вЛЃЌЛљДЁЛЗОГ
1ЁЂжїЛњУћХфжУ
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3vim /etc/hosts
192.168.137.128 node1
192.168.137.129 node2
192.168.137.130 node3
2ЁЂАВзАJDK
tar zxf /root/jdk1.8.0_101.tar.gz -C /data/
echo 'export PATH=$PATH:/data/jdk1.8.0_101/bin' >>/etc/profile
source /etc/profile
3ЁЂХфжУSSHЮоУмТыЕЧТН(Ш§ЬЈЗўЮёЦїЖМашвЊУтУм)
ssh-keygen
ssh-copy-id -i id_rsa.pub root@node1
ЖўЁЂАВзАHadoop2.7.2
1ЁЂАВзАЃЈЪзЯШдкnode1ЩЯАВзАЃЉ
mkdir /data/hadoop
mkdir -p /data/hadoop/hdfs
tar zxf hadoop-2.7.2.tar.gz -C /data/hadoop/#ЩшжУЛЗОГБфСП
#vim /etc/profile
export HADOOP_HOME=/data/hadoop/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib#ЪЙЛЗОГБфСПЩњаЇ
source /etc/profile
2ЁЂХфжУ
ЃЈ1ЃЉХфжУhadoop-env.sh
cd /data/hadoop/hadoop-2.7.2/etc/hadoop
export JAVA_HOME=/data/jdk1.8.0_101
ЃЈ2ЃЉХфжУyarn-env.sh
export JAVA_HOME=/data/jdk1.8.0_101
ЃЈ3ЃЉХфжУcore-site.xml
<configuration>
<property><name>fs.default.name</name><value>hdfs://node1:9000</value><description>HDFSЕФURIЃЌЮФМўЯЕЭГ://namenodeБъЪЖ:ЖЫПкКХ</description>
</property><property><name>hadoop.tmp.dir</name><value>/data/hadoop/tmp</value><description>namenodeЩЯБОЕиЕФhadoopСйЪБЮФМўМа</description>
</property>
</configuration>
ЃЈ4ЃЉХфжУhdfs-site.xml
<configuration>
<!-- ЩшжУnamenodeЕФhttpЭЈбЖЕижЗ --><property><name>dfs.namenode.http-address</name><value>node1:50070</value></property><!-- ЩшжУsecondarynamenodeЕФhttpЭЈбЖЕижЗ --><property><name>dfs.namenode.secondary.http-address</name><value>node1:50090</value></property><!-- ЩшжУnamenodeДцЗХЕФТЗОЖ --><property><name>dfs.namenode.name.dir</name><value>/data/hadoop/hdfs/name</value></property><!-- ЩшжУhdfsИББОЪ§СП --><property><name>dfs.replication</name><value>1</value></property><!-- ЩшжУdatanodeДцЗХЕФТЗОЖ --><property><name>dfs.datanode.data.dir</name><value>/data/hadoop/hdfs/data</value></property>
</configuration>
ЃЈ5ЃЉХфжУmapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
</configuration>
ЃЈ6ЃЉХфжУyarn-site.xml
<configuration>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.resourcemanager.webapp.address</name><value>${yarn.resourcemanager.hostname}:8088</value>
</property>
</configuration>
ЃЈ7ЃЉХфжУslavesЮФМў
vim $HADOOP_HOME/etc/hadoop/slaves
node2
node3
ЕНДЫnode1НкЕуХфжУЭъГЩЃЌnode2ЁЂnode3НкЕугыnode1НкЕуХфжУвЛжТЃЌжЛашдкnode2КЭnode3ЩЯНЋЩЯЪіВйзїжиИДвЛБщМДПЩЃЌЭЦМіжБНгНЋХфжУКУЕФАВзАФПТМКЭЛЗОГБфСПИДжЦвЛЗнЕНЦфЫћСНИіНкЕуЁЃ
scp -r hadoop/ root@node2:/data
scp -r hadoop/ root@node3:/data
3ЁЂЦєЖЏЃЈnode1ЩЯжДааЃЉ
ЃЈ1ЃЉИёЪНЛЏnamenode(жЛашЕквЛДЮЦєЖЏЪБжДаа)
hdfs namenode -format
ЃЈ2ЃЉЦєЖЏNameNode КЭ DataNode ЪиЛЄНјГЬ
sbin/start-dfs.sh
ЃЈ3ЃЉЦєЖЏбщжЄ
#жДааjpsУќСюЃЌгаШчЯТНјГЬЃЌЫЕУїHadoopе§ГЃЦєЖЏ
15698 Jps
15581 SecondaryNameNode
15406 NameNode
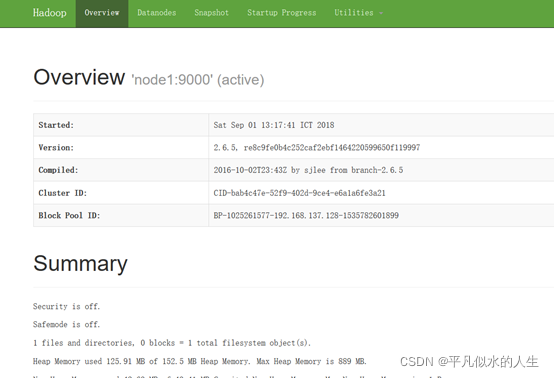
ЃЈ4ЃЉЦєЖЏГЩЙІКѓПЩдкфЏРРЦїЪфШы http://192.168.137.128:50070 ВщПДhdfsЯъЧщ
ЃЈ5ЃЉЦєЖЏResourceManager КЭ NodeManager ЪиЛЄНјГЬ
./start-yarn.sh
ЃЈ6ЃЉдкфЏРРЦїжаЪфШыЃКhttp://192.168.137.128:8088/ МДПЩПДЕНYARNЕФResourceManagerЕФНчУц