,if(is_enable = 1,“在职”,“离职”) “在职状态” from emp;
-
IFNULL:判断是否为空
语法格式:
IFNULL(v1,v2)语法格式说明
- 如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回 v2
- v1、v2 均可以是值或表达式
select id,name,ifnull(dept_id,“无部门”) “部门” from emp;
-
CASE:搜索语句
语法格式:
CASE <表达式>WHEN <值1> THEN <操作>WHEN <值2> THEN <操作>...ELSE <操作> END;语法格式说明
- 将 <表达式> 的值 逐一和 每个 when 跟的 <值> 进行比较
- 如果跟某个<值>想等,则执行它后面的 <操作> ,如果所有 when 的值都不匹配,则执行 else 的操作
- 如果 when 的值都不匹配,且没写 else,则会报错
SELECT name,dept_id, CASEdept_id WHEN 0 THEN"实习生" WHEN 1 THEN"销售部" WHEN 2 THEN"信息部" WHEN 2 THEN"财务部" ELSE "没有部门" END AS "部门" FROMemp;
数值型函数
| 函数名称 | 作用 | 语法格式 | 语法格式说明 | 小栗子 |
|---|---|---|---|---|
| abs | 求绝对值 | |||
| sqrt | 求二次方根 | |||
| pow 和 power | 两个函数的功能相同,返回参数的次方 | POW(x,y) | 函数对参数 x 进行 y 次方的求值 | SELECT POW(5,-2) |
| mod | 求余数 | mod(n,m) | 返回n除以m的余数,当然推荐直接%,方便快捷 | SELECT MOD(234, 10); |
| ceil 和?ceiling | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 | CEILING(X) CEIL(X) | 返回不小于X的最小整数值 | SELECT CEILING(1.23); |
| floor | 向下取整,返回值转化为一个BIGINT | FLOOR(X) | 返回不大于X的最大整数值 | SELECT FLOOR(1.23); |
| rand | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 | RAND() | 随机生成 0 - 1的浮点数 如果要指定指定范围的随机整数的话,需要用这个公式 FLOOR(i + RAND() * j) | # 生成 7 - 12的随机数 SELECT FLOOR(7 + (RAND() * 5)); |
| round | 对所传参数进行四舍五入 | ROUND(X) | 四舍五入返回整数 | SELECT ROUND(-1.23); |
| sign | 返回参数的符号 | SIGN(X) | 返回 X 的符号标志,负数 = -1,整数 = 1,零 = 0 、 **字符串:**中文 = 0,负数开头 = -1,正数开头 = 1,字母开头 = 0 | SELECT SIGN(“1s1”); # 1 |
字符串函数
| 函数名称 | 作用 | 语法格式 | 语法格式说明 |
|---|---|---|---|
| length | 计算字符串长度函数,返回字符串的字节长度 | length(str) | **注意:**使用 uft8 编码字符集时,一个汉字是 3 个字节,一个数字或字母是一个字节 |
| concat | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 | CONCAT(sl,s2,…) | 1.可以连接多个哦2.若任何一个参数为NULL,则最终也返回NULL |
| insert | 替换字符串函数 | INSERT(str,pos,len,newstr) | **str:**指定字符串 **pos:**开始被替换的位置 **len:**被替换的字符串长度 **newstr:**新的字符串 |
| lower | 将字符串中的字母转换为小写 | LOWER(str) | 将所有字符串更改为小写,然后返回 |
| upper | 将字符串中的字母转换为大写 | UPPER(str) | 将所有字符串更改为大写,然后返回 |
| left | 从左侧字截取符串,返回字符串左边的若干个字符 | LEFT(str,len) | 返回字符串 str 中最左边的 len 个字符;如果任何参数为NULL,则返回NULL |
| right | 从右侧字截取符串,返回字符串右边的若干个字符 | RIGHT(str,len) | 返回字符串 str 中最右边的 len 个字符;如果任何参数为NULL,则返回NULL。 |
| trim | 删除字符串左右两侧的空格 | TRIM(s) | 删除字符串左右两侧的空格 |
| replace | 字符串替换函数,返回替换后的新字符串 | REPLACE(s,s1,s2) | s:指定字符串 s1:需要替换掉的字符串 s2:新的字符串 |
| substring | 截取字符串,返回从指定位置开始的指定长度的字符换 | SUBSTRING(s,n,len) | s:指定字符串 n:起始位置,从1开始 len:截取的长度 |
| substring _index | 根据分隔符分割字符串,可以指定分隔符匹配次数 | SUBSTRING_INDEX(str, delim, count) | **str:**需要操作的字符串 **delim:**分隔符 **count:**匹配 delim 出现的次数,可正数可负数 |
| reverse | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 | reverse(s) | 将字符串反转,即顺序取反 |
| strcmp | 比较两个表达式的顺序 | STRCMP(expr1,expr2) | |
| regexp | 字符串是否匹配正则表达式 | <列名> regexp ‘正则表达式’ | |
| locate | 返回第一次出现子串的位置 | LOCATE(substr,str) | 返回 substr 在 str 中第一次出现的位置 |
| instr | 返回第一次出现子串的位置 | INSTR(str,substr) | 返回 substr 在 str 中第一次出现的位置 |
日期时间函数
| 函数名称 | 作用 | 语法格式 | 语法格式说明 |
|---|---|---|---|
| curdate?和 current_date | 两个函数作用相同,返回当前系统的日期值 | CURDATE() | 以字符串或数字形式使用该函数, 以 ‘YYYY-MM-DD’ 或 YYYYMMDD 格式返回当前日期 |
| curtime 和 current_time | 两个函数作用相同,返回当前系统的时间值 | CURTIME([fsp]) | fsp:可以指定 0 - 6 位的秒精度;不写就只返回时分秒,不会精确到毫秒 |
| now | 返回当前系统的日期和时间值 | NOW([fsp]) | 同上 |
| date | 获取指定日期时间的日期部分 | DATE(expr) | |
| time | 获取指定日期时间的时间部分 | TIME(expr) | |
| month | 获取指定日期中的月份 | MONTH(date) | date:可以是指定的具体日期,也可以是日期表达式 |
| dayname | 获取指定曰期对应的星期几的英文名称 | DAYNAME(date) | 同上 |
| dayofmonth 和 Dday | 两个函数作用相同,获取指定日期是一个月中是第几天,返回值范围是1~31 | DAYOFMONTH(date) | 同上 |
| time_to_sec | 将时间参数转换为秒数 | TIME_TO_SEC(time) | **重点:**是指将传入的时间转换成距离当天00:00:00的秒数,00:00:00为基数,等于 0 秒 |
| sec_to_time | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 | SEC_TO_TIME(seconds) | **重点:**是指将传入的时间转换成距离当天00:00:00的秒数,00:00:00为基数,等于 0 秒 |
| datediff | 返回两个日期之间的相差天数 | DATEDIFF(expr1,expr2) | 1.返回 expr1 - expr2 的相差天数 2.expr 可以是具体的日期,也可以是日期表达式(即日期函数) 3.计算仅使用 expr 的日期部分,不会管时分秒部分 |
mybatis
SqlSession的getMapper方法
- 映射文件的namespace必须是接口的全名称
- id必须是接口中的方法名
//1.先写接口
public interface BlogMapper {
//传入整数 返回实体类对象public TestUser selectById(Integer bid);//传入对象 返回实体类对象public TestUser selectTestUser(TestUser b);//传入map集合 返回实体类对象public TestUser selectTestUserMapParam(Map<String,Object> map);//内部仍然是把参数封装为map,把@Param注解的值作为keypublic TestUser selectTestUserParam(@Param("bid_param")Integer bid, @Param("bname_param") String bname);//传入注解值 返回List public List<TestUser> selectTestUsers(@Param("by") String by, @Param("sort") String sort);//传入整数 返回数据库字段内容public String selectTitleById(Integer bid);
}
//2. xml映射文件配置<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--namespace:接口的全名称-->
<mapper namespace="com.javasm.sys.mapper.BlogMapper"><!--id:必须是接口的方法名,--><select id="selectById" resultType="TestUser"><!--#{
bid} 这个里面随便写 #{
a} #{
ccc} #{
id} 都可以去得到方法传过来的Integer值 不可以空的#{
}-->select * from testuser where bid = #{
bid}</select><!--#{
传入对象的成员变量名}--><select id="selectTestUser" resultType="TestUser">select * from testuser where bid = #{
bid}</select><!--#{
map的key}--><select id="selectTestUserMapParam" resultType="TestUser">select * from testuser where bid = #{
bid_key}</select><!--#{
@Param注解的值}--><select id="selectTestUserParam" resultType="TestUser">select * from testuser where bid=#{
bid_param} and bname=#{
bname_param}</select><select id="selectTestUsers" resultType="TestUser">select * from testuser order by ${
by} ${
sort}</select><select id="selectTitleById" resultType="string">select bname from testuser where bid=#{
bid}</select>
</mapper>
//3.运行
public class TestGetMapper {
public static void main(String[] args) {
InputStream in = TestGetMapper.class.getClassLoader().getResourceAsStream("mybatis-config.xml");SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(in);SqlSession s = ssf.openSession();BlogMapper mapper = s.getMapper(BlogMapper.class);//传入整数 返回实体类对象TestUser blog = mapper.selectById(1);//传入对象 返回实体类对象TestUser t = new TestUser();t.setBid(1);TestUser blog = mapper.selectTestUser(t);// 传入map集合 返回实体类对象Map<String,Object> map = new HashMap<>();map.put("bid_key",2);System.out.println(map);TestUser blog = mapper.selectTestUserMapParam(map);// 内部仍然是把参数封装为map,把@Param注解的值作为keyTestUser blog = mapper.selectTestUserParam(3,"bbb");// 传入注解值 返回ListList<TestUser> blog = mapper.selectTestUsers("bid", "desc");// 传入整数 返回数据库字段内容String blog = mapper.selectTitleById(1);System.out.println(blog);s.close();}
}
如何多参数传递
5.1 封装实体
5.2 封装map,适合于多参数不属于同一个实体
5.3 加注解@Param,加到mapper接口的方法形参上
例子参考上面
公共sql语句块
//id名字随意命名 不过要对应下边的<include refid="allFields"></include><sql id="allFields">uid,uname,uphone,upwd,uemail,create_time,update_time,rid</sql><select id="selectUserById" resultType="Sysuser">select<include refid="allFields"></include>from sysuser where uid = #{
uid}</select>
动态sql
动态sql:在xml映射文件中进行sql拼接if:条件判断,传入boolean表达式,多条件使用and或orwhere:生成where关键字,并忽略紧跟其后的and或or,如果where中间的是空的,则不生成where了set:生成set关键字,并忽略最后一个逗号.foreach:遍历数组和集合参数,批量删除,批量添加choose-when-otherwise:单条件查询 只会根据到第一个匹配到的进行查询 不常用
//where:生成where关键字,并忽略紧跟其后的and或or,如果where中间的是空的,则不生成where了
public List<Sysuser> selectUsers(Sysuser suser);//多条件查询//映射语句<select id="selectUsers" resultType="Sysuser" parameterType="Sysuser">select * from sysuser<where><if test="uid!=null">and uid=#{
uid}</if><if test="uname!=null and uname!=''">and uname=#{
uname}</if><if test="uphone!=null and uphone!=''">and uphone=#{
uphone}</if><if test="upwd!=null and upwd!=''">and upwd=#{
upwd}</if><if test="uemail!=null and uemail!=''">and uemail=#{
uemail}</if></where>order by update_time desc</select>
// set:生成set关键字,并忽略最后一个逗号. public int updateUserByIdSelective(Sysuser suser);//选择非空字段更新//映射语句<update id="updateUserByIdSelective" parameterType="sysuser">update sysuser<set><if test="uname!=null">uname=#{
uname},</if><if test="uphone!=null and uphone!=''">uphone=#{
uphone},</if><if test="upwd!=null and upwd!=''">upwd=#{
upwd},</if><if test="uemail!=null and uemail!=''">uemail=#{
uemail},</if></set>where uid=#{
uid}</update>
//foreach:遍历数组和集合参数,批量删除,批量添加//批量添加public int addUsers(Sysuser[] suser);//批量添加用户//映射语句<insert id="addUsers">insert into sysuser(uname,upwd,uphone,uemail,rid) values<foreach collection="array" separator="," item="suser">(#{
suser.uname},#{
suser.upwd},#{
suser.uphone},#{
suser.uemail},#{
suser.rid})</foreach></insert>//批量删除 public int deleteUsersByIds(@Param("uids") Integer[] uids);
//批量删除,mybatis底层把参数封装为map,默认key为:array,map.put("array",Integer[]) //映射语句<!--collection:形参为数组写array|形参为list写list (1,2,3)--><delete id="deleteUsersByIds">delete from sysuser where uid in<foreach collection="uids" open="(" close=")" separator="," item="userid">#{
userid}</foreach></delete>
//choose-when-otherwise:单条件查询 只会根据到第一个匹配到的进行查询
public List<Sysuser> selectUsersOneCondition(Sysuser suser);//单条件查询//映射语句<select id="selectUsersOneCondition" resultType="Sysuser" parameterType="Sysuser">select * from sysuser<where><choose><when test="uid!=null">uid=#{
uid}</when><when test="uname!=null and uname!=''">uname=#{
uname}</when><when test="uphone!=null and uphone!=''">uphone=#{
uphone}</when><otherwise></otherwise></choose></where>order by update_time desc</select>
insert|update|deleted
这三个标签都没有resultType属性,操作结果需要靠接口的返回值来判断。返回值int受影响行数.
insert
public interface BlogMapper {
public int addUser(Trole tro);public int addUsers(Trole[] tro);//批量添加用户public int addUserAndGetUserId(Trole tro);
}
//映射语句
<mapper namespace="com.javasm.sys.mapper.BlogMapper">//如果role_Name或createTime实体类没有内容那么数据库就会赋值null 别的没有的直接默认值或者null<insert id="addUser" parameterType="Trole">insert into trole ( role_Name,createTime ) values ( #{
roleName},#{
createTime} )</insert>//mybatis底层把参数封装为map,默认key为:array,map.put("array",Trole[])//如果加入注解 key为:注解的值, 假如多参数传入了gid 里面也可以直接取#{gid}传入的值 //foreach就相当于一个循环// <foreach collection="array" separator="," item="tro">// (#{gid},#{tro.createTime})// </foreach><insert id="addUsers">insert into trole ( role_Name,createTime ) values<foreach collection="array" separator="," item="tro">(#{
tro.roleName},#{
tro.createTime})</foreach></insert>// 如果数据库是主键自增的,在insert标签中useGeneratedKeys="true" keyProperty="形参对象的属性名" 获取自增主键id//然后通过实体类.getrid获取<insert id="addUserAndGetUserId" parameterType="Trole" useGeneratedKeys="true" keyProperty="rid" >insert into trole ( role_Name,createTime ) values ( #{
roleName},#{
createTime} )</insert>
</mapper>
//Test
public class TsetInser {
private static SqlSessionFactory factory = null;private SqlSession s = null;//最开始的时候走这里一次 ---------- @BeforeClass@BeforeClasspublic static void init(){
factory = SessionFactoryUtil.getFactory();}//每次进方法的时候走这里一次 ---------- @Before@Beforepublic void oppension(){
s = factory.openSession();}@Testpublic void test1_addUser(){
BlogMapper mapper = s.getMapper(BlogMapper.class);Trole user = new Trole();user.setRoleName("员工si");int i = mapper.addUser(user);s.commit();System.out.println(i);}@Testpublic void test1_addUsers(){
BlogMapper mapper = s.getMapper(BlogMapper.class);Trole a = new Trole();Trole b = new Trole();Trole c = new Trole();a.setRoleName("a");b.setRoleName("b");c.setRoleName("c");Trole[] user = new Trole[]{
a,b,c};int i = mapper.addUsers(user);s.commit();System.out.println(i);}@Testpublic void test1_addUserAndGetUserId(){
BlogMapper mapper = s.getMapper(BlogMapper.class);Trole user = new Trole();user.setRoleName("员工s");int i = mapper.addUserAndGetUserId(user);s.commit();System.out.println(i);System.out.println(user.getRid());}//每个方法退出后走这里一次 ---------- @After@Afterpublic void closeSession(){
s.close();}//最后的最后走这里一次 ---------- @AfterClass@AfterClasspublic static void destory(){
factory=null;System.out.println("destory");}
}update
public interface BlogMapper {
public int updateUserById(Trole tro);//全字段更新public int updateUserByIdSelective(Trole tro);//选择非空字段更新
}
//update映射语句
<mapper namespace="com.javasm.sys.mapper.BlogMapper">//只更新sql包括的内容 没有复制的会把数据库里已有的内容改成null<update id="updateUserById" parameterType="Trole">update trole set role_Name=#{
roleName},createTime=#{
createTime} where r_id=#{
rid}</update>//通过set if标签实现 选择非空字段更新 <update id="updateUserByIdSelective" parameterType="Trole">update trole<set><if test="roleName!=null">role_Name=#{
roleName},</if><if test="createTime!=null and createTime!=''">createTime=#{
createTime},</if></set>where r_id=#{
rid}</update>
</mapper>
deleted
public interface BlogMapper {
public int deleteUserById(Integer uid);//批量删除,mybatis底层把参数封装为map,默认key为:array,map.put("array",Integer[])public int deleteUsersByIds(@Param("rids") Integer[] rids);//批量删除mybatis底层把参数封装为map,默认key为:list,map.put("list",Integer[])public int deleteUsersByIds2(List<Integer> rids);
}
//deleted映射语句
<mapper namespace="com.javasm.sys.mapper.BlogMapper"><delete id="deleteUserById" parameterType="Integer">delete from trole where r_id=#{
rid}</delete>//批量删除,mybatis底层把参数封装为map,默认key为:array,map.put("array",Integer[])//item可随意输入 只要对应#{ccc}<delete id="deleteUsersByIds">delete from trole where r_id in<foreach collection="rids" open="(" close=")" separator="," item="ccc">#{
ccc}</foreach></delete>//批量删除mybatis底层把参数封装为map,默认key为:list,map.put("list",Integer[])//item可随意输入 只要对应#{ccc}<delete id="deleteUsersByIds2">delete from trole where r_id in<foreach collection="list" open="(" close=")" separator="," item="ccc">#{
ccc}</foreach></delete>
</mapper>
resultMap:结果集映射
实体类属性名与数据库的字段名不一致;
//column-数据库字段名 property-实体类属性名
<resultMap id="自定义" type="实体类别名"><id column="" property="">主键列映射<result column="" property=""> 非主键列映射e
collection,association对象关系映射
resultMap的子标签
关联查询:查询用户对象的时候,把用户的角色对象关联查询出来。
关联返回的List用collection 关联返回的对象用association
//三种方法 关联查询
//1.手工发起两次查询。
//2.mybatis内部发起二次查询,需要通过ResultMap的标签的association关系标签来指定二次查询的位置
//3.sql语句使用表关联查询,一次查询把所有结果查询出来,然后把结果列映射到不同的对象中 (不推荐)
//实体类属性表
public class Sysrole {
private Integer rid;private String rname;private List<Sysuser> userList;//角色对象聚合了用户对象
}
linux常用命令