由于大数据挖掘中大部分的内容都是数据挖掘的大规模计算,那么就会存在如下的挑战:
1)如何进行分布式计算?
2)分布式/并行编程将会变得很难
针对以上的挑战,可以使用Map-Reduce来解决。
Map-Reduce是Google提出的计算模型或数据管理模型,是处理大数据的一种非常优雅的方式。
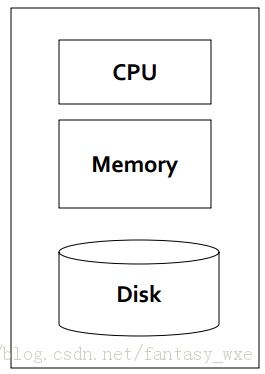
对于传统的机器学习,统计和”经典的“数据挖掘,由于处理的数据量比较小,使用单个结点的架构来对数据进行处理,单个结点架构如下图:
提出Map-Reduce模型的目的:以Google为例
有200多亿的网页,每个网页文件的大小估计为20KB,那么总的文件大小大概为:200多亿 x 20KB = 400多TB,如此庞大的数据,若一个计算机以30~35MB/sec从磁盘读取,那么大概需要4个月的时间来读取。大概需要1000个硬盘来存储这些网页。同时需要更大的代价来利用这些数据来做有用的事情。
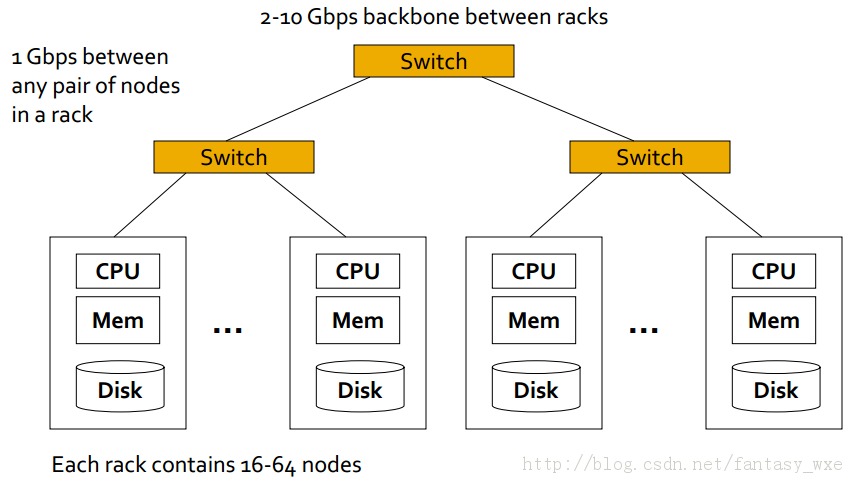
为此,出现了针对该问题的标准架构:
1)商业Linux节点的集群
2)商业网络(ethernet)来连接它们
架构如下图所示:
存储基础结构――文件系统,
Google使用的是GFS
Hadoop使用的是HDFS
针对上述的标准架构的编程模型是:Map-Reduce
针对存储结构,会存在如下的问题:如一个节点出现了问题,如何持久的存储数据呢?
可以使用分布式文件系统,提供全局的文件命名空间,像Google的GFS,Hadoop的HDFS。
以下先介绍一个热身的任务:
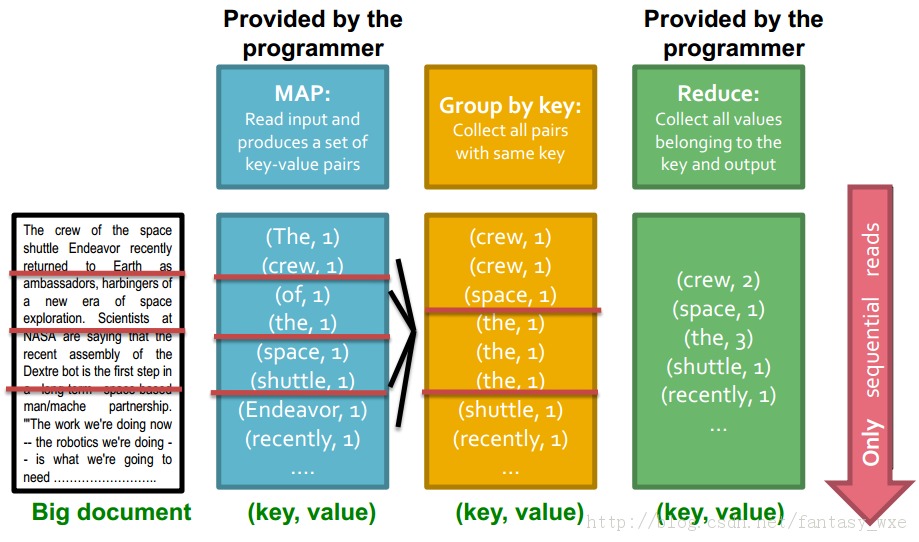
假设我们有一个大的文本文件,计算各个不同的文件出现的次数。在互联网开发中典型的应用是分析web服务器的logs,寻找流行的URLs。
任务:Word Count
对于该类问题存在如下问题:
1)文件太大,无法一次读入内存,但是所有的<word, count>对却可以放入内存中。
2)计算words出现次数。
MapReduce概述
顺序读取大量的数据。
分如下步骤进行,
Map:提取感兴趣的对象,通过关键值进行分组(sort and shuffle)
Reduce:聚合,总结,过滤或转换
得到最后的结果。
Map这一步如下示意图:
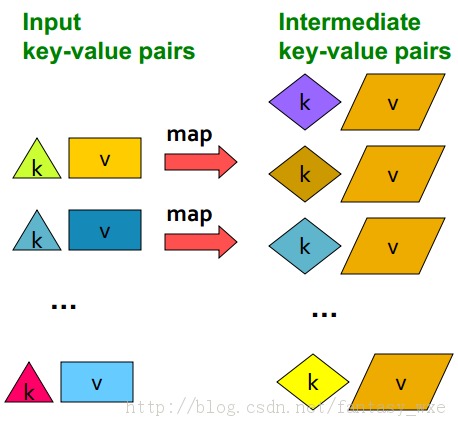
Reduce这一步如下示意图
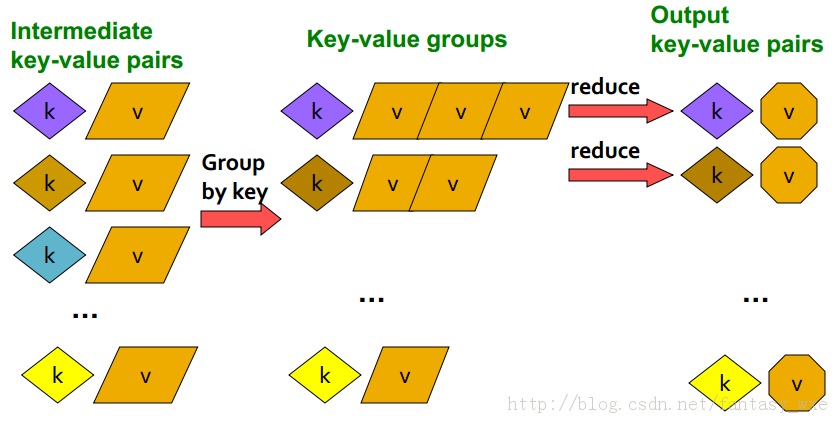
对于该实例的统计文本文件中的出现的单词次数的整个示意图如下: