目录
触发WAF的情况
逻辑思维层面绕过
被代理的浏览器一定要导入所用工具的证书
方法一:旁路绕过
方法二:针对云waf防护
方法三:白名单
①IP 白名单
②静态资源
(3)动动小脑瓜找绕过方法开始尝试
③目录伪装绕过(url 白名单)
④爬虫白名单(自我认为用处相比较大)
工具绕过
自动化绕WAF的实用渗透工具——WAFNinja
burpsuite
sqlmap
使用sqlmap自带的脚本进行绕过
检测是否有waf
规则:waf拦截(以安全狗为例)
使用自带绕过脚本进行绕过测试(现实中一般没什么用)
可以使用编写的tamper脚本(现实中一般需要自己编写)
Fuzz/爆破
fuzz字典
Fuzz-DB/Attack
Other Payloads 小心使用

(没有不透风的墙,办法总比困难多)
只要是基于规则的绕过,在工作的时候就有着天然的缺陷型,限制了WAF,防火墙等基于这种模式的防护作用的发挥,只要渗透测试者认真一点,发挥自己的脑洞,总能找到各种各样的绕过姿势。
网络安全:WAF绕过基础分析和原理、注入绕过WAF方法分析

触发WAF的情况
最常见的:
①扫描/访问的速度太快了,过快的进行扫描,不仅获得的信息是假的,还会被waf拦截。
②waf都有指纹记录识别,,特别是awvs等一些热门工具的工具指纹。
③漏洞payload的关键字也在waf的拦截字典里。
(道高一尺魔高一丈,比来比去,越学越多)

逻辑思维层面绕过
被代理的浏览器一定要导入所用工具的证书
burpsuite代理出现安全警告:“有软件正在阻止 Firefox 安全地连接至此网站” ,多半PortSwigger CA问题_黑色地带(崛起)的博客-CSDN博客
方法一:旁路绕过
WAF设置的时候由于疏漏,针对http(80端口)和https协议(443端口)没有全部进行防护,因此,在URL中把http改为https进行相互改
方法二:针对云waf防护
查找到真实ip,绕过CDN防护(基本操作)
Get Site Ip
IP/IPv6查询,服务器地址查询 - 站长工具
ip地址查询 ip查询 查ip 公网ip地址归属地查询 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
网站测速工具_超级ping _多地点ping检测 - 爱站网
小国家服务器访问网站
结合公司注册地进行手工判断

(有的时候工具也不一定可靠,要多试几个,然后自己判断一下)
方法三:白名单
云WAF在配置中会选择“信任”部分数据包,这部分数据包不会进行匹配检验,在WAF里有一个白名单列表,符合白名单要求的,WAF就不会进行检测。如果把我们访问的数据包伪装成白名单上的数据包,就可以绕过WAF的检验。
①IP 白名单
有些网站不会对自己(即物理机上的操作)进行检验,因此,可以在数据包中设置X-FARWARDED-FOR头,或者是X-Originating-IP,设置为127.0.0.1,就能绕过WAF。
从网络层获取的 ip,这种很难伪造,需要满足的条件比较多,较难实现,即使对数据包进行了修改,也是不会接受的但。如果是获取客户端的 IP,就存在伪造 IP 绕过的情况。
修改 http 的 header
X-Forwarded-For
X-remote-IP
X-originating-IP
x-remote-addr
X-Real-ip
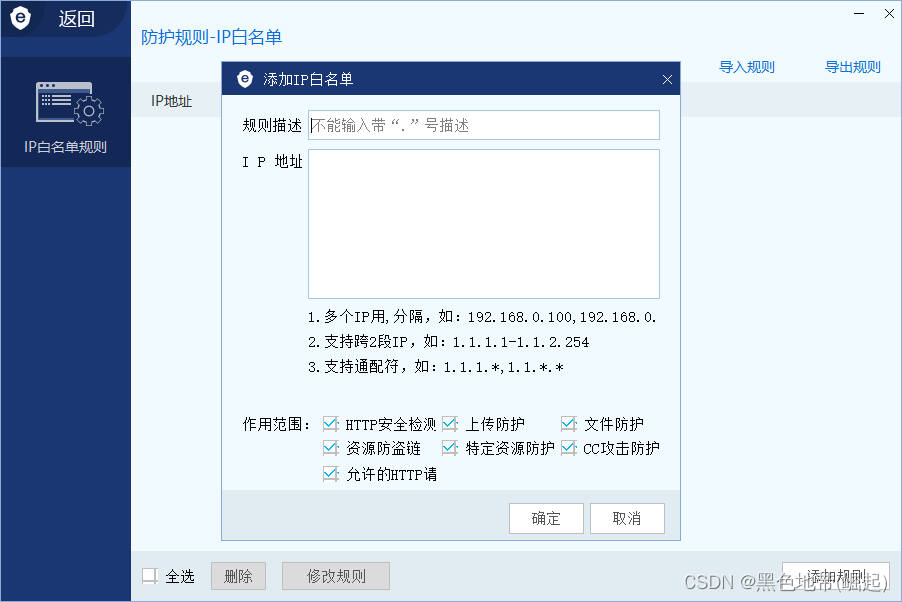
迷之事件,显示一个ok
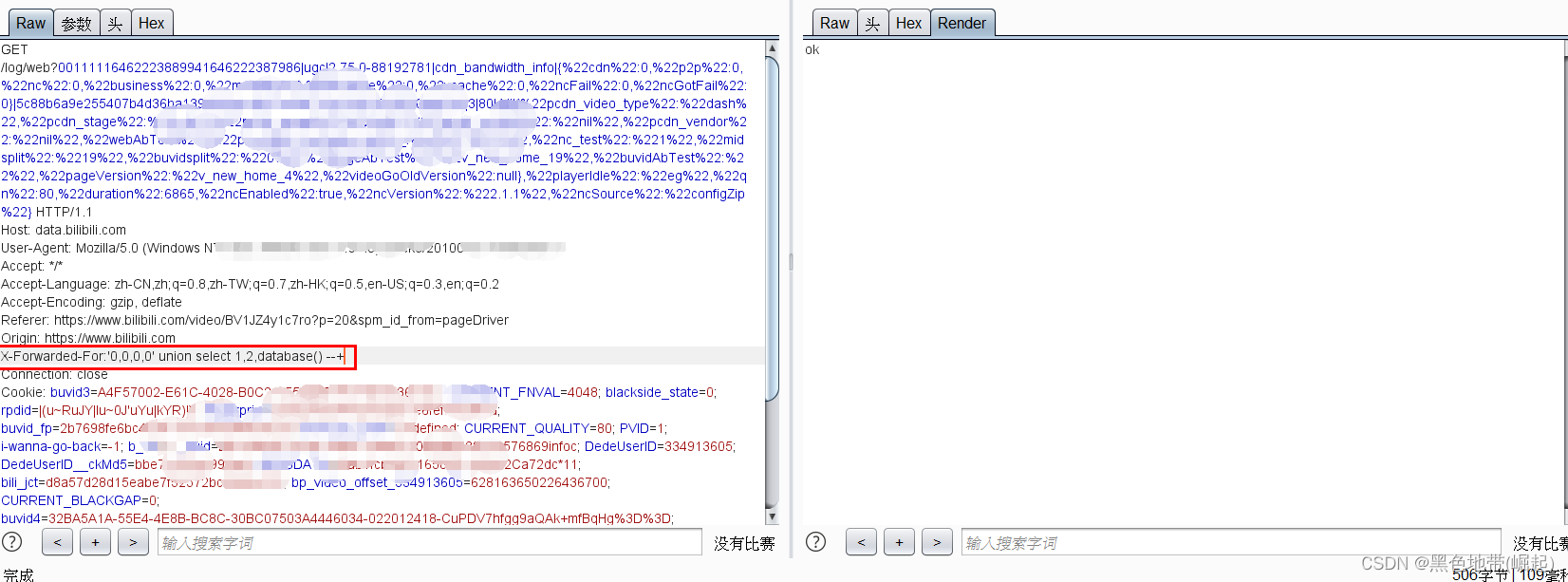
②静态资源
特定的静态资源后缀请求,常见的静态文件(.js .jpg .swf .css .txt等等),类似白名单机制,waf 为了检测效率,不去检测这样一些静态文件名后缀的请求。
URL/sql.php/1.js?id=1 and 1=1
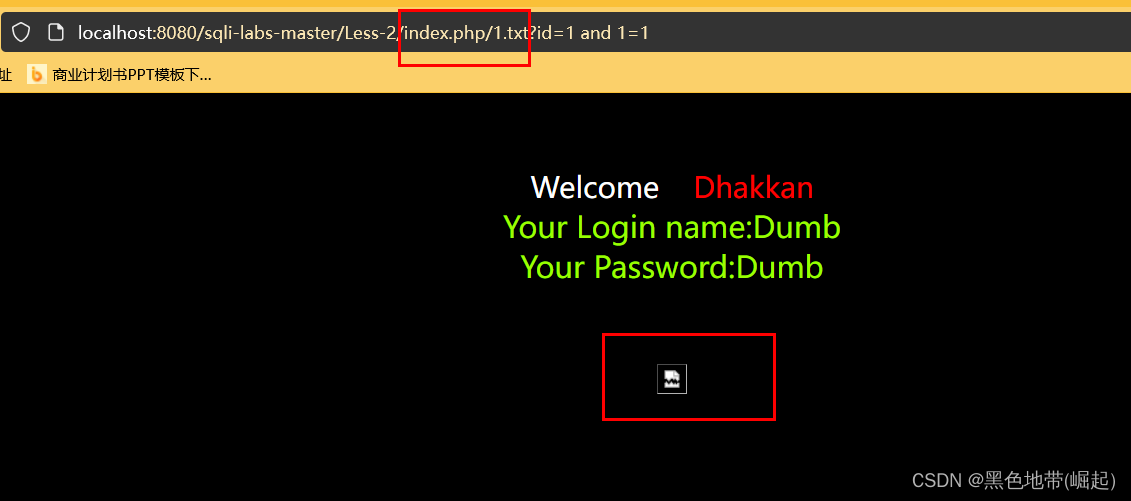
URL/index.php/1.txt?id=1 and 1=1
(Aspx/php 只识别到前面的 .aspx/.php 后面不识别)
(自我认为与工具爆破式测试相比,手工操作的逆向思维必不可少,再结合工具跑数据)
要实现的预期的结果(要有个方向)-------->对预期结果有影响的waf安全防护规则(知己知彼),并进行分析,-------->动动小脑瓜找绕过方法开始尝试
(1)要实现的预期的结果:
通过访问静态资源绕过waf,并能执行相关数据库语句
(2)了解相关waf安全防护规则
查询安全狗关于数据库操作相关检测规则
最多的就是检测URL、cookie、post的内容
很显然会对注入语句进行正则匹配,如果匹配到会进行拦截------>结合工具跑出识别不出来的情况

但是其默认的检测HTTP头是没开的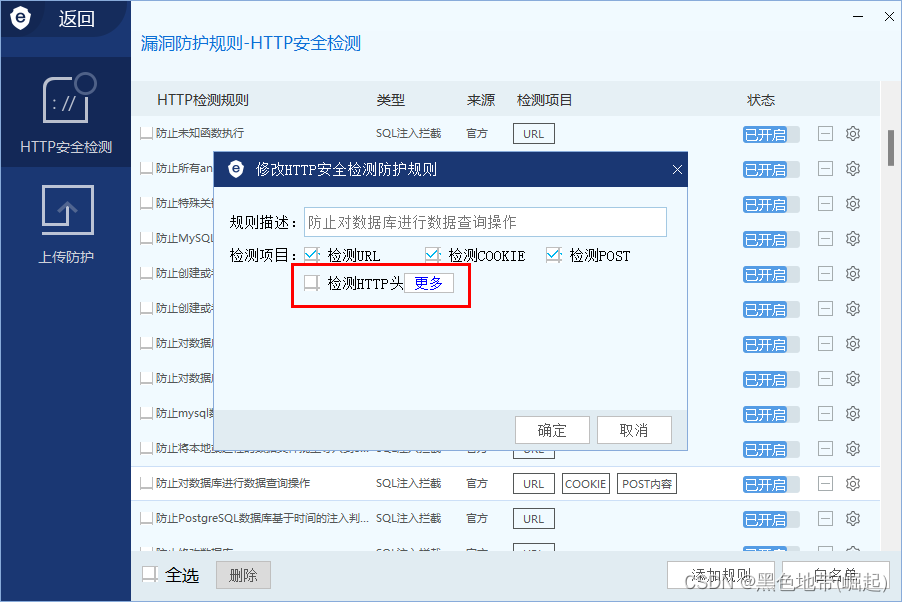
不绕过规则的结果------>被拦截

(3)动动小脑瓜找绕过方法开始尝试
①对post内容进行检测,说明可以尝试进行post内容进行提交
虽然没有被拦截,但是网站无法接收到post提交
GET、POST的区别、抓包GET改POST、http请求头参数、状态码_黑色地带(崛起)的博客-CSDN博客
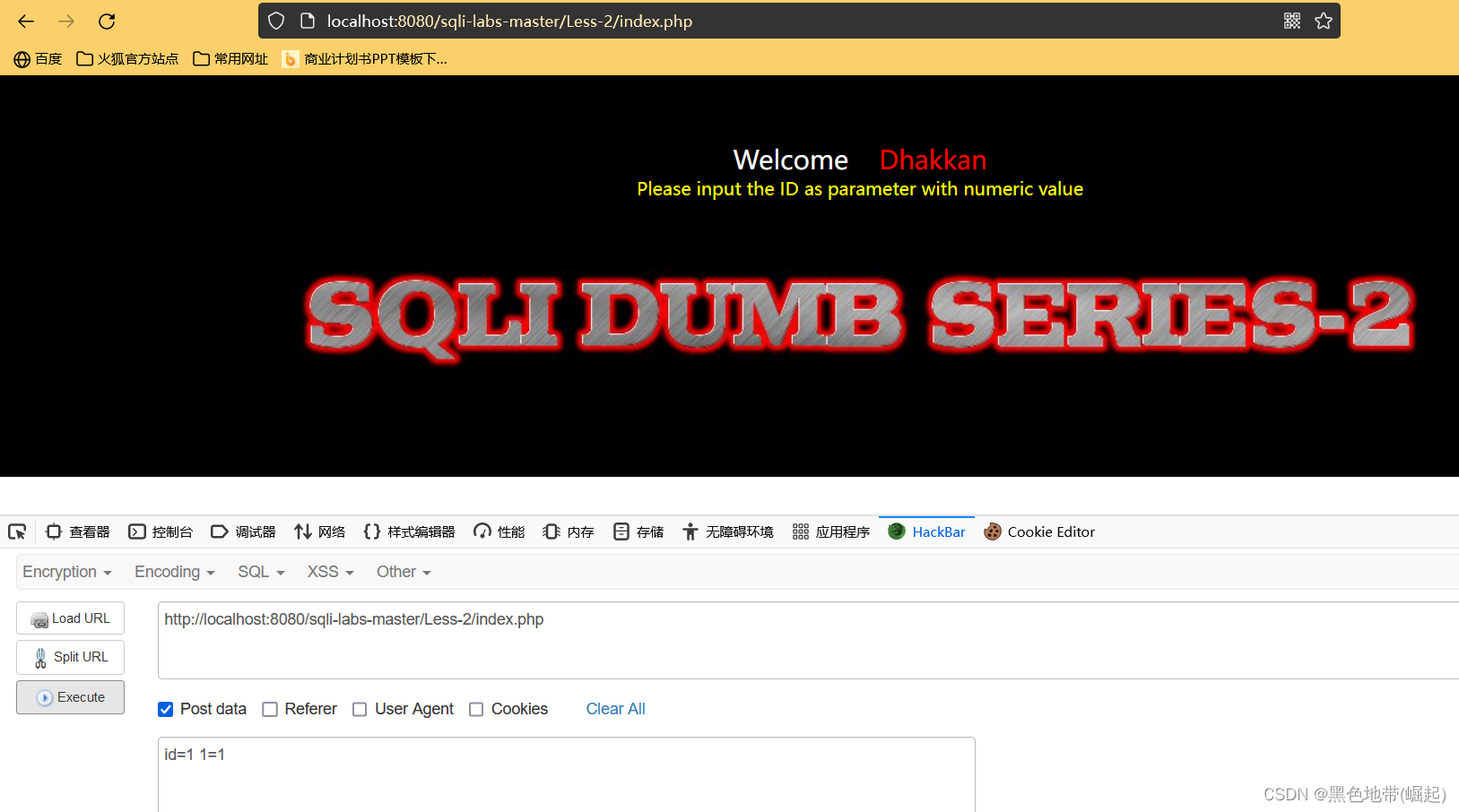
POST不接收,那么只能考虑回到GET,或者改源码为request
(这里不存在表单提交啥的,所有可能就不接收POST提交)
(人间真实,状况百出)
回到GET,那么就要考虑使用各种注释符,替换等等方法绕过(现在就可以用工具代替手工了)
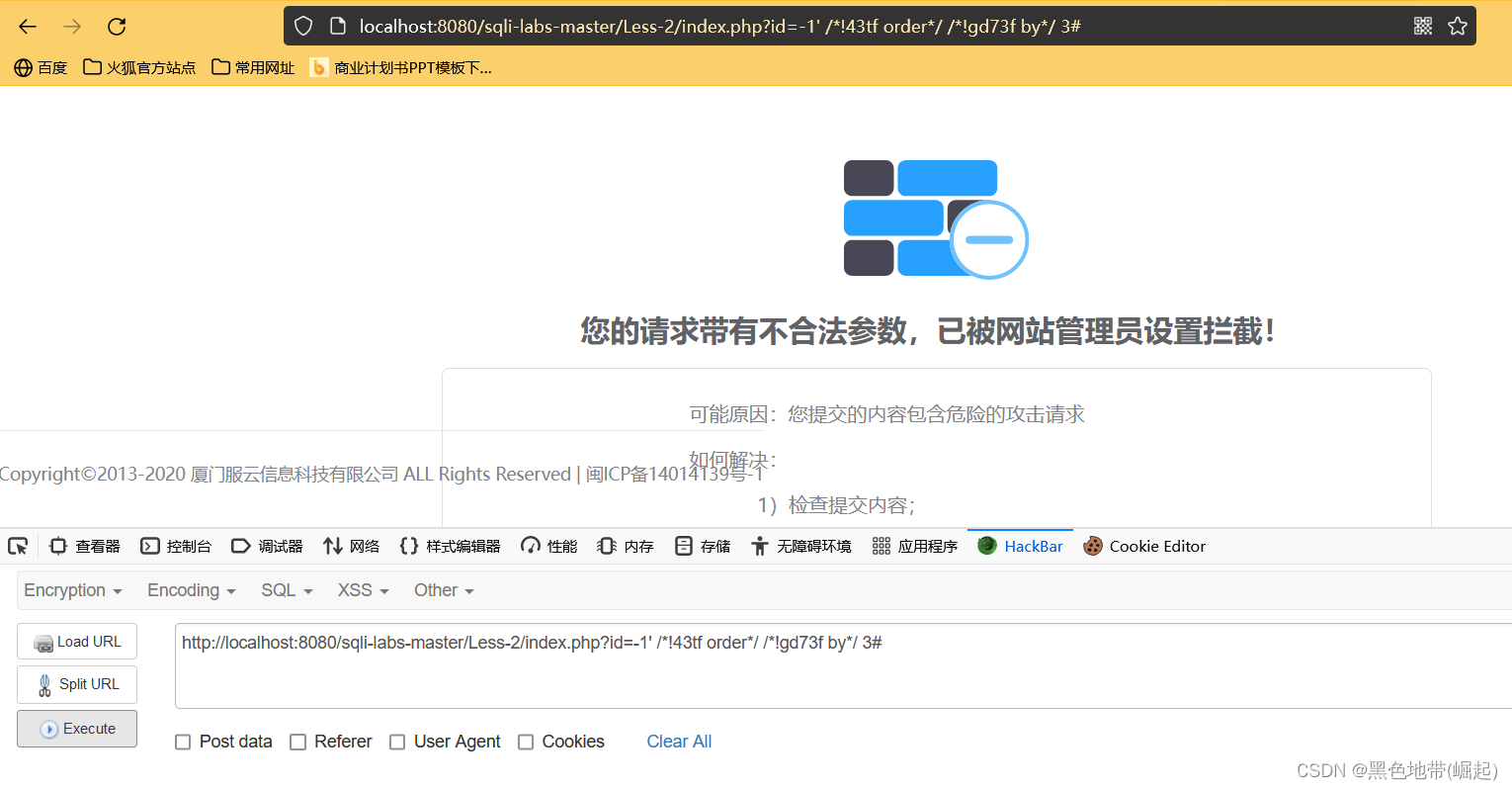
(爆破这方面还是交给工具和脚本解决吧)
③目录伪装绕过(url 白名单)
针对特定目录设置的白名单列表,如 admin/manager/system 等管理后台
检测数据包中是否含有指定的关键字符串判定,尝试构造含有这些指定目录字符串特性的数据包。
只要url中存在白名单的字符串,就作为白名单不进行检测。
常见的 url 构造姿势:
URL/index.php/admin?id=1
(呕吼,没拦截)
URL/index.php?a=/manage/&b=../etc/passwd
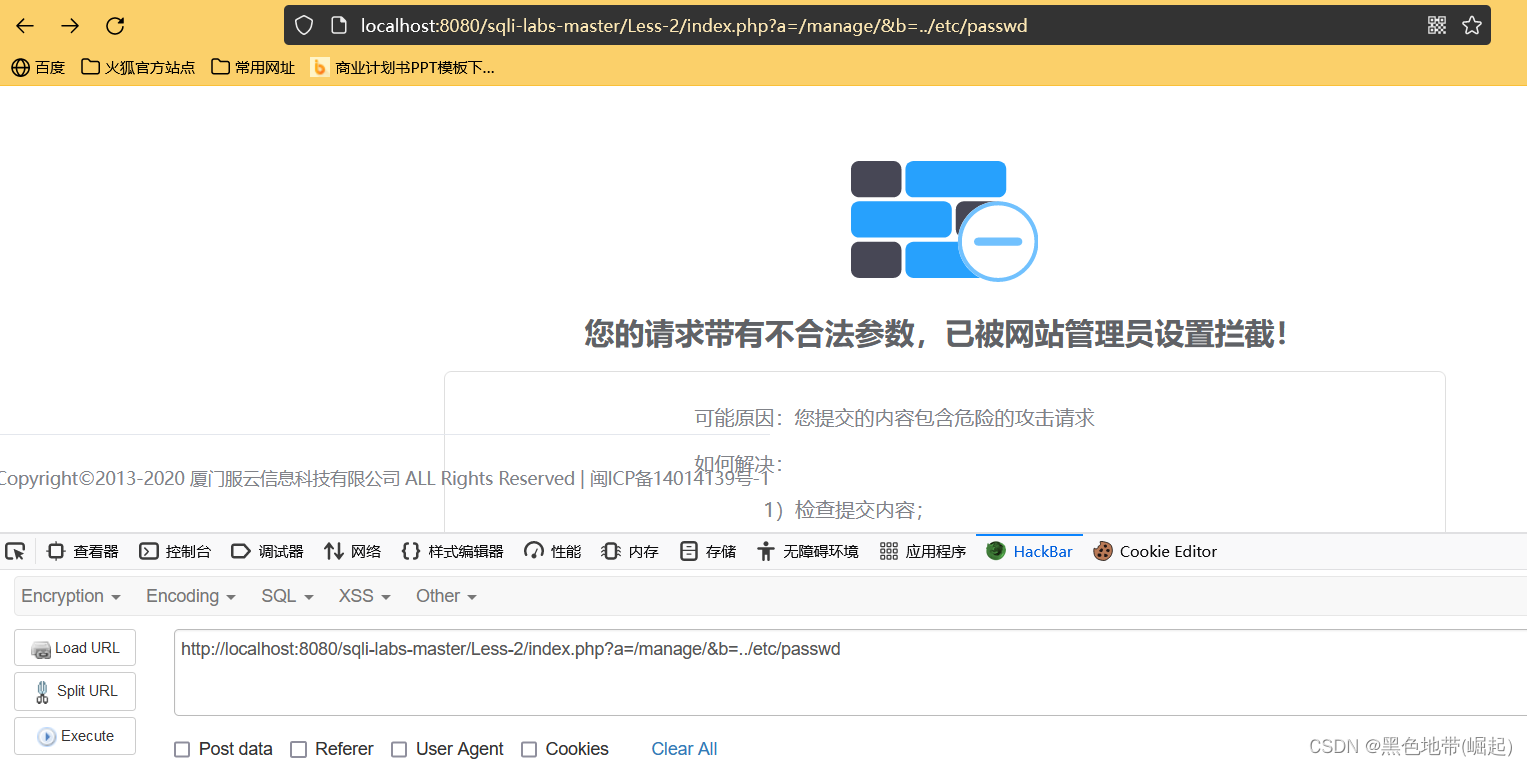
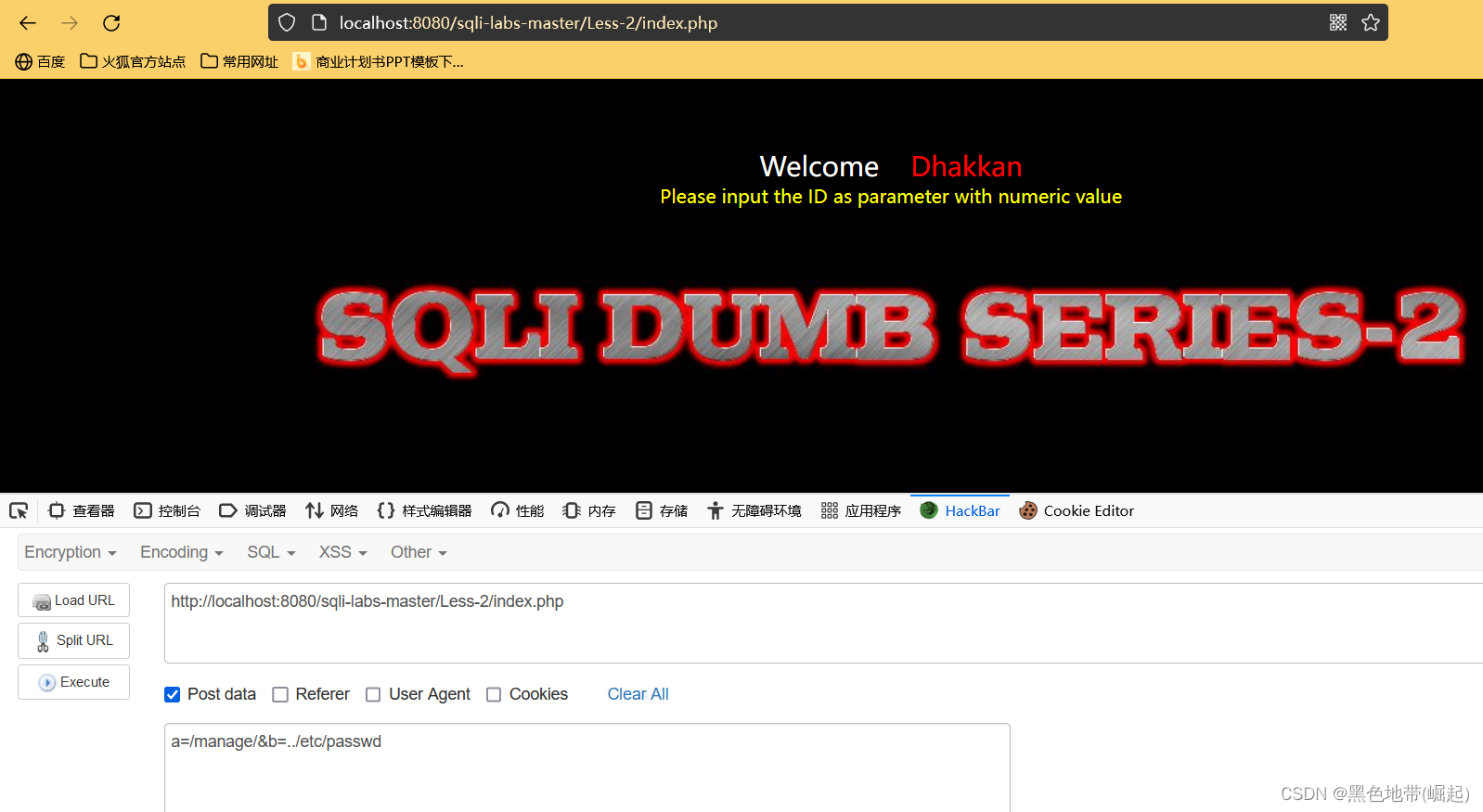
(这里不存在表单提交啥的,所有可能就不接收POST提交)
URL/../../manage/../sql.asp?id=2
(这个可能就要先把文件目录地图爬出来)
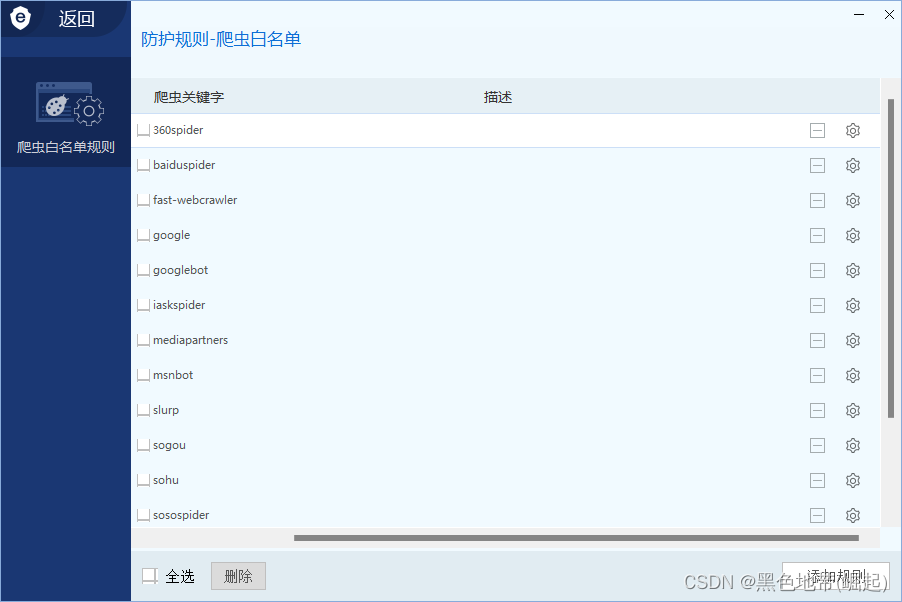
④爬虫白名单(自我认为用处相比较大)
站点为了提高在SEO上的排名,会设置对大型搜索引擎的爬虫不做检验(百度,谷歌啥的)
也就是说,如果把数据包中user-agent字段中替换成搜索引擎信息,就可以绕过WAF的检验
部分waf有提供爬虫表名单的功能,识别爬虫的技术一般有两种:
根据UserAgent,可以很容易欺骗,我们可以伪装成爬虫尝试爬过
通过行为判断
User Agent Switch(Firefox附加组件)
根据爬虫白名单里面的搜索引擎列表,在网上去查他们的user-agent字段
我搜了一下baidu的
PC端的是:
Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
UA端的是:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
产品名称 对应user-agent
网页搜索 Baiduspider
无线搜索 Baiduspider
图片搜索 Baiduspider-image
视频搜索 Baiduspider-video
新闻搜索 Baiduspider-news
百度搜藏 Baiduspider-favo
百度联盟Baiduspider-cpro
竞价蜘蛛Baiduspider-sfkr
(来自百度百科)
编写脚本绕过
或者使用pycharm运行python文件
python运行脚本文件的3种方法_黑色地带(崛起)的博客-CSDN博客
pycharm:No module named ‘requests‘类似衍生的问题你真的解决了嘛?
import json
import requestsurl='http://localhost:8080/sqli-labs-master/Less-2/'head={'User-Agent':'Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)'}for data in open('xxx.txt'):data=data.replace('\n','')urls=url+datacode=requests.get(urls).status_codeprint(urls+'|'+str(code))
工具绕过
自动化绕WAF的实用渗透工具——WAFNinja
(这里建议如果出现的问题太多,就换工具吧,条条大路通罗马,用手工字典说不定更好)
下载地址:
WoLpH/python-progressbar: Progressbar 2 - A progress bar for Python 2 and Python 3 - "pip install progressbar2" (github.com)
在这先给大家把我入的坑避一下(我成功花了一天时间入了所有坑)
(网上的安装教程一看就几行代码的事情,但是我搞起来遇见了所有问题)
第一个坑:下载WAFNinja后没点进去看需求环境

第二个坑:sudo pip install processbar

下的是1.0.7版本的
第三个坑:有多个版本python
文件啥都放在python2.7.8里面,结果下载的模块直接到python3.9里面了

第四个坑:ImportError:No module named xxxx
就是没有xxx安装包,一定要根据所需的版本安装,
我要下3个安装包,到头来删删下下,最后懵逼了
第五个坑:想用python3试试行不行,结果变成了打印
(虽然学过python,但是命令符里面还是要好好学学如何用,前路漫漫)

burpsuite
burpsuite自带的注入功能

sqlmap
使用sqlmap自带的脚本进行绕过
直接使用kali Linux等渗透系统中sqlmap,简单的使用入门
(脚本位置在:/usr/share/sqlmap/tamper/)
我用的是kali上自带的sqlmap

检测是否有waf
(–-identify-waf 检测WAF:新版的sqlmap里面,已经过时了,不能使用了)
sqlmap -u "URL" --batch
--batch(进行默认配置检查)

is protected by some kinds of WAF/IPS
(受到某种WAF/IPS保护)
规则:waf拦截(以安全狗为例)
相关注入工具都被列为拦截对象。且根据HTTP头部进行拦截

使用自带绕过脚本进行绕过测试(现实中一般没什么用)
--random-agent 使用任意HTTP头进行绕过
--porxy=http//127.0.0.1:8080(可以用burpsuite等进行代理)
sqlmap -u "URL" --tamper=模块
(可指定多个模块)

all tested parameters do not appear to be injectable.
(所有测试的参数都不是可注射的。)
可以使用编写的tamper脚本(现实中一般需要自己编写)
(需要一点编程基础)
在执行的过程中可能会遇见被拦截
可以考虑设置延迟、设置代理池、伪装爬虫等方式
Fuzz/爆破
很多工具都是编写的python脚本运行的手工所需要进行测试
??????python运行脚本文件的3种方法
也可使用pycharm运行python脚本文件
pycharm:No module named ‘requests‘类似衍生的问题你真的解决了嘛?
fuzz字典
Seclists/Fuzzing
https://github.com/danielmiessler/SecLists/tree/master/Fuzzing
Fuzz-DB/Attack
https://github.com/fuzzdb-project/fuzzdb/tree/master/attack
Other Payloads 小心使用
https://github.com/foospidy/payloads
