- ��ʽ��

����sigmoid������g(z)=11+e?z
�䵼��Ϊg��(z)=(1?g(z))g(z)
���裺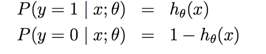
����
����m������������Ȼ������ʽ�ǣ�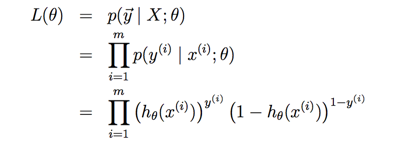
������ʽ��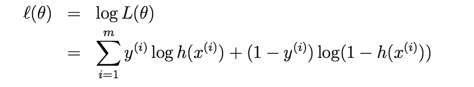
�����ݶ��������������ֵ
��

���¹���Ϊ��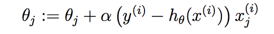
���Է��֣����������ʽ�Ϻ�LMS���¹�����һ���ģ�Ȼ�������ǵķֽ纯��h��(x) ȴ��ȫ����ͬ�ˣ����ع���h(x)�Ƿ����Ժ������������ⲿ��������GLM���ֽ��͡�
ע�⣺��h(x)����sigmoid����������ֵ������
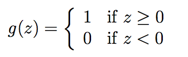
����㷨��Ϊ��֪ѧϰ�㷨����Ȼ�õ���������Ȼ���ƣ��������ع���ȫ����һ���㷨�ˡ� - ��һ�������Ȼ�����ķ����Cţ�ٱƽ���
- ԭ��������������õ�һ�������Ĺ����
f(��)=0 ,����ͨ��һ�·������ϸ����� ���õ���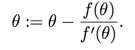
��ֱ�۽�������ͼ��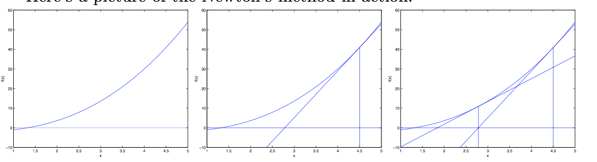
����һ����ʼ����0 ,���f(��0) ���䵼��ͬ��˵��������ڳ�ʼ����ߣ������ڳ�ʼ���ұߣ�����ʼ����¹��õ�����ߵĹ��������������裬�õ������߹�����ϱƽ�������Ҫ��ĺ�������㡣 - Ӧ�ã� �����ع��У�����Ҫ����Ȼ���������(��С)ֵ������Ȼ��������Ϊ0�� ��˿�������ţ�ٱƽ�����
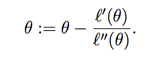
����lr�㷨���� ��һ����������ʽ��дΪ��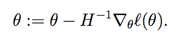
����HΪHessian����: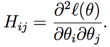
ţ�ٷ�������(������)�ݶ��½�������������
- ԭ��������������õ�һ�������Ĺ����
��ϸ�������
����ѧϰ�㷨����1_2:��������ع�(Classification and Logistic regression)
�ȶȣ�554 ����ʱ�䣺2016-05-05 06:02:42.0
��ؽ������
- ̨�����������ѧϰ��ʯ��ѧϰ�ʼǣ�����ģ��2��Logistics regression��
- ����ѧϰ�㷨����1_2:��������ع�(Classification and Logistic regression)
- [����ѧϰ] Coursera ML���� - ���ع飨Logistic Regression��
- MachineLearning��Logistic Regression(2)
- Logistic Regression ����������
- MachineLearning��Logistic Regression��1��
- ���ع�֮����ƻ��߽� logistic regression - decision boundary
- Prediction(��)Logistic Regression - Local Cluster Set Up
- Andrew Ng Machine Learning - Week ����Logistic Regression & Regularization
- ����ѧϰ������5�������ع�Logistic Regression��Softmax Regression
- ����ѧϰʵսByMatlab��5��Logistic Regression
- Stanford����ѧϰ�̳̱ʼ�1-Linear Regression��Logistic Regression
- Logistic Regression�е������Բ���
- ��ϰ����ѧϰ�㷨��Logistic �ع�
- logistic regression using Theano ڹ�Ͱ�
- Logistic and Softmax Regression (���ع��Softmax�ع�)
- ��weka����Logistic Regression
- MapReduce-Logistic Regression (���ع�)
- mahoutԴ�����֮logistic regression������-RunLogistic
- mahoutԴ�����֮logistic regression��һ��-ʵս
- Logistic Regression-���ع� ������ת��
- �ϰ�����(Logistic)ģ��
- Matlab�������Իع�����ع�: Linear Regression & Logistic Regression
- �ڶ���.Regression -- 03.Evaluating Regression Models����
- �ڶ���.Regression -- 02.Multiple Linear Regression����
- �ڶ���.Regression -- 01.Introduction to Regression����
- ��һ��.Classification -- 08.ROC Curve Algorithm����
- ��һ��.Classification -- 06.Evaluation Methods for Classifiers����
- ��һ��.Classification -- 05.Maximum Likelihood Perspective����
- ��һ��.Classification -- 04.Logistic Regression����