目录
算法简介
算法逻辑
案例
Spark程序实现例子(Java语言)
算法简介
FP-Growth是频繁模式挖掘的一种算法,由韩家炜等在2000年提出,算法通过建立一棵频繁项集树来实现频繁项集的搜索,同时能实现事务的压缩,相比Apriori能减少数据的扫描次数。
算法逻辑
1、扫描数据,统计项目(item)在数据集中出现的频数,例如苹果出现(被购买)了4次、牛奶出现(被购买)了5次等
2、再次扫描数据,构建频繁树(FP-Tree),并生成头表。将每条事物中的项目按照步骤1中的频数由高到底排列后,依次放到树中,并用头表记录每个项目在树中的位置
3、依据头表和支持度,在频繁树种搜索频繁项集
案例
数据:
| 交易ID(TID) | item(项) |
| 1 | 苹果,牛奶,香蕉 |
| 2 | 苹果,烤串 |
| 3 | 牛奶,香蕉,啤酒 |
| 4 | 牛奶,啤酒 |
| 5 | 香蕉,啤酒,尿布 |
| 6 | 香蕉 |
| 7 | 苹果,牛奶,香蕉,啤酒,尿布,烤串 |
| 8 | 香蕉 |
| 9 | 牛奶 |
| 10 | 啤酒 |
1、扫描数据,统计项目的频数,按照频数由大到小排序结果如下:
| item(项) | 频数 |
| 香蕉 | 6 |
| 牛奶 | 5 |
| 啤酒 | 5 |
| 苹果 | 3 |
| 烤串 | 2 |
| 尿布 | 2 |
2、再次扫描数据,构建频繁树(FP-Tree),并生成头表。构建FP-Tree时首先建立根节点root(或者叫NULL),根节点不保存数据
TID=1:苹果,牛奶,香蕉
根据频数对事务中的项目进行排序,得到:香蕉,牛奶,苹果
根据排序后的事务创建FP-Tree:根据频数倒序生成,香蕉紧跟在root节点后面,然后是牛奶在香蕉后面,苹果在牛奶后面,并在节点上记录项目的频数,生成头表指向各节点,如下图:

TID=2:苹果,烤串
根据频数对事务种项目进行排序,得到:苹果,烤串
插入到FP-Tree中,因root节点只有一个香蕉节点,没有苹果节点,因此root下面新增一个苹果节点;苹果节点之间增加指针,增加烤串指针

TID=3:牛奶,香蕉,啤酒
根据频数对事务种项目进行排序,得到:香蕉,牛奶,啤酒
插入到FP-Tree中,相同节点上的频数相加,如下图黑色文字部分

TID=4:牛奶,啤酒
根据频数对事务种项目进行排序,得到:牛奶,啤酒
插入到FP-Tree中,从root节点下面新增“牛奶”节点,建立啤酒之间的指针,如下图黑色文字部分

TID=5:香蕉,啤酒,尿布
根据频数对事务种项目进行排序,得到:香蕉,啤酒,尿布
插入到FP-Tree中,如下图黑色文字部分

TID=6:香蕉
插入到FP-Tree中,香蕉节点的频数由3增加到4,如下图黑色文字部分

TID=7:苹果,牛奶,香蕉,啤酒,尿布,烤串
根据频数对事务种项目进行排序,得到:香蕉,牛奶,啤酒,苹果,烤串,尿布
插入到FP-Tree中,如下图黑色文字部分

TID=8:香蕉
插入到FP-Tree中,如下图黑色文字部分

TID=9:牛奶
插入到FP-Tree中,如下图黑色文字部分

TID=10:啤酒
插入到FP-Tree中,如下图黑色文字部分。完整的FP-Tree如下图,从root开始生长的一棵频繁树,除root节点外,每个节点存储一个item(项目),以及item(项目)在事务数据中的频数,以及指向相同项目其他节点的指针;还有一张存储节点指针的头表。

3、挖掘频繁模式
从头表底部开始,由下到上挖掘频繁模式,最底部是尿布,在频繁树中,有两条路径:(香蕉6-牛奶3-啤酒2-苹果1-烤串1-尿布1)、(香蕉6-啤酒1-尿布1);
假如最小支持度设为2,即项目或项目组合大于等于2才算是频繁项,则以上两条路径被裁剪为(香蕉6-啤酒2-尿布1)、(香蕉6-啤酒1-尿布1)。苹果、烤串和尿布组合的数量只有1 ,不满足最小支持度,因此被裁剪掉;建立如下子树:
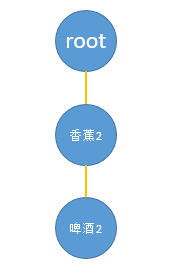
根据子树,得到频繁项集:以“尿布”结尾的频繁项集有:(尿布)(尿布,啤酒)(尿布,香蕉)(尿布,啤酒,香蕉)
然后根据指针的头表,继续向上挖掘以“烤串”、“苹果”,“啤酒”,“牛奶”,“香蕉”结尾的频繁项集
Spark程序实现例子(Java语言)
Spark中实现了FP-Growth算法,官方例子点这里,下面是代码
public class JavaFPGrowthExample {public static void main(String[] args) {//创建SparkSessionSparkSession spark = SparkSession.builder().appName("JavaFPGrowthExample").master("local").getOrCreate();// 创建List数据List<Row> data = Arrays.asList(RowFactory.create(Arrays.asList("1 2 5".split(" "))),RowFactory.create(Arrays.asList("1 2 3 5".split(" "))),RowFactory.create(Arrays.asList("1 2".split(" "))));StructType schema = new StructType(new StructField[]{ new StructField("items", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())});// 创建DataFrameDataset<Row> itemsDF = spark.createDataFrame(data, schema);// 显示原始数据System.out.println("原始数据在同一列里面,这是Spark的规则,数据框如下:");itemsDF.show(false);// 创建FPGrowth实例FPGrowthModel model = new FPGrowth().setItemsCol("items") // 设置输入列,交易数据需要进行拆分后,将项目(item)数据放在同一列中,这是Spark的要求.setMinSupport(0.5) // 设置最小支撑度.setMinConfidence(0.6) // 设置最小置信度.fit(itemsDF); // 拟合数据,返回一个FPGrowthModel// 展示频繁项System.out.println("频繁项集如下,第一列是项集组合,第二列是频数:");model.freqItemsets().show();// 生成关联规则System.out.println("关联规则如下,第一列是前项,第二列是后项,第三列是置信度");model.associationRules().show();//System.out.println("得到模型后,可以调用模型的transform方法,对数据集进行预测,得到规则。第一列是项集,第二列是推出的结果");model.transform(itemsDF).show();System.out.println("例如:1、2组合能够推出5");// $example off$spark.stop();}
}执行代码后得到以下结果
原始数据在同一列里面,这是Spark的规则,数据框如下:
+------------+
|items |
+------------+
|[1, 2, 5] |
|[1, 2, 3, 5]|
|[1, 2] |
+------------+2021-03-02 17:16:57 WARN [org.apache.spark.mllib.fpm.FPGrowth] - Input data is not cached.
频繁项集如下,第一列是项集组合,第二列是频数:
+---------+----+
| items|freq|
+---------+----+
| [5]| 2|
| [5, 1]| 2|
|[5, 1, 2]| 2|
| [5, 2]| 2|
| [1]| 3|
| [1, 2]| 3|
| [2]| 3|
+---------+----+关联规则如下,第一列是前项,第二列是后项,第三列是置信度
+----------+----------+------------------+
|antecedent|consequent| confidence|
+----------+----------+------------------+
| [1, 2]| [5]|0.6666666666666666|
| [5, 1]| [2]| 1.0|
| [2]| [5]|0.6666666666666666|
| [2]| [1]| 1.0|
| [5]| [1]| 1.0|
| [5]| [2]| 1.0|
| [1]| [5]|0.6666666666666666|
| [1]| [2]| 1.0|
| [5, 2]| [1]| 1.0|
+----------+----------+------------------+得到模型后,可以调用模型的transform方法,对数据集进行预测,得到规则。第一列是项集,第二列是推出的结果
+------------+----------+
| items|prediction|
+------------+----------+
| [1, 2, 5]| []|
|[1, 2, 3, 5]| []|
| [1, 2]| [5]|
+------------+----------+例如:1、2组合能够推出5