本节主要内宾
- Spark SQL简介
- DataFrame
1. Spark SQL简介
Spark SQL是Spark的五大核心模块之一,用于在Spark平台之上处理结构化数据,利用Spark SQL可以构建大数据平台上的数据仓库,它具有如下特点:
(1)能够无缝地将SQL语句集成到Spark应用程序当中 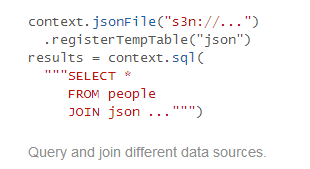
(2)统一的数据访问方式
DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources. 
(3) 兼容Hive 
(4) 可采用JDBC or ODBC连接 
具体见:http://spark.apache.org/sql/
关于Spark SQL的运行原理可参见:http://blog.csdn.net/book_mmicky/article/details/39956809,文章写得非常好 ,这里不再赘述,在此向作者致敬
2. DataFrame
(1)DataFrame简介
本文部分内容译自https://databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html
DataFrames在Spark-1.3.0中引入,主要解决使用Spark RDD API使用的门槛,使熟悉R语言等的数据分析师能够快速上手Spark下的数据分析工作,极大地扩大了Spark使用者的数量,由于DataFrames脱胎自SchemaRDD,因此它天然适用于分布式大数据场景。相信在不久的将来,Spark将是大数据分析的终极归宿。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,与传统RDBMS的表结构类似。与一般的RDD不同的是,DataFrame带有schema元信息,即DataFrame所表示的表数据集的每一列都带有名称和类型,它对于数据的内部结构具有很强的描述能力。因此Spark SQL可以对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率。
DataFrames具有如下特点:
(1)Ability to scale from kilobytes of data on a single laptop to petabytes on a large cluster(支持单机KB级到集群PB级的数据处理)
(2)Support for a wide array of data formats and storage systems(支持多种数据格式和存储系统,如图所示) 
(3)State-of-the-art optimization and code generation through the Spark SQL Catalyst optimizer(通过Spark SQL Catalyst优化器可以进行高效的代码生成和优化)
(4)Seamless integration with all big data tooling and infrastructure via Spark(能够无缝集成所有的大数据处理工具)
(5)APIs for Python, Java, Scala, and R (in development via SparkR)(提供Python, Java, Scala, R语言API)
(2)DataFrame 实战
本节部分内容来自:http://spark.apache.org/docs/latest/sql-programming-guide.html#dataframes
将people.json上传到HDFS上,放置在/data目录下,people.json文件内容如下:
root@sparkslave01:~# hdfs dfs -cat /data/people.json{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}由于json文件中已经包括了列名称的信息,因此它可以直接创建DataFrame
scala> val df = sqlContext.read.json("/data/people.json")df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]//显示DataFrame完整信息scala> df.show()+----+-------+| age| name|+----+-------+|null|Michael|| 30| Andy|| 19| Justin|+----+-------+
//查看DataFrame元数据信息scala> df.printSchema()root |-- age: long (nullable = true) |-- name: string (nullable = true)//返回DataFrame某列所有数据scala> df.select("name").show()+-------+| name|+-------+|Michael|| Andy|| Justin|+-------+//DataFrame数据过滤scala> df.filter(df("age") > 21).show()+---+----+|age|name|+---+----+| 30|Andy|+---+----+//按年龄分组scala> df.groupBy("age").count().show()+----+-----+| age|count|+----+-----+|null| 1|| 19| 1|| 30| 1|+----+-----+//注册成表scala> df.registerTempTable("people")//执行SparkSQLscala> val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")teenagers: org.apache.spark.sql.DataFrame = [name: string, age: bigint]//结果格式化输出scala> teenagers.map(t => "Name: " + t(0)).collect().foreach(println)Name: Justin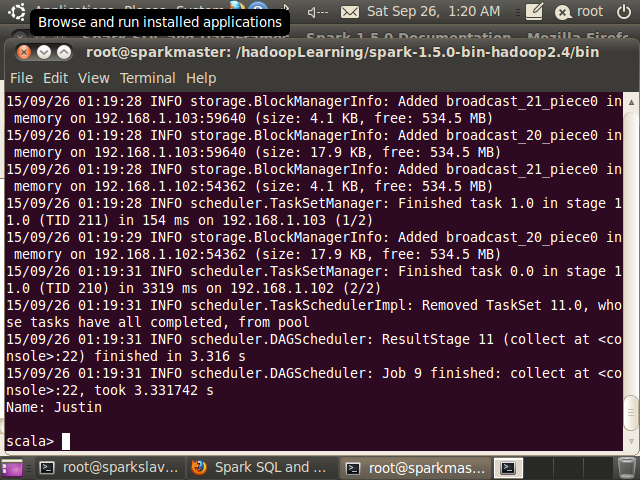
版权声明:本文为博主原创文章,未经博主允许不得转载。