大家好,我是雷恩Layne,这是《深入浅出flink》系列的第三篇文章,我旨在用最直白的语言写好flink,希望能让所有看到的人一目了然。如果大家喜欢,欢迎点赞、关注,也欢迎留言,共同交流flink的点点滴滴 O(∩_∩)O
文章目录
-
- 1. Job、Task、SubTask、Slot、Slotsharing、Thread、Parallelism的概念
- 2. DataFlow、StreamGraph、JobGraph、ExecutionGraph的转化过程
- 3. Stream partition、One-to-one、Redistributing、Operator Chains的原理
本文是理解flink整个架构的核心,是最基础也是必须要掌握的知识,只有完全理解了它们,你才会在以后学习flink时游刃有余,才能更好的进阶flink高阶知识。
那么,我们就开始吧!
我们知道,用户在客户端提交一个作业(Job)到服务端。服务端为分布式的主从架构。JobManager(master)负责计算资源(TaskManager)的管理、任务的调度、检查点(checkpoint)的创建等工作,而TaskManager(worker)负责SubTask的实际执行。当服务端的JobManager接收到一个Job后,会按照各个算子的并发度将Job拆分成多个SubTask,并分配到TaskManager的Slot上执行。

那么,Slot是什么,它是通过什么运行任务的?它是线程又是什么关系?不同SubTask之间是如何关联在一起的?Slot又该如何管理task?让我们带着这些问题继续往下看!
1. Job、Task、SubTask、Slot、Slotsharing、Thread、Parallelism的概念
本小节就来对Flink涉及到的Job、Task、SubTask、 Slot、Slotsharing、Thread、Parallelism等概念进行详细介绍。
首先,Job最容易理解,一个Job代表一个可以独立提交给Flink执行的作业,我们向JobManager提交任务的时候就是以Job为单位的,只不过一份代码里可以包含多个Job(每个Job对应一个类的main函数)。
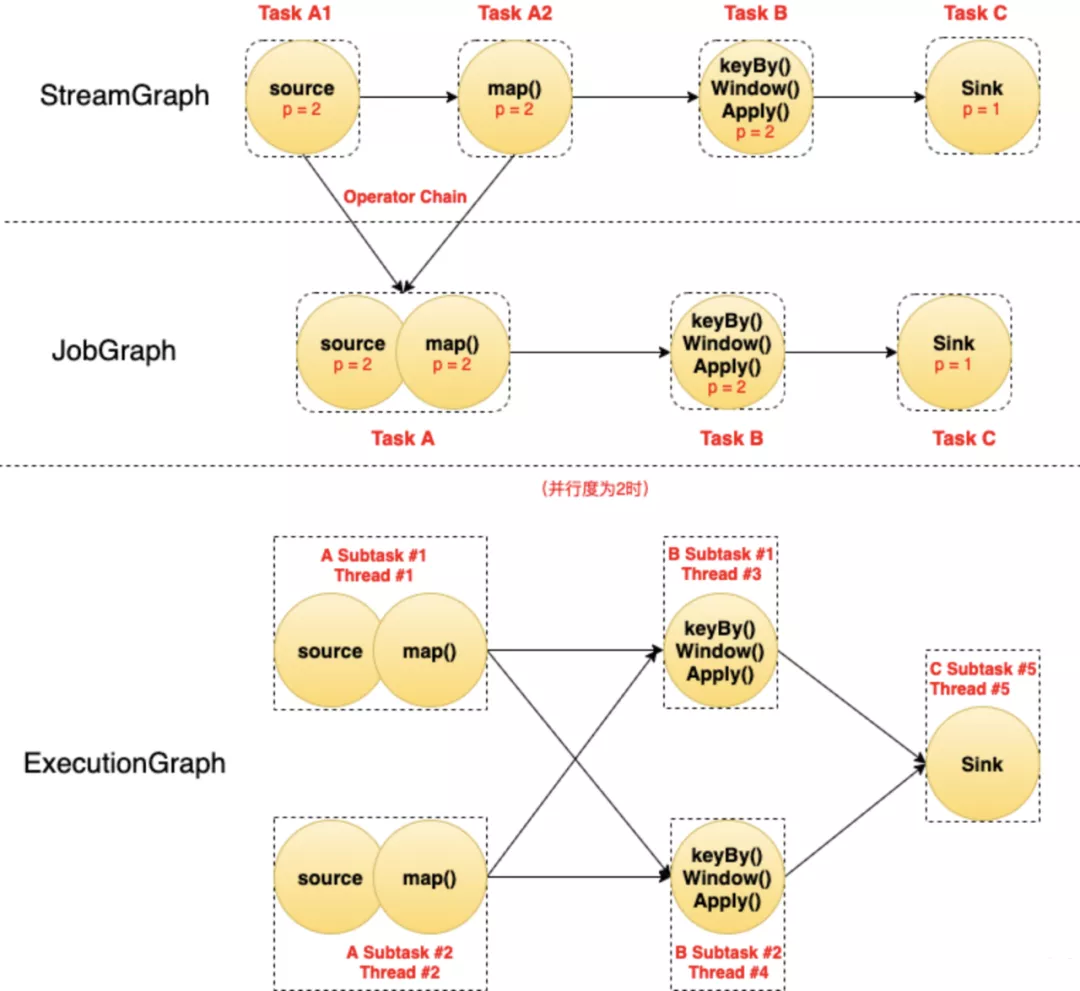
说明如下:
- 图中每个圆代表一个Operator(算子),每个虚线圆角框代表一个Task,每个虚线直角框代表一个Subtask,其中的p表示算子的并行度。
- 最上面是StreamGraph,在没有经过任何优化时,可以看到包含4个Operator/Task:Task A1、Task A2、Task B、Task C。
- StreamGraph经过Chain优化(后面讲)之后,Task A1和Task A2两个Task合并成了一个新的Task A(可以认为合并产生了一个新的Operator),得到了中间的JobGraph。
- 然后以并行度为2(需要2个Slot)执行的时候,Task A产生了2个Subtask,分别占用了
Thread #1和Thread #2两个线程;Task B产生了2个Subtask,分别占用了Thread #3和Thread #4两个线程;Task C产生了1个Subtask,占用了Thread #5。
由此可以总结如下:
-
Task是逻辑概念,一个Operator就代表一个Task(多个Operator被chain之后产生的新Operator算一个Operator);
-
真正运行的时候,Task会按照并行度分成多个Subtask,Subtask是执行/调度的基本单元;
-
每个Subtask需要一个线程(Thread)来执行。
前面讲了TaskManager才是真正干活的,启动的时候,它会将自己的资源以Slot的方式注册到master节点上的资源管理器(ResourceManager)。JobManager从ResourceManager处申请到Slot资源后将自己优化过后的SubTask调度到这些Slot上面去执行。在整个过程中SubTask是调度的基本单元,而Slot则是资源分配的基本单元。需要注意的是目前Slot只隔离内存,不隔离CPU。
对于Flink而言,slot其实就是执行一个独立子任务(或执行一个独立线程)所需要的一组资源的最小单元,每一个slot拥有自己独享的内存,多个slot运行时的状态,互不干扰。slot一般是不单独分配cpu资源的,比如一个cpu运行两个slot时,可以通过并行(即时间片轮询)的方式来执行。尽管slot并不单独分配cpu资源,我们可以通过当前taskmanger的cpu core数量来设置slot数,这样一个slot占用一个cpu core,可以更快的执行。
为了更高效地使用资源,Flink默认允许同一个Job中不同Task的SubTask运行在同一个Slot中,这就是SlotSharing(子任务共享)。注意以下描述中的几个关键条件:
-
必须是同一个Job。这个很好理解,slot是给Job分配的资源,目的就是隔离各个Job,如果跨Job共享,但隔离就失效了;
-
必须是不同Task的Subtask。这样是为了更好的资源均衡和利用。一个计算流中(pipeline),每个Subtask的资源消耗肯定是不一样的,如果都均分slot,那必然有些资源利用率高,有些低。限制不同Task的Subtask共享可以尽量让资源占用高的和资源占用低的放一起,而不是把多个高的或多个低的放一起。比如一个计算流中,source和sink一般都是IO操作,特别是source,一般都是网络读,相比于中间的计算Operator,资源消耗并不大。相反,如果是同一个Task的Subtask放在一个slot中执行,我们就违背了并行执行的初心,放在一个slot不就是串行执行了。
-
默认是允许sharing的,可以通过
slotSharingGroup给不同算子设置不同的共享组,关闭这个特性。不同共享组的算子一定在两个slot中。
共享组内的子任务可以共享同一个slot,而不同共享组中的任务一定不能在同一个slot中执行。如果一个算子不设置共享组,默认和前一个算子操作的共享组是一样的。第一个算子不设置共享组,那么它的共享组名字是default。
下面我们依次来看看官方文档给出的两幅图:

图中两个TaskManager节点共有6个slot,5个SubTask,其中sink的并行度为1,另外两个SubTask的并行度为2。此时由于Subtask少于Slot个数,所以每个Subtask独占一个Slot,没有SlotSharing。这样可能会有三个缺点:
- 第一,每个Subtask的资源消耗肯定是不一样的,如果不同的Subtask分布在不同的slot中,很可能会导致“一半火山一半冰山”的情况(即忙的忙死,闲的闲死)。
- 第二,因为每一个slot都执行的是不同的Subtask,每一个Slot不包含完整的Pipline,会频繁发生不同slot或不同TaskManager数据的交互(即会产生许多不必要的Shuffle),降低Job执行的效率。
- 第三,正是因为每一个slot都执行的是不同的Subtask,每一个Slot不包含完整的Pipline,所以每一个slot的执行进度必然各不相同,这样很可能会发生一个slot在等待其它slot的执行结果,从而造成任务等待停滞的情况。
下面我们把把并行度改为6:

此时,Subtask的个数多于Slot了,所以出现了SlotSharing。一个Slot中分配了多个Subtask,特别是最左边的Slot中跑了一个完整的Pipeline。这样做可以解决上面三个缺点:
- 第一,每一个任务都包含了Pipeline的绝大部分,每一个Slot的中的SubTask计算流都大致相同,这样每一个Slot消耗的IO和cpu资源大致相同,几乎不会出现“一半火山一半冰山”的情况。
- 第二,因为每一个任务都包含了Pipeline的绝大部分,这样的话如果没有重分区的算子,不同slot或不同taskmanager很少会发生数据的交互,效率特别高。
- 第三,正因为每一个任务都包含了Pipeline的绝大部分,不同slot或不同taskmanager很少会发生数据的交互,所以很少会出现因为等待数据导致Job停滞的情况。另外,每一个slot的执行进度大致相同,就算要进行数据交互,发生Job长时间等待停滞的情况概率也很小。
一个特定算子的Subtask的个数被称之为其并行度(parallelism)。一般情况下,一个流程序(即Job)的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
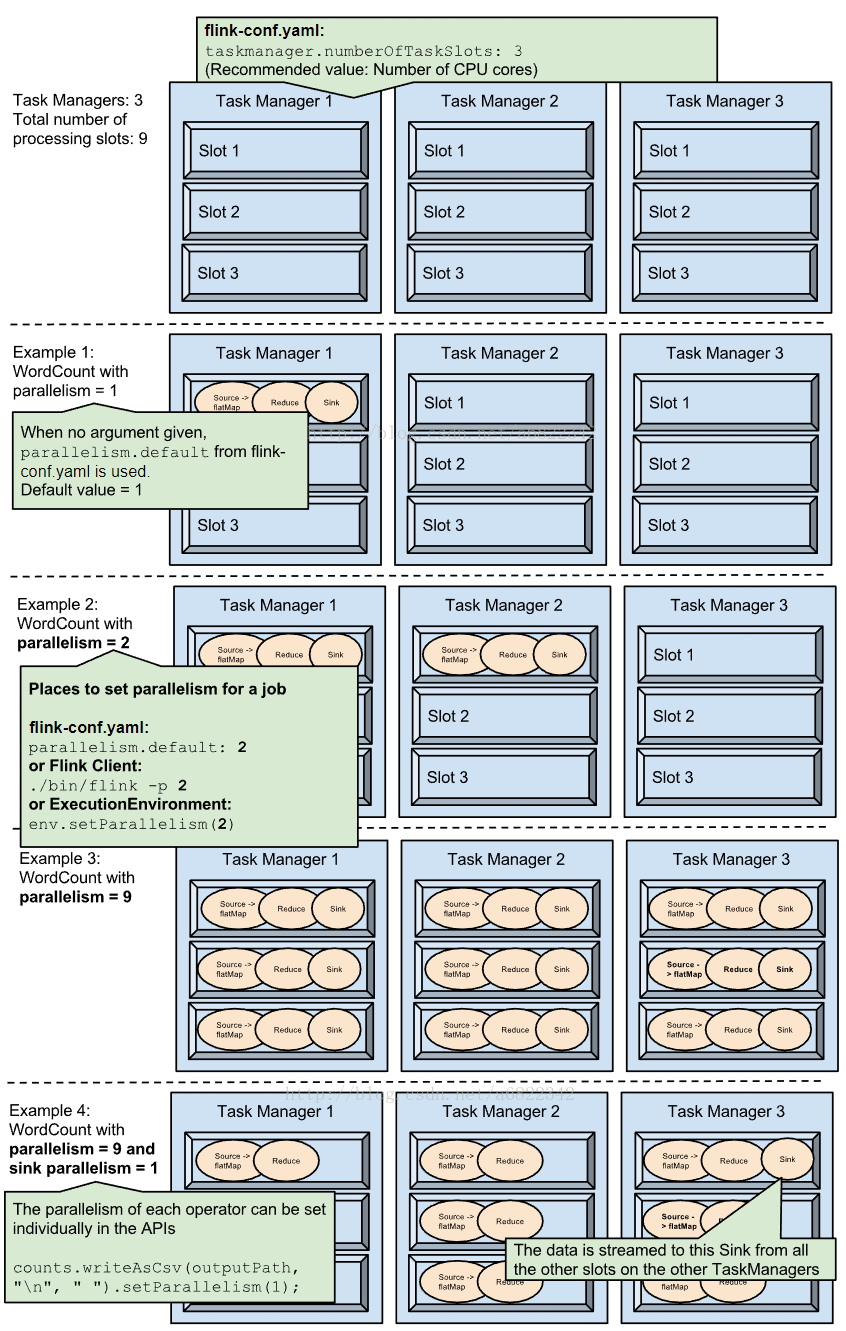
Task Slot是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置。而并行度parallelism是动态概念,即TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
也就是说,假设一共有3个TaskManager,每一个TaskManager中的分配3个TaskSlot,也就是每个TaskManager可以接收3个task,一共9个TaskSlot,如果我们设置parallelism.default=1,即运行程序默认的并行度为1,9个TaskSlot只用了1个,有8个空闲,因此,设置合适的并行度才能提高效率。
下面是4个Example,介绍了不同parallelism下Subtask在Slot中的分布情况:
2. DataFlow、StreamGraph、JobGraph、ExecutionGraph的转化过程
所有的Flink程序都是由三部分组成的: Source 、Transformation和Sink。Source负责读取数据源,Transformation利用各种算子进行处理加工,Sink负责输出。Source 、Transformation和Sink共同构成了“逻辑数据流”(dataflows)。
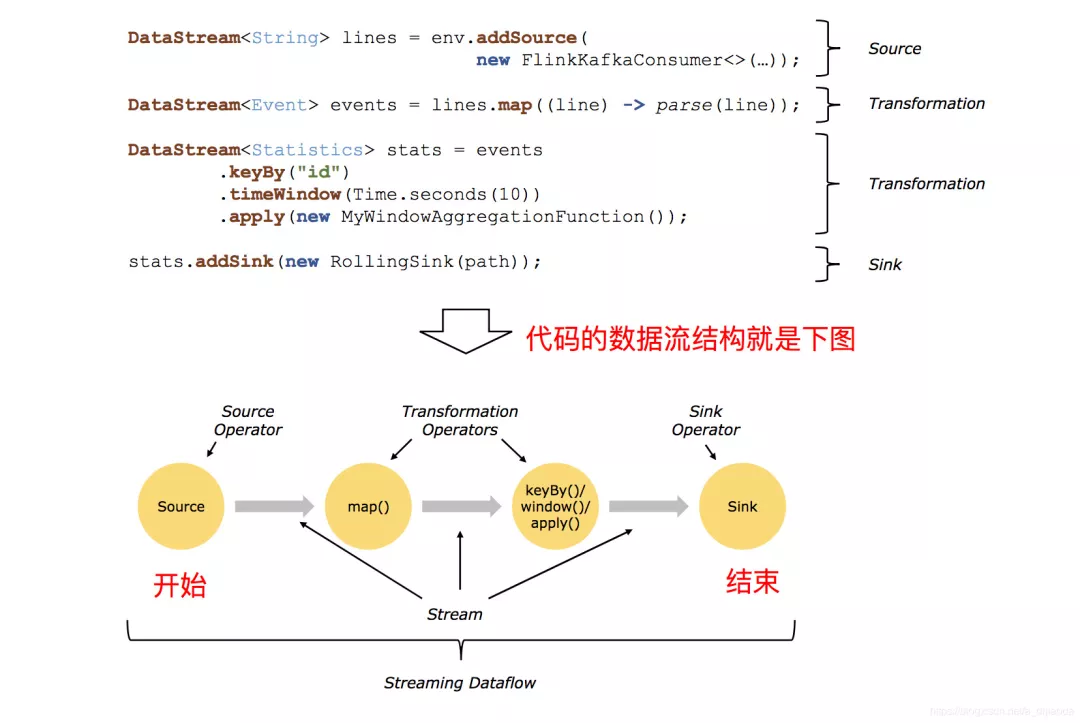
在运行时,Flink上运行的程序会被映射成“逻辑数据流”(dataflows)。每一个dataflow以一个或多个sources开始以一个或多个sinks结束。dataflow类似于任意的有向无环图(DAG)。在大部分情况下,程序中的转换运算(transformations)跟dataflow中的算子(operator)是一一对应的关系,但有时候,一个transformation可能对应多个operator(因为Operator Chains的存在)。

由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图)。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。在Client上进行。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 。主要的优化为,将多个符合条件的Task(即算子或Operator) chain 在一起作为一个Task,这样可以减少数据在Task之间流动所需要的序列化/反序列化/传输消耗。在Client上进行。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager上部署 Task 后形成的“图”,并不是一个具体的数据结构。
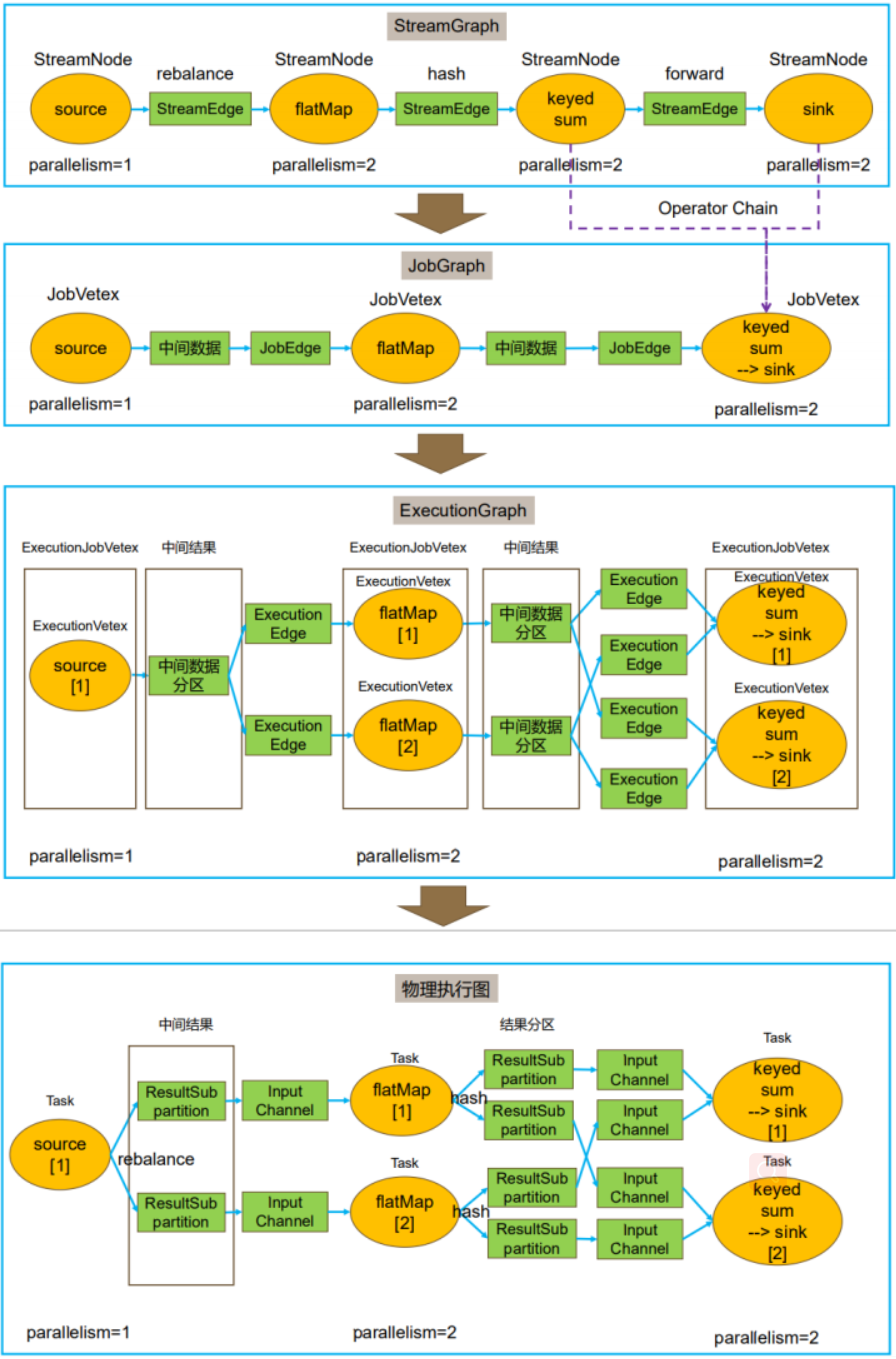
注:上图StreamGraph中的keyBy和sum算子之所以一开始就在一个Operator中,是因为keyBy严格上不算一个计算算子,它只是根据key的hash确定往下划分到哪一个分区(即哪一个slot上),然后在对应的slot上计算sum。
3. Stream partition、One-to-one、Redistributing、Operator Chains的原理
在执行过程中,一个流(stream)包含一个或多个分区(Stream partition)。TaskManager中的一个slot就是一个stream partition,一个Job的流(stream)分布在多个不同的Slot上执行。对于算子来说,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。
流(stream)指正在执行过程中的流程序,可分布在多个slot中执行。
程序(Job)中每一个算子(operator),在实际执行中根据Parallelism被分隔为多个SubTask,数据流在算子之间的流动,就对应到SubTask之间的数据传递,SubTask之间进行数据传递模式有两种,一种是one-to-one(forwarding)模式,另一种是redistributing的模式。
Stream在算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
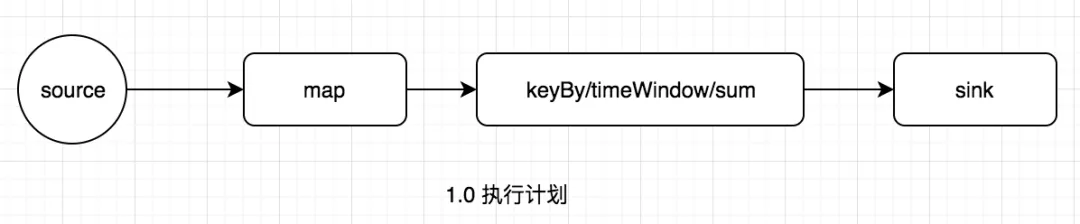
- One-to-one:数据不需要重新分布,上游SubTask生产的数据与下游SubTask受到的数据完全一致,数据不需要重分区,也就是数据不需要经过IO,比如上图中source->map的数据传递形式就是One-to-One方式。常见的map、fliter、flatMap等算子的SubTask的数据传递都是one-to-one的对应关系。类似于spark中的窄依赖。
- Redistributing:数据需要通过shuffle过程重新分区,需要经过IO,比如上图中的map->keyBy。创建的keyBy、broadcast、rebalance、shuffle算子的SubTask的数据传递都是Redistributing方式,但它们具体数据传递方式是不同的。类似于spark中的宽依赖。
这里补充一下我对Spark和FlinkShuffle的理解。
我认为Flink和Spark中 shuffle的概念不一样,之所以这样说是因为Spark中的Shuffle是洗牌的概念,即所有数据来了,把数据重组一下。而Flink中的数据是源源不断过来的,更像是发牌的意思,即来一张牌(数据)计算之后把它发出去(传到下一个算子的subTask)。这本质上还是批处理和流处理的区别。
简单介绍一下keyBy、rebalance、shuffle、broadcast算子数据传递方式的区别:
- keyBy:根据上游subTask产出数据的key的hashcode进行分区
- rebalance:轮询发送数据。举个例子,比如A算子作为上游算子,有3个SubTask,占3个Slot(即并行度为3);下游B算子是rebalance,有2个SubTask,占2个Slot(即并行度为3);数据传递形式是:A的SubTask1中第一个数据发送到B的Slot1,A的SubTask1中第二个数据发送到B的Slot2, A的SubTask1中第三个数据发送B的Slot1,同理,A的SubTask1和SubTask2也是如此。
- Shuffle:Shuffle算子是完全随机发送数据。
- broadcast:给下游算子所有的subtask都广播一份数据
Flink为了提高性能,将并行度相同且关系为one-to-one的前后两个subtask,融合形成一个task。而TaskManager中一个task运行一个独立的线程中,同一个线程中的SubTask进行数据传递,不需要经过IO,不需要经过序列化,直接发送数据对象到下一个SubTask,性能得到提升,除此之外,subTask的融合可以减少task的数量,提高taskManager的资源利用率。这个过程就是任务链(Operator Chains)。
图1.0中的执行计划,优化结果如下图:

Operator Chains过程的几个条件可以概括为:
- 并发度相同的前后两个算子的subtask
- 前后的subtask的数据传递关系为one-to-one
- 前后两个算子必须是在同一个共享组中
下图展示了Opeator Chain在数据流图中的过程:
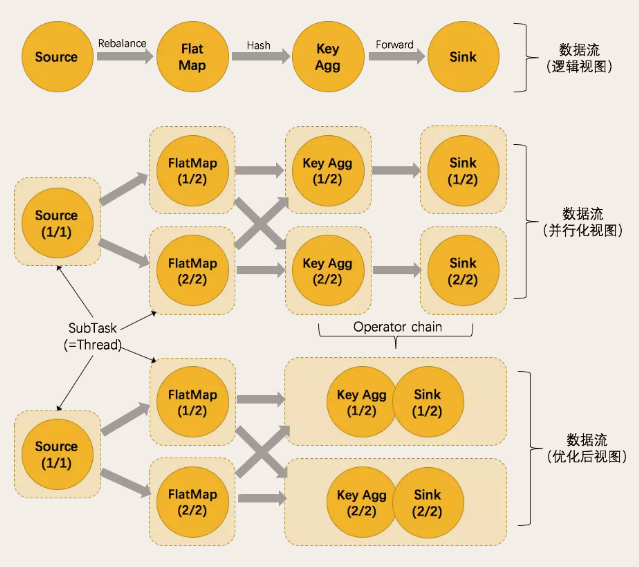
满足上面这三个条件,一定会执行Operator Chains,如果我们不想合并怎么办?
可以设置不同的共享组,虽然设置不同的共享组可以避免Operator Chains,但是不同的共享组的task一定会出现在不同的slot上。现在我们还想slot可以共享,但是不想让其合并,那怎么办呢?可以做重分区操作(通过rebanlce或shuffle)来避免合并,但这又不增加了不必要的Shuffle。这里还有一个另外的操作,即disableChaining,这也是推荐的方式。设置disableChaining的算子意味着无论当前什么操作,都不会进行合并成任务链(即当前算子前后都断开)。也可以通过env.disableOperatorChaining()全局禁止所有的操作合并任务链。如果我们想前面断开后面符合条件可合并,可以在后面的算子设置startNewChain()。
任务链(Operator Chains)和 SlotSharing(子任务共享)有什么区别?
SlotSharing(子任务共享)是让同一个Job中不同Task的SubTask运行在同一个Slot中,它的目的是为了更好的均衡资源,避免不同的Slot出现“一半火山一半冰山”的情况。如果没有重分区的算子(即只有one-to-one的数据传递模式),它是不会有不同slot或不同taskmanager数据交互的,并且同一个线程中的SubTask进行数据传递,不需要经过IO,不需要经过序列化,直接发送数据对象到下一个SubTask,性能得到提升。但是,如果有重分区的算子(即有redistributing的数据传递模式),它还是会出现不同slot或不同taskmanager数据交互的,这样数据会经过IO和序列化。
而任务链(Operator Chains)是将将并行度相同且关系为one-to-one的前后两个subtask,融合形成一个task,是更细粒度的“融合”,它一方面可以减少task的数量,提高taskManager的资源利用率,另一方面,由于是one-to-one的数据传递模式,并且task只能存在于一个slot中,数据是不会有IO和序列化的。
参考文档
- https://mp.weixin.qq.com/s/bvhnuOqKf5RyhwICtt4X2w
- https://mp.weixin.qq.com/s/ggHmSc86mN3I7r6snjqxWQ
- https://mp.weixin.qq.com/s/q6aMPlm9KDpbTfFh1qSLEQ