BatchNorm的基本思想:让每个隐层节点的激活输入分布固定下来,这样就避免了“Internal Covariate Shift”问题了。
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度【1】。
这里分五部分简单解释一下Batch Normalization (BN)【2】。
1. What is BN?
顾名思义,batch normalization嘛,就是“批规范化”咯。BN本质上解决的是反向传播过程中的梯度问题。Google在ICML文中描述的非常清晰,即在每次SGD(随机梯度下降)时,通过mini-batch来对相应的activation做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1。这种方法把数据分为若干组,按组来更新参数,一组中的数据共同决定了本次梯度的方向,下降时减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也下降了很多。 而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入(即当),从而保证整个network的capacity。(有关capacity的解释:实际上BN可以看作是在原模型上加入的“新操作”,这个新操作很大可能会改变某层原来的输入。当然也可能不改变,不改变的时候就是“还原原来输入”。如此一来,既可以改变同时也可以保持原输入,那么模型的容纳能力(capacity)就提升了。)
数据经过归一化和标准化后可以加快梯度下降的求解速度,这就是Batch Normalization等技术非常流行的原因,它使得可以使用更大的学习率更稳定地进行梯度传播,甚至增加网络的泛化能力。
通常BN网络层用在卷积层后,用于重新调整数据分布。假设神经网络某层一个batch的输入为X=[x1,x2,...,xn],其中xi代表一个样本,n为batch size。
首先,我们需要求得mini-batch里元素的均值:

接下来,求取mini-batch的方差:

这样我们就可以对每个元素进行归一化。

最后进行尺度缩放和偏移操作,这样可以变换回原始的分布,实现恒等变换,这样的目的是为了补偿网络的非线性表达能力,因为经过标准化之后,偏移量丢失。具体的表达如下,yi就是网络的最终输出。
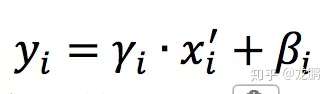
可以总结成下图;

假如gamma等于方差,beta等于均值,就实现了恒等变换。
从某种意义上来说,gamma和beta代表的其实是输入数据分布的方差和偏移。对于没有BN的网络,这两个值与前一层网络带来的非线性性质有关,而经过变换后,就跟前面一层无关,变成了当前层的一个学习参数,这更加有利于优化并且不会降低网络的能力。
对于CNN,BN的操作是在各个特征维度之间单独进行,也就是说各个通道是分别进行Batch Normalization操作的。如果输出的blob大小为(N,C,H,W),那么在每一层normalization就是基于N*H*W个数值进行求平均以及方差的操作,记住这里我们后面会进行比较。
关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:
- 1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);
- 2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.
2. How to Batch Normalize?
怎样学BN的参数在此就不赘述了,就是经典的chain rule:

3. Where to use BN?
BN可以应用于网络中任意的activation set。文中还特别指出在CNN中,BN应作用在非线性映射前,即对做规范化。另外对CNN的“权值共享”策略,BN还有其对应的做法(详见文中3.2节)。
4. Why BN?
- BN带来的好处。
- (1) 减轻了对参数初始化的依赖,这是利于调参的朋友们的。
- (2) 训练更快,可以使用更高的学习率。
- (3) BN一定程度上增加了泛化能力,dropout等技术可以去掉。
- BN的缺陷
- 从上面可以看出,batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降,在训练过程中计算的均值和方差不准确,而在测试的时候使用的就是训练过程中保持下来的均值和方差。
- 这一个特性,导致batch normalization不适合以下的几种场景。
- (1)batch非常小,比如训练资源有限无法应用较大的batch,也比如在线学习等使用单例进行模型参数更新的场景。
- (2)rnn,因为它是一个动态的网络结构,同一个batch中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。在rnn中,对bn进行改进也非常的困难。不过,困难并不意味着没人做,事实上现在仍然可以使用的,不过这超出了咱们初识境的学习范围。
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有,
,但是
. 大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
那么好,为什么前面我说Google将其复杂化了。其实如果严格按照解决covariate shift的路子来做的话,大概就是上“importance weight”(ref)之类的机器学习方法。可是这里Google仅仅说“通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果covariate shift可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS只是这个问题的“包装纸”嘛,仅仅是一种high-level demonstration。
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。
5. When to use BN?
OK,说完BN的优势,自然可以知道什么时候用BN比较好。例如,在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
参考:
【1】【深度学习】深入理解Batch Normalization批标准化
【2】深度学习中 Batch Normalization为什么效果好?:https://www.zhihu.com/question/38102762