K_means算法
-
- 1,简介
-
- (1)聚类
- (2)k-means算法思想(k-means clustering algorithm)
- 2,算法步骤
- 3,形象展示
- 4,代码实现
- 5,算法的Debug
-
- 关于k值
- 关于质心
- 优点
1,简介
k_means?刚接触的时候,感觉是很陌生的。不过不要怕,有我这个Z小白来解释,相信会对你有所裨益。
k-means算法也叫k均值聚类算法,是一种机器学习常用的聚类算法,当然在环境学,生物学,天文学…等各个领域都有他的身影。它能解决的问题我们可以用简单的用图像表示一下: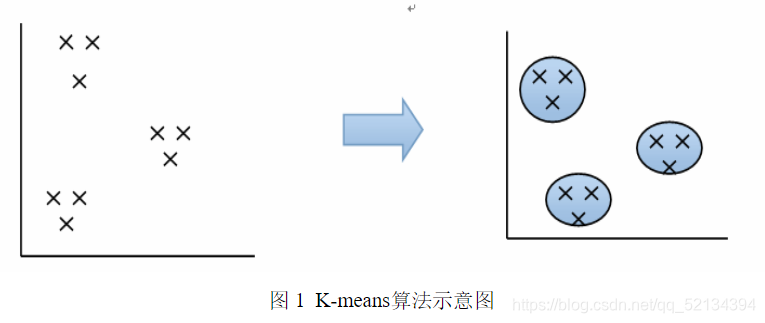
k-means算法就是要用计算机去解决上图所示的聚类问题。
(1)聚类
“物以类聚,人以群分”,将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。上面是百度解释,看上去比较费解,个人理解就是把一堆数据,分成你给定特征下的k个簇(堆),每个簇之间有极近的相似度,与其他簇之间的相似度极大。聚类与分类不同,分类是事先知道所有的类型,而聚类是现在要分出可以用于分类参考的数据库,一个簇就为一类可以这样理解吧。
(2)k-means算法思想(k-means clustering algorithm)
预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
2,算法步骤
依据上面提到的算法思想,我们可以简洁的把k-means算法归结如下:
1,选择要分成的类数,定下k个质心(聚类中心)
2,repeat:将**每个点指派到最近的质心**,形成k个簇重新计算每个簇的质心
3,until 簇的质心不发生变化或达到最大迭代次数
如何指派:
牵涉到距离的计算,什么欧式距离,余弦距离,曼哈顿距离,切比雪夫距离等等吧。把每个样品点到k个质心的距离都进行计算,然后进行比较,把该样品点分配给距离最近的簇。
重新计算每个簇的质心:
还记得k-means算法的另一个名字吗?k均值聚类算法,k均值就在更新质心的时候体现的淋漓尽致,更新质心就是把得到的一簇样品点,求其平均值作为新的质心。
3,形象展示
假设 K=2,即有两个簇,绿色为最初的样本数据集(图 a),红色标记和蓝色标记分别为两个质心(图 b)。通过计算样本到红色质心和蓝色质心的距离,实现对样本的分类,然后再不断地更新质心的位置,最终可以得到一个比较理想的聚类结果(图 f)。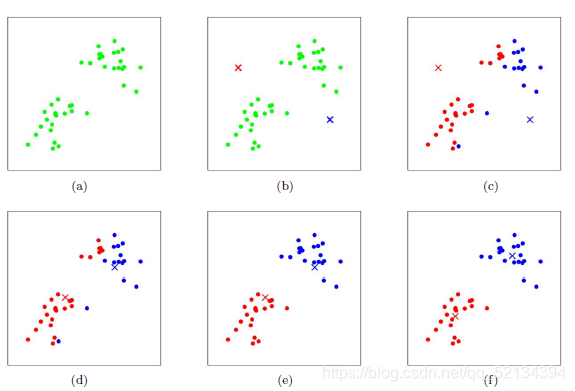
看过了好几个k-means的图像展示,发现还是这张最好。形象地展示了更新质心和簇的过程,也就是k-means算法的宏观展现。
4,代码实现
import matplotlib.pyplot as plt
from random import uniform
from math import sqrt#创建一个数据集。
#注意:本方法创建的数据集每次运行结果都不相同
m = 100 #数据个数
data = [[],[]] #[[存储 x 轴数据],[存储 y 轴数据]]
for i in range(m):if i < m/3: data[0].append(uniform(1,5))#随机设定data[1].append(uniform(1,5))elif i < 2*m/3:data[0].append(uniform(6,10))data[1].append(uniform(1,5))else:data[0].append(uniform(3,8))data[1].append(uniform(5,10))
#将创建的数据集画成散点图
plt.scatter(data[0],data[1])
plt.xlim(0,11)
plt.ylim(0,11)
plt.show()#定义欧几里得距离
def distEuclid(x1,y1,x2,y2):d = sqrt((x1-x2)**2+(y1-y2)**2)return dcent0 = [uniform(2,9),uniform(2,9)] #定义 K=3 个质心,随机赋值
cent1 = [uniform(2,9),uniform(2,9)] #[x,y]
cent2 = [uniform(2,9),uniform(2,9)]
mark = [] #标记列表
dist = [[],[],[]]#各质心到所有点的距离列表
#核心
for n in range(50):#计算各质心到所有点的距离for i in range(m):dist[0].append(distEuclid(cent0[0],cent0[1],data[0][i],data[1][i]))dist[1].append(distEuclid(cent1[0],cent1[1],data[0][i],data[1][i]))dist[2].append(distEuclid(cent2[0],cent2[1],data[0][i],data[1][i]))#对数据进行整理sum0_x = sum0_y = sum1_x = sum1_y = sum2_x = sum2_y = 0number0 = number1 = number2 = 0for i in range(m):if dist[0][i]<dist[1][i] and dist[0][i]<dist[2][i]:mark.append(0)sum0_x += data[0][i]sum0_y += data[1][i]number0 += 1elif dist[1][i]<dist[0][i] and dist[1][i]<dist[2][i]:mark.append(1)sum1_x += data[0][i]sum1_y += data[1][i]number1 += 1elif dist[2][i]<dist[0][i] and dist[2][i]<dist[1][i]:mark.append(2)sum2_x += data[0][i]sum2_y += data[1][i]number2 += 1 #更新质心cent0 = [sum0_x/number0,sum0_y/number0]cent1 = [sum1_x/number1,sum1_y/number1]cent2 = [sum2_x/number2,sum2_y/number2]#画图
for i in range(m):if mark[i] == 0:plt.scatter(data[0][i],data[1][i],color='red')if mark[i] == 1:plt.scatter(data[0][i],data[1][i],color='blue')if mark[i] == 2:plt.scatter(data[0][i],data[1][i],color='green')
plt.scatter(cent0[0],cent0[1],marker='*',color='red')
plt.scatter(cent1[0],cent1[1],marker='*',color='blue')
plt.scatter(cent2[0],cent2[1],marker='*',color='green')
plt.xlim(0,11)
plt.ylim(0,11)
plt.show()
本人运行结果: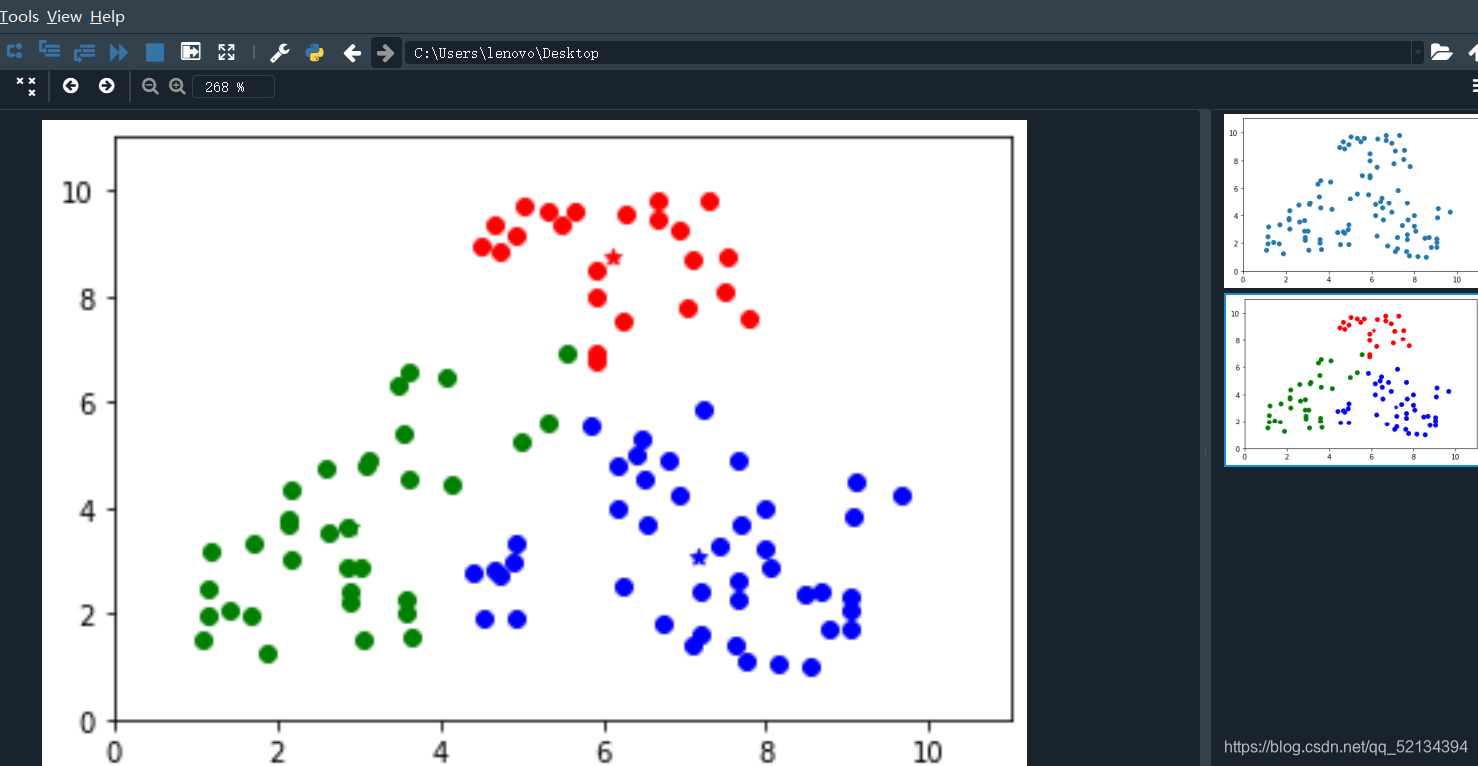
大家可以在看懂代码的前提下,多多更改参数,进行多次的运算,已达到理想效果。
5,算法的Debug
我坚信:一切基础的算法都是有其不足之处的。
关于k值
我们知道簇心的个数k是需要提前给定的,那多大合适呢?我们不得而知。初始的时候我们只能手动去调试,后来就有了很多比较有效的选取方法。
1.与层次聚类结合
2.稳定性方法
3.系统演化方法
4.使用canopy算法进行初始划分
这里先给出一个比较好的博文链接:方法详介,后续我会给出比较白话文的理解。
关于质心
初始质心的选取也会影响簇的分类效果。
优点
Kmenas算法试图找到使平凡误差准则函数最小的簇。当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想。