ǰ��
���Ȼ�ʹ��Java����һ����־��������ʹ��Flume�ռ�����Ϣ��Kafka��Ȼ��Spark Streaming ��Kafka��ȡ��Ϣ��
������Ŀ���룺
https://github.com/GYT0313/Spark-Learning/tree/master/sparkstream
1. ��־������
������Ӧ�ô���һ��Maven ��Ŀ���ο���https://blog.csdn.net/qq_38038143/article/details/89926205
��test Ŀ¼�´���java ��Ŀ��������LoggerGenerator �࣬�Լ�resourcesĿ¼��log4j.properties��
�� Project structure�����ã�

Ŀ¼�ṹ��
LoggerGenerator.class
import org.apache.log4j.Logger;/*** ģ����־����*/public class LoggerGenerator {private static Logger logger = Logger.getLogger(LoggerGenerator.class.getName());public static void main(String[] args) throws Exception {int index = 0;while (true) {Thread.sleep((1000));logger.info("value:" + index++);}}
}
log4j.properties
log4j.rootCategory=INFO, console, flume
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy/MM/dd HH:mm:ss} %p %c{1}: %m%n# log to flume
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = master
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true
log4j.appender.flume.layout = org.apache.log4j.PatternLayout
pom.xml ������
<properties><scala.version>2.11.8</scala.version><kafka.version>2.1.1</kafka.version><spark.version>2.3.2</spark.version><hadoop.version>2.7.3</hadoop.version><hbase.version>1.4.8</hbase.version><mysql.version>5.1.46</mysql.version><flume.version>1.9.0</flume.version></properties><dependencyManagement><dependencies><!--netty confluent--><dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.17.Final</version></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>org.jboss.netty</groupId><artifactId>netty</artifactId><version>3.2.4.Final</version></dependency><!--Spark Streaming--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>${spark.version}</version></dependency><!--Spark SQL--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><!--Flume- run by spark-submit need--><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-auth</artifactId><version>${flume.version}</version></dependency><dependency><groupId>org.mortbay.jetty</groupId><artifactId>servlet-api</artifactId><version>2.5-20110124</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-flume-sink_2.11</artifactId><version>${spark.version}</version></dependency><!--flume_pull need--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.5</version></dependency><!--Streaming-Flume-No version2.4.0--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-flume_2.11</artifactId><version>${spark.version}</version></dependency><!--Avro-why need: run flume get a avro wrong-java.lang.AbstractMethodError--><dependency><groupId>org.apache.avro</groupId><artifactId>avro</artifactId><version>1.7.4</version></dependency><!--Streaming-Kafka--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>com.fasterxml.jackson.module</groupId><artifactId>jackson-module-scala_2.11</artifactId><version>2.6.7.1</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scalatest</groupId><artifactId>scalatest</artifactId><version>0.9.1</version></dependency><!--Kafka--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.11</artifactId><version>${kafka.version}</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version></dependency><!--Hadoop--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!--Hbase--><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><!--JDBC--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>org.specs</groupId><artifactId>specs</artifactId><version>1.2.5</version><scope>test</scope></dependency><!--log to flume--><dependency><groupId>org.apache.flume.flume-ng-clients</groupId><artifactId>flume-ng-log4jappender</artifactId><version>${flume.version}</version></dependency><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-sdk</artifactId><version>${flume.version}</version></dependency><!--project run by spark-submit wrong--><dependency><groupId>net.jpountz.lz4</groupId><artifactId>lz4</artifactId><version>1.3.0</version></dependency></dependencies><build>��������
���ԣ��������flume��
��flume-1.9.0/conf Ŀ¼�´�����
streaming.conf
# Name the components on this agent
agent1.sources = avro-source
agent1.sinks = log-sink
agent1.channels = logger-channel# Describe/configure the source
agent1.sources.avro-source.type = avro
agent1.sources.avro-source.bind = master
agent1.sources.avro-source.port = 41414# Describe the sink
agent1.sinks.log-sink.type = logger# Use a channel which buffers events in memory
agent1.channels.logger-channel.type = memory# Bind the source and sink to the channel
agent1.sources.avro-source.channels = logger-channel
agent1.sinks.log-sink.channel = logger-channel
����flume��
# ����
bin/flume-ng agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/streaming.conf \
--name agent1 \
-Dflume.root.logger=INFO,console

����LoggerGeneraotr��

��־������������ɡ�����
2. Spark Streaming ��kakfa��ȡ����
��������zookeeper��������kafka��
����kafka���⣺
# kafka ��������
kafka-topics.sh --create --zookeeper slave1:2181 \
--replication-factor 1 --partitions 1 --topic streaming_topic

����StreamingKafkaApp.scala
��ָ����topic ������Ϣ�����Ҽ������������̨��
package com.gyt.sparkstreamimport org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._object StreamingKafkaApp {def main(args: Array[String]) {if (args.length < 3) {System.err.println("Usage: StreamingKafkaApp <brokers> <groupId> <topics>")System.exit(1)}val Array(brokers, groupId, topics) = args// Create context with 2 second batch intervalval sparkConf = new SparkConf().setAppName("StreamingKafkaApp").setMaster("local[2]")val ssc = new StreamingContext(sparkConf, Seconds(5))// Create direct kafka stream with brokers and topicsval topicsSet = topics.split(",").toSetval kafkaParams = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,ConsumerConfig.GROUP_ID_CONFIG -> groupId,ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])// Create direct inputStreamval messages = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))// Get the lines, split them into words, count the words and printmessages.map(_.value()).count().print()// Start the computationssc.start()ssc.awaitTermination()}
}
���Գ���
����kafka�����ߺ������ߣ�
����ʹ�õ��Ǽ�Ⱥ��������ǵ��������������������ɣ�slave1��Ϊ��������
# �ն�1-������
kafka-console-producer.sh --broker-list slave1:9092 \
--topic streaming_topic# kafka����
kafka-console-consumer.sh --bootstrap-server slave1:9092 \
--topic streaming_topic --from-beginning
���ԣ�

����spark ����һ�α�����Ȼ�����ò�����
������broker group topic

�������߳�������Ϣ��

3. ������־������-Fluem-Kafka-Spark Streaming
����Flume��Ϊʲô�������ã����Բ鿴Flume����
flume-1.9.0/conf/streaming2.conf
# Name the components on this agent
agent1.sources = avro-source
agent1.channels = logger-channel
agent1.sinks = kafka-sink# Describe/configure the source
agent1.sources.avro-source.type = avro
agent1.sources.avro-source.bind = master
agent1.sources.avro-source.port = 41414# Describe the sink
agent1.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafka-sink.kafka.topic = streaming_topic
agent1.sinks.kafka-sink.kafka.bootstrap.servers = slave1:9092
agent1.sinks.kafka-sink.kafka.flumeBatchSize = 20
agent1.sinks.kafka-sink.kafka.producer.acks = 1# Use a channel which buffers events in memory
agent1.channels.logger-channel.type = memory# Bind the source and sink to the channel
agent1.sources.avro-source.channels = logger-channel
agent1.sinks.kafka-sink.channel = logger-channel
������
# ����
bin/flume-ng agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/streaming2.conf \
--name agent1 \
-Dflume.root.logger=INFO,console

����Kafka ������ʹ�õ��Ǽ�Ⱥ��������ǵ���������������������
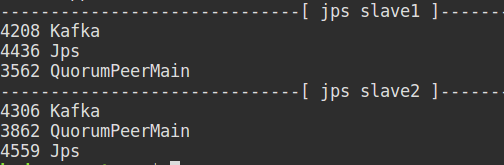
����Spark Streaming��

���������־������LoggerGenerator��
