在一个框架下去讨论
这里采用的单目标跟踪小综述_我爱计算机视觉-CSDN博客的说法,对于单目标跟踪(single object track, SOT)问题给出两种思路。
1.将SOT问题粗暴地当做一个匹配问题,即把第一帧目标当做模板去匹配其他帧,网络不需要“理解”目标,在推理时拿着这个模板和输入各部分评价相似度即可。我们今天聊到的Siam系列就是这个思路,每次两个输入即模板和新图片,然后通过网络在新图片上找和模板最相似的区域。
2.另一种思路自然是通过第一帧“理解”目标,后续帧的推理中。网络的输入只有一个新图片,网络根据自己理解的模板,在新图片中预测目标。
前者的难点是如何匹配准确,后者的难点是如何让网络仅仅看一眼目标就能像目标检测那样“理解”目标,这就涉及到单样本学习问题,也是检测和跟踪的gap。
地位
一般的,我们将体系中包含两个或多个相同的网络统一称为Siamese网络,即暹罗网络。
SiamFC在ECCV2016上发表后,为之后的基于深度学习的目标跟踪任务开辟了新的道路,即Siam目标跟踪系列(基于Siamese网络的以匹配任务为核心的目标跟踪算法簇)。
优势
这里要注意虽然上一段这样说,但SiamFC并不是第一个将Siamese网络应用到目标跟踪任务中的,只是SiamFC展示了较为突出的性能和先进的算法思想(即证明将跟踪问题转化成这种相似性学习问题,并在推理时对这个问题进行在线的简单评估这种方法在benchmark上可以达到非常有竞争力的性能),人们将其提升至该地位。
SiamFC胜出的原因主要归纳为:
1.离线训练,跟踪过程中无微调,跟踪速度在GPU上达到80+FPS。
2.采用了大规模的ImageNet数据集进行训练,不仅使得网络性能更好,也避免了在跟踪数据集上训练造成的过拟合。
3.SiamFC是全卷积的,具有平移不变性,待搜索图像不需要与样本图像具有相同尺寸,可以为网络提供更大的搜索图像作为输入,使得定位过程能够一次进行,在密集网格上计算所有平移窗口的相似度。
虽然现在到了2021年,但是为了更好理解当前Siamese网络类跟踪方法,还是很有必要回顾下SiamFC。
论文快速阅读
1. 相似性(Similarity)学习
SiamFC方法的核心思想很简单,就是将跟踪过程规划为一个相似性学习问题。即学习一个函数 f(z, x) 来比较样本图像 z 和搜索图像 x 的相似性,如果两个图像相似度越高,则得分越高。为了找到在下一帧图像中目标的位置,可以通过测试所有目标可能出现的位置,将相似度最大的位置作为目标的预测位置。
1.1全卷积Siamese结构
在深度学习中处理相似度问题最典型的是采用Siamese架构,SiamFC的网络结构如下图:

这里 z 为模板图像,x 为搜索图像,φ 为转换(transforamtion)函数,目的是提取图像的特征,而 * 号代表互相关操作。上图可以写成函数形式:
![]()
这里b1表示bias,在score map的每个位置都加上b。
1.2 网络训练
作者采用的是判别方法(discriminative approach),即在正负样本对上训练网络,采用的是logistic loss
![]()
这里v为score map中每个点的真值,同时y∈{+1, -1}为相应点的标签,其中标签按下式生成:
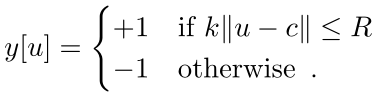
采用的训练样本对如下图所示:

在训练时使用的图像对是由一个模板图像和一个尺寸更大的搜索图像组成。这将会得到一个score map,这里定义score map的损失为所有点损失的均值。从上面训练样本对以及标签可以看到,搜索图像中仅有少部分正样本,而大部分为负样本,这就存在一个样本不均衡的问题。所以最终SiamFC中采用的损失函数为score map上每个点损失的加权平均,从而解决不均衡问题。(当然这里还存在easy样本和hard样本不均衡的问题,这点在近年来的论文中采用了对抗性学习技术来生成更多的hard样本来进行解决,包括SINT++,VITAL等)
1.3 采用的数据集
之前的很多方法,包括MD-Net,SINT,GOTURN都使用了属于基准数据集ALOV/OTB/VOT中的视频序列,这种方式已经被VOT所禁止,因为它可能会造成对基准数据集中场景和物体的过拟合。因此使用ImageNet数据集对用于跟踪的卷积网络进行训练也是该方法的一重大贡献。该方法使用的是ILSVRC2015数据集,包含了大约4500个视频,包含大于100万帧标注的视频帧。
2. 实验
2.1 细节
- 训练:直接使用随机梯度下降(SGD)最小化损失函数来求解嵌入函数参数;训练50个epoch,每个epoch有50,000个样本对;mini-batch设置为8;学习率从10^?2 衰减到 10^?8。
- 跟踪:样本图像特征φ(z)只在初始帧计算一次;用双三次插值将score map从17×17上采样到272×272。
2.2 评估

上图为OTB-13基准集上的测试结果,尽管SiamFC方法非常的简单,但已经可以看出其显露出的优势。跟踪速度:3尺度86fps,5尺度58fps。(其实验平台NVIDIA GeForce GTX Titan X and an Intel Core i7-4790K at 4.0GHz)
2.3 注意事项
我们最后讨论一点骨干网络(Backbone),可以看出SiamFC采用的骨干网络为AlexNet,该网络有个很大的特点是没有在网络中引入padding,这点很重要,因为这保证了网络的全卷积性,也即平移不变性,保证了计算的准确性。我们知道AlexNet是属于相对比较简单的网络,其它复杂的网络包括VGGNet,ResNet等却包含了padding,这也导致许多其它学者尝试使用更复杂的Backbone来试图提升跟踪性能都失败了,直到后来对相应的网络进行改进,保证平移不变性,才使得跟踪性能得到了进一步的提升,这方面的工作包括今年的SiamDW,SiamRPN++等。