Java中的集合框架(Collections framework)包含两个组成:Collection 和Map
| 一.Collection |
Collection是一个继承于Iterable的接口
Collection接口中主要定义了以下常见方法:
int size();//集合的长度
isEnmty();//是否为空
boolean contains(Object o);//否含有某个元素
boolean containsALl(Collection< ?> c);//是否含有某个集合
Iterator<E> iterator();//迭代集合中的元素
Object[] toArray();//转化为数组
boolean add(E e);//增加单个元素
boolean addAll(<Collection<? extends E> c);//增回子集合元素
boolean remove(Object o);//移除单个元素
boolean removeAll(<Collection<? extends E> c);//移除子集合
void clear();//全部清空
boolean equals(Object o);//是否相等
int hashCode();//hash码collection主要有以下子类:
List<E>,Set<E>,Queue<E>,Deque<E>1 . List< E >:有序列表管理接口
List是有序列表的管理接口,在Collection的基础上增加定义了以下几个主要方法
E get(int index);通过index 得到该元素
E set(int index,E element);//将处于index位的元素换成element
void add(int index,E element);//将元素放入容器中并放在index的位置
E remove(int index);//移除index位的元素
int indexOf(Object o);//得到某个元素第一次出现的index位 int
int lastIndexOf(Object o);//得到某个元素最后一次出现的index位 ListIterator
iterator[] listIterator();//获得迭代器
List<E> subList(int fromIndex,int toIndex);//通过启始index和结束index来获得子容器
Object][] toArray();//将list中所有元素按照index排列,转化为一个数组(注意arrayList在编译的时候会类型擦除(type erasure)所以都分转化为原始类型Object类
T[] toArray(T[] a);//将list转化为指定类型的数组List接口的几个主要的实现类:ArrayList、LinkedList、AttributeList、Stack、Vector
2 . Set< E > :没有重复元素(只能有一个null值)无序的数据集的管理接口,set遍历时序列是随机的
Set在Collection的基础上增加定义了以下几个主要方法
boolean add(E e);
boolean addAll(Collection<? extends E >c);
void clear();
boolean contains(Object O);
boolean isEmpty();
boolean remove(Object o);
boolean removeAll(Collection<?>c);
boolean retainAll(Collection<?>c);//保留c中有的元素,剩下的元素全部清除
int size();
Object[] toArray();
T[] toArray(T[] a);Set接口的几个主要的实现类:hashSet
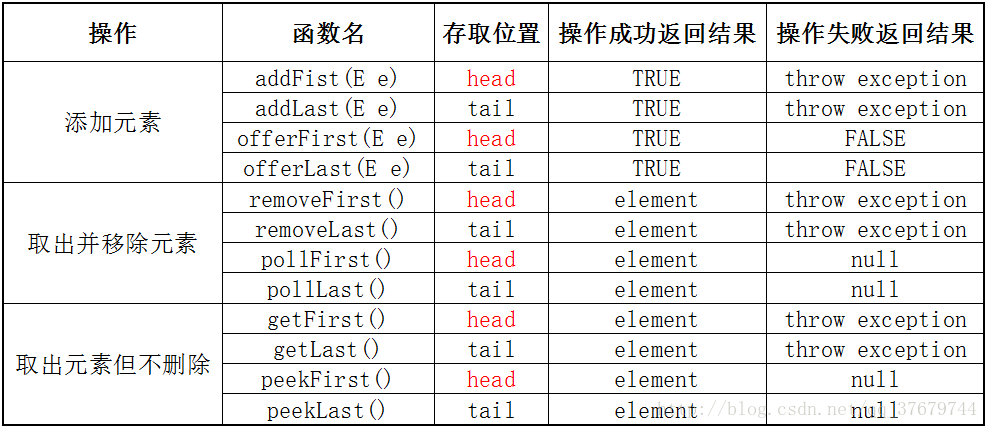
3 . Queue< E >:单向线性队列管理接口,先进先出,在尾部添加新元素,在头部取出已有元素
Queue在Collection的基础上增加定义了以下几个主要方法
注意:poll和peek方法出错进返回null。因此,向队列中插入null值是不合法的。
Queue接口的几个主要的实现类:LinkedList
4 . Deque< E >:双向线性队列(double ended queue)管理接口,两端都可以删除添加元素
Deque继承 了同时Collection和Queue,在此基础上增加了主要以下几种方法:
Deque接口的几个主要的实现类:LinkedList
collection及其子接口的具体实现类
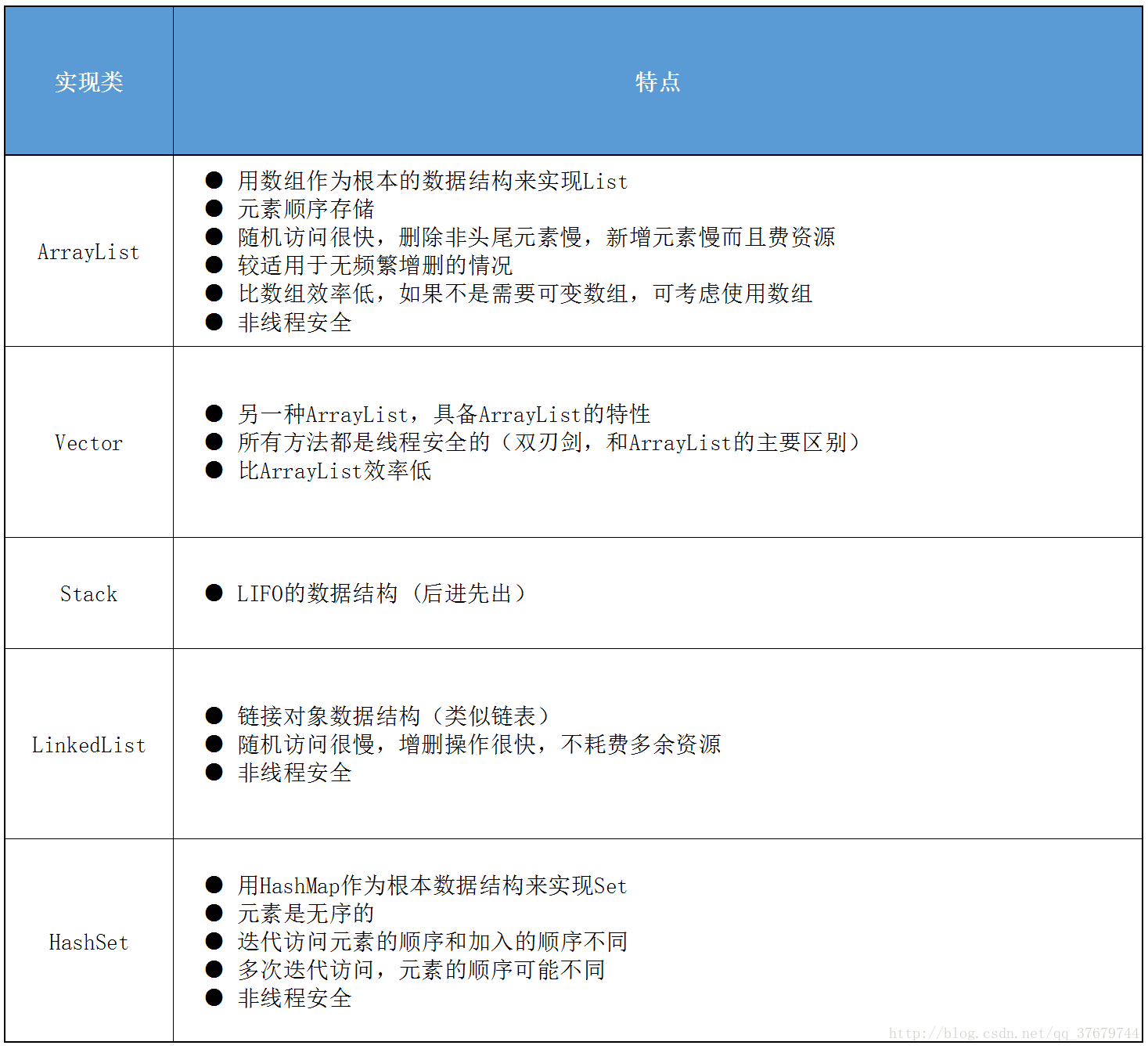
1.ArrayList
本质:是一个可改变长度的有序数组,能够容纳所有类型的元素(包括null),实现了List和Collection所有关于容器的操作,ArrayList中有一个Object[] elementData来存放数据,通过创建一个新的array 和将老的array的数据拷贝到新的array里来改变数组的长度.
特点: 能通过index对数据快速查找删除等操作,add方法操作时间复杂度为分期常量时间(amortized constant time),意思即如果添加n个元素则耗时O(n),其它操作耗时则是线性时间。每个ArrayList都有个容量,即存放元素能力的大小。这个容量是list中元素个数。当添加新的元素时,这个容量也会自动添加,这需要消耗一定时间。如果要添加大量数据到ArrayList,可以先调用ensureCapacity操作,从而减少每次添加新元素容量自动调整的时间。
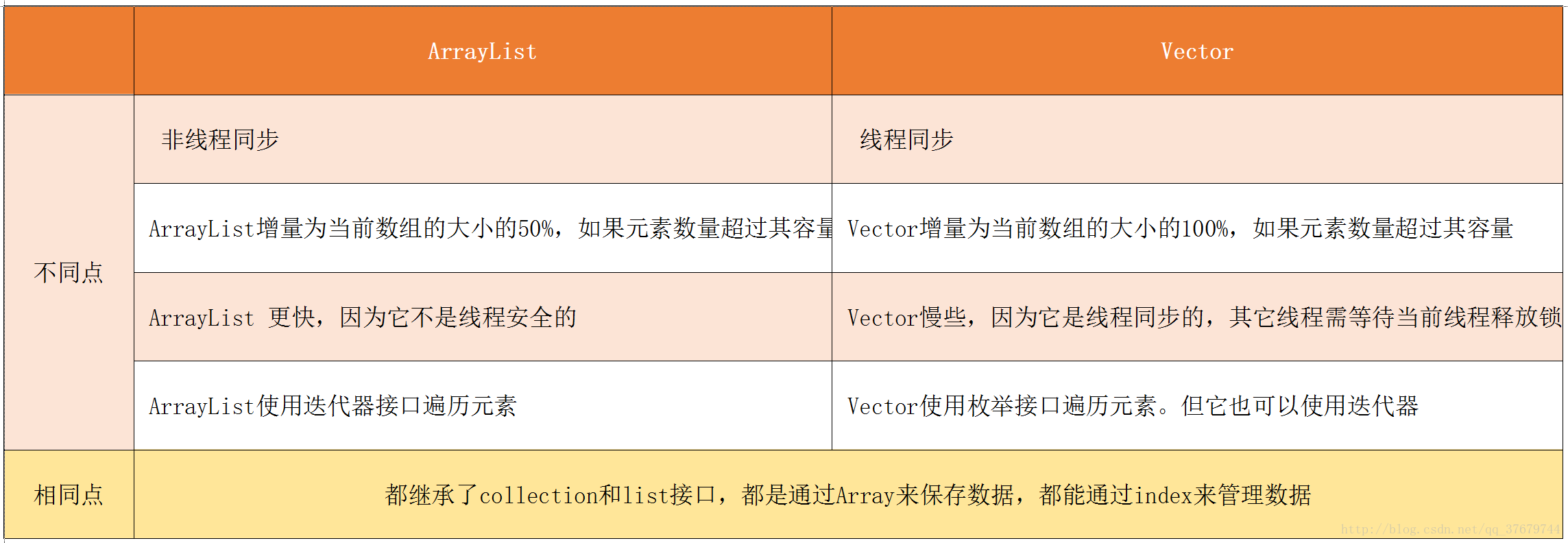
是否为线程同步:非线程同步的,当有多个线程同时访问一个arrayList并对其作修改时,需要对其加锁synchronized(obj)
最大容量: 理论上最大值 也是数组的最大容量
Integer.MAX_VALUE-8=2^31-8,可能受内存限制构造方法及参数
ArrayList();//构造一个容量为10的空的有序列表ArrayList(Collection<? extends E> c);//构造一个包含容器中所有元素的有序列表ArrayList(int initcapacity);//构造一个容量为initcapacity的空有序列表List和Collection接口定义的函数以外的常用的函数
ensureCapacity(int minCapacity);//增加容量到minCapacity大小removeRange(int fromIndex,int toIndex);//移除索引在【fromIndex,toIndex)之间的元素,包前不包后trimToSize();//将arraylist的容量改为和它的元素个数相等,优化占用内存2.Vector
本质:与ArrayList一样,底部容器是一个可改变长度的有序数组,能够容纳所有类型的元素(包括null),实现了List和Collection所有关于容器的操作,vector中有一个Object[] elementData的数组来存放数据,通过创建一个新的array 和将老的array的数据拷贝到新的array里来改变数组的长度.
特点: 能通过index对数据快速查找删除等操作,add方法操作时间复杂度为分期常量时间(amortized constant time),意思即如果添加n个元素则耗时O(n),其它操作耗时则是线性时间。每个vector都有个容量,即存放元素能力的大小。这个容量是vector中元素个数。当添加新的元素时,这个容量也会自动添加,这需要消耗一定时间。如果要添加大量数据到vector,可以先调用ensureCapacity操作,从而减少每次添加新元素容量自动调整的时间。
是否为线程同步: 线程同步的,vector默认就是线程安全的,所以在时间性能上没有ArrayList快
最大容量: 理论上最大值 也是数组的最大容量
Integer.MAX_VALUE-8=2^31-8,可能受内存限制构造方法及参数
Vector();//构造一个容量为10,容量增量(当容量不足时自动增加的量)为0的有序数列Vector(Collection<? extends E> c);//构造一个包含容器中所有元素的有序列表Vector(int initcapacity);//构造一个容量为initcapacity,容量增量为0的空有序列表Vector(int initCap,int capIncrement);//构造一个容量为initCap,增量为capIncrement的空有序列表List和Collection接口定义的函数以外的常用的函数
E elementAt(int index);//获得索引为index的元素void ensureCapacity(int minCapacity);//增加容量到minCapacity大小void setSize(int newSize);//若newSize大于vector.size,则增加(newSize-size)项null元素到vector中 ,若newSize小于vector.size,则保留index在0到newSize项元素,index>newSize的元素将被丢弃trimToSize();//将arraylist的容量改为和它的元素个数相等,优化占用内存Enumeration<E> elements();//返回vector中所有元素的Eumerationint indexOf(E e)//元素第一次出现的index值,则不存在则返回-1E firstElement();//返回index为0的元素E lastElement();//返回最后一位元素void setElementAt(E e,int index);//添加元素到指定的indexvoid removeElementAt(int index);//删除指定index的元素 ...3.Stack
本质:继承于Vector,与Vector一样,底部容器是一个可改变长度的有序数组保存数据,能够容纳所有类型的元素**
特点: 在vector的基础上拓展了五个操作以便序列能够以后进先出(LIFO)的形式管量数据
是否为线程同步: 线程同步的,vector默认就是线程安全的
最大容量: 理论上最大值 也是数组的最大容量
Integer.MAX_VALUE-8=2^31-8,可能受内存限制构造方法及参数
Stack();//构造一个空的stack堆栈,子类的构造器会调用基类的无参构造器,也是就Vector(),内部创建了一个容量为10,增量为0 的数组用于存放数据除了从vector继承的函数外Stack补充定义了以下常用的函数
E peek();//获得但不移除stack最顶部的元素(所谓的顶部就是index值最大,序列尾部),成功则返回该元素,否则抛出EmptyStackExceptionboolean empty();//判断Stack(堆栈)是否为空E pop();//从取出并移除栈顶的元素,若成功则返回该移除的元素,否则抛出EmptyStackExcaptionE push(E item);//将元素放在stack顶部(也就是添加新元素到序列尾部),返回元素本身int search(Object obj)//若o是堆栈中的成员则返回obj距离栈顶的位置(1表示obj位于栈顶,2表示obj位于栈顶第二位),若o不是stack中的元素则返回-14.LinkedList
本质:实现了list和Deque所有的操作,可以容纳所的数据类型(包括null),底部是通过Node(节点,每个节点都包含了三个属性,elemnt(数据) Nodeprevious(上一个节点),Nodenext(下一个节点)来将数据链接起来管理**
特点:数据通过node节点链接起来,使用index查找时,先判断index是不是小于>size-1,在通过二分法(若index小于size/2,则从first开始到index不断Node x = x.next来逐个寻找,若大于size的一半,则从last开始next到index,找到排在第index位的节点,然后再从节点中得到元素
是否为线程同步: 非线程同步的,多线程操作时需要加锁synchronized(object)
最大容量: 没有上限,但受内存限制
构造方法及参数
LinkedList();//构造一个空链表LinkedList(Collection<? extendsE> c);//构造一个包售集合中元素的链表LinkedList实现了List和Deque接口中定义的所有函数
5.HashSet
本质:是一个无序不可重复的集合,HashSet中有一个HashMap map对象来存放数据,通过map.put(element,obj);来存放元素,将元素作为key_value中的key保存,value为同一个object对象,对HashSet中元素的操作实际就是对map中Key的操作,能够容纳所有类型的元素(包括null),实现了List和Collection所有关于容器的操作
特点: 使用set.contains(Element e)方法时,必须先在Element.class类中重写 equal()和hash()方法
是否为线程同步:非线程同步的,当有多个线程同时访问一个hashSet并对其作修改时,需要对其加锁synchronized(obj)
最大容量:
Integer.MAX_VALUE =2^31-1构造方法及参数
HashSet();//构造空的HashSet,其中初始化的HashMap的capacity(16),load factor(0.75),HashMap的容量和加载因子与map的性能和占有空间有关系,具体参见HashMap HashSet (Collection<? extends E> c);//构造一个包含容器中所有元素的set HashSet(int capacity);//构造空的HashSet,初始化的HashMay的capacity(capacity),load factor(0.75) HashSet(int capacity,float loadFactor)//构造个空的HashSet,其中初始化的HashMay的capacity(capacity),load factor(loadFactor);Set和Collection接口定义的函数以外的常用的函数
HashSet实现了set和collection的所有方法,没有自己定义新的函数

| 二.Map |
Map是一个定义了键值对映射关系的接口,定义了Map.Entry< K,V>键值对内部接口
主要定义了以下方法
V get(Object obj); void clear(); boolean containsKey(Object obj); boolean containsValue(Object obj); Set<Map.Entry<K,V>> entrySet();、、获得键值对集 boolean isEmpty(); Set<K> keySet();//获得key集 V put(K key,V value); V remove(Object,o); int size(); Collection<V> values();//获得values集合 //Map.Entry<K,V>接口定义了以下几个方法 K getKey();//从键值对中获得key V getValue();//从键值对中获得value int HashCode();//获得键值对的hash码 v setValue(V value);//设置键值对中的value boolean equals(Object o);//键值对是否相同 ...Map< K,V>的主要实现类:HashMap、HashTable、LinkedHashMap、Properties、Provider、WeakHashMap等
1.HashMap:本质: HashMap是采用Hash散列进行存储(将键值对通过hashcode随机分为几组,每组中的元素通过Node(每个Node中除了键值对元素,还有Node< K,V>next属性)单项链接起来,这样做是为了同时提高储存和查找的效率,不允许有重复的键
特点:将数据通过Hash值分为多个单项链表储存(将一个大的链表,拆散成几个或者几十个小的链表。每个链表的表头,存放到一个数组里面), 这种方法中和了有序数组和链表的优点,同时提高删除,查找,增加的综合效率,由于存放查询的时候会用到Key的hashCode()方法和equals()方法,所以被作为Key的类型必须实现这两个方法
什么是HashCode: 将对象以统一自定义的形式转化为一个整数,这样每个数据对象都会对应一个HashCode值,通过Hash % array.length 可以将对象分组存放到不同的队列里。
这样,在检索的时候,就可以减少比较次数。比如一个有200个数据,我可以创建一个固定大小的数组,比如50个大小,然后,让数据(整数)对50进行取余运算,
然后,这些数据,自然就会被分成50个链表了,每个链表可以是无序的,反正链表要逐个比较进行查询,平均每组也就4个数据,那么,链表比较,平均也就比较4次就好了。是否为线程同步:非线程同步的,当有多个线程同时访问一个hashMap并对其作修改时,需要对其加锁synchronized(obj)
最大容量:
Integer.MAX_VALUE =2^31-8数组的最大容量,会受到虚拟机内存的限制构造方法及参数
HashMap()//构造一个空的容量为16,加载因子为0.75的HashMap HashMap(int initialCap);//构造一个空的容量为initialCap,加载因子为0.75的HashMap HashMap(int initCap,float loadFactor);构造一个空的HashMap并设置容量和加载因子 HashMap(Map<?extends K,?extendsV>m);//构造一个HashMap并包含了map中的数据( 容量(Capacity)决定散列数组的大小(即键表的个数),加载因子(load factor)决定每个键表的长度,当键值对的数量达到capacity*loadFactor时,虚拟机会自动扩充容量到原来的2倍,并rehashing重新分配数据,以免每个链表的节点数过多,加载因子越大,每个链表的节点数越多,则会影响查询的时间(链表是通过逐个比较的方法来实现查询,加载因子过小则会造成内存的浪费,java分析最好的load factor的值为0.75)
Set和Collection接口定义的函数以外的常用的函数
HashSet实现了Map< K,V>和Map.Endtry< K,V>的所有方法,没有自己定义新的函数
2.HashTable:
3.LinkedHashMap:
4.Properties:
5.Provider:
6.ArrayMap< K,V >:ArrayMap< K,V>是android推出的提高内存使用率的集合,底层实现方法是,将Key的hash值放入一个int[]数组中并按照从小到大的顺序排列,Value值放在另一个v[]数组中按照key的hash值从小到大排列,增删查找键值对时会先通过二分法查找Entry所在的位置,在储存千条以下的数据时,ArrayMap的查询时间也比HashMap快,数据在千条以上时,HashMap的操作速度更快(以内存换时间)
7.SparseArray< E>:是ArrayMap< k,v>的一种特例,使用int作为Key
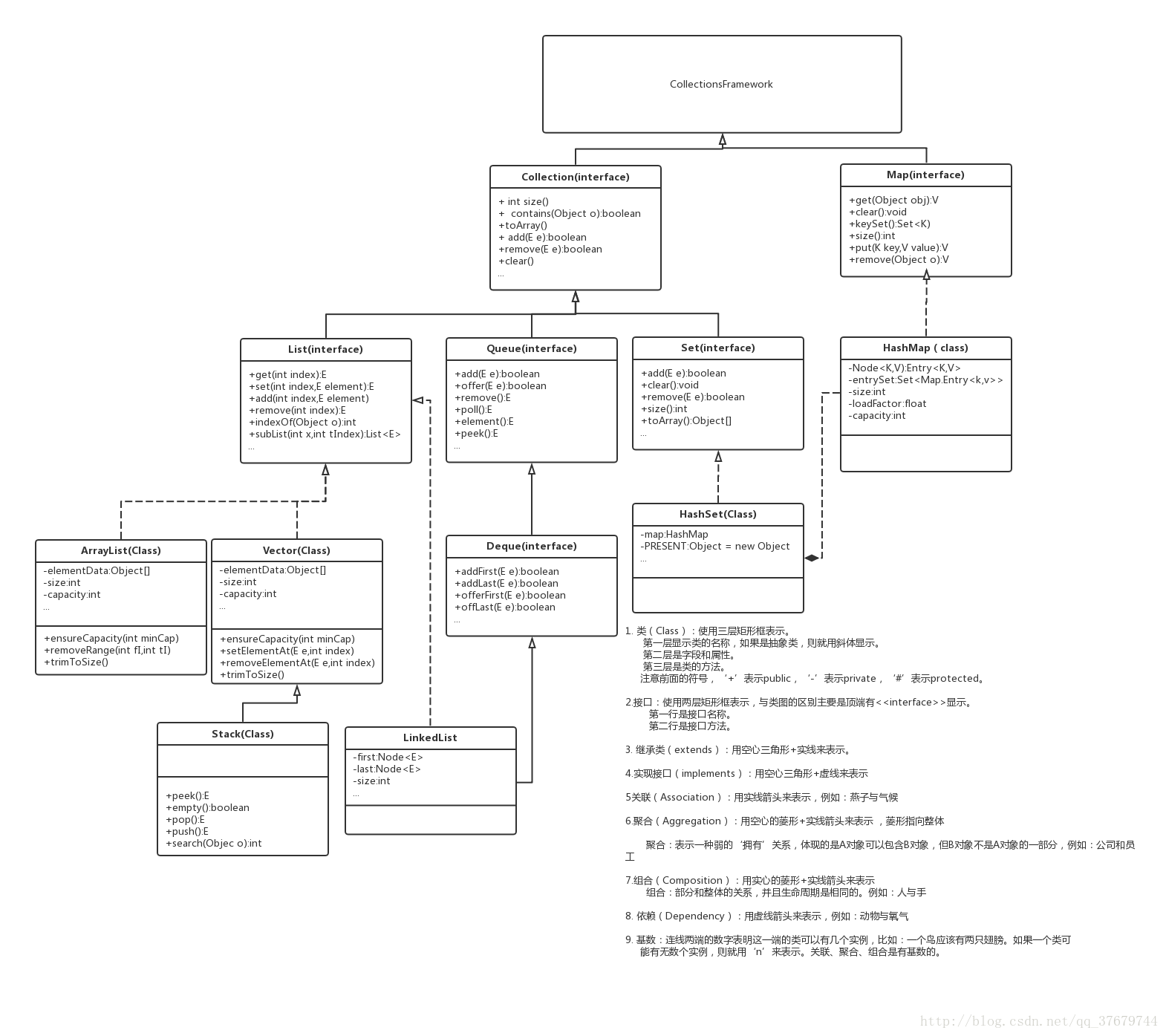
Collections Framework UML图:
HashMap:
采用Hash散列进行存储,主要就是为了提高检索速度。
众所周知,
有序数组存储数据,对数据的检索效率会很高,但是,插入和删除会有瓶颈产生。
链表存储数据,通常只能采用逐个比较的方法来检索数据(查找数据),但是,插入和删除的效率很高。
于是,将两者结合,取长补短,优势互补一下,就产生哈希散列这种存储方式。
具体是怎么样的呢?
我们可以理解成,在链表存储的基础上,对链表结构进行的一项改进。
我们将一个大的链表,拆散成几个或者几十个小的链表。
每个链表的表头,存放到一个数组里面。
这样,在从大链表拆分成小链表的时候就有讲究了。
我们按照什么规则来将一个大链表中的数据,分散存放到不同的链表中呢?
在计算机当中,肯定是要将规则数量化的,也就是说,这个规则,一定要是个数字,这样才比较好操作。
比如,按照存放时间,每5分钟一个时间段,将相同时间段存放的数据,放到同一个链表里面;
或者,将数据排序,每5个数据形成一个链表;
等等,等等,还有好多可以想象得到的方法。
但是,这些方法都会存在一些不足之处。
我们就在想了,如果存放的数据,都是整数就好了。
这样,我可以创建一个固定大小的数组,比如50个大小,然后,让数据(整数)对50进行取余运算,
然后,这些数据,自然就会被分成50个链表了,每个链表可以是无序的,反正链表要逐个比较进行查询。
如果,我一个有200个数据,分组后,平均每组也就4个数据,那么,链表比较,平均也就比较4次就好了。
但是,实际上,我们存放的数据,通常都不是整数。
所以,我们需要将数据对象映射成整数的一个算法。
HashCode方法,应运而生了。
每个数据对象,都会对应一个HashCode值,通过HashCode我们可以将对象分组存放到不同的队列里。
这样,在检索的时候,就可以减少比较次数。
在实际使用当中,HashCode方法、数组的大小 以及 数据对象的数量,这三者对检索的性能有着巨大的影响。
1.如果数组大小为1,那和链表存储没有什么区别了,
而且,还多了一步计算HashCode的时间,所以,数组不能太小,太小查询费时间。
2.如果我只存放1个数据对象,数组又非常大,那么,数组所占的内存空间,就比数据对象占的空间还大,
这样,少量数据对象,巨大的数组,虽然能够使检索速度,但是,浪费了很多内存空间。
3.如果所有对象的HashCode值都是相同的数,
那么,无论数组有多大,这些数据都会保存到同一个链表里面,
一个好的HashCode算法,可以使存放的数据,有较好的分散性,
在实际的实现当中,HashSet和HashMap都对数据对象产生的HashCode进行了二次散列处理,
使得数据对象具有更好的分散性。