ǰ��
���½ڽ�����ν�Spark Streaming ��Kafka���ϡ�����Kafka�����ж�ȡ���ݣ�������ʵʱ���ġ�
������Kafka�Ǽ�Ⱥ�����û�У�Ҳ���Բ����ü�Ⱥ��
1. ��װzookeeper
���https://blog.csdn.net/qq_38038143/article/details/84203344
1. ��װKafka
ע��ѡ��Kafka-2.11-2.1.1����scalaѡ��2.11�棬�ο�������ʹ�õ�2.12��
���https://blog.csdn.net/qq_38038143/article/details/88779174
3. ������������
- ����zookeeper
- ����kafka
- ��������
kafka-topics.sh --zookeeper master:2181 --create --topic kafka_streaming --replication-factor 1 --partitions 1
- д���ݺͶ�ȡ���� - ���������ն�
# �ն�1-������
kafka-console-producer.sh --broker-list slave1:9092 \
--topic kafka_streaming# �ն�2-������
kafka-console-consumer.sh --topic kafka_streaming \
--bootstrap-server slave1:9092 \
--from-beginning
����ܹ�д���Ͷ������ˣ�


4. pom.xml����
Hadoop��hbase���ò����Ŀ��Բ�д��
<properties><scala.version>2.11.8</scala.version><kafka.version>2.1.1</kafka.version><spark.version>2.4.0</spark.version><hadoop.version>2.7.3</hadoop.version><hbase.version>1.4.8</hbase.version><mysql.version>5.1.46</mysql.version></properties><dependencyManagement><dependencies><!--netty confluent--><dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.17.Final</version></dependency></dependencies></dependencyManagement><dependencies><!--Spark Streaming--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>${spark.version}</version></dependency><!--Spark SQL--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>com.fasterxml.jackson.module</groupId><artifactId>jackson-module-scala_2.11</artifactId><version>2.6.7.1</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scalatest</groupId><artifactId>scalatest</artifactId><version>0.9.1</version></dependency><!--Kafka--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.11</artifactId><version>${kafka.version}</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version></dependency><!--Hadoop--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!--Hbase--><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><!--JDBC--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>org.specs</groupId><artifactId>specs</artifactId><version>1.2.5</version><scope>test</scope></dependency></dependencies><build>.......
5. ����
ע�⣺ȫ�̶�Ҫ����kafka�������߽��̣�������д�����ݣ��Żῴ�����Ч����
�ο��ٷ�ʾ����
spark��װĿ¼��
examples/src/main/scala/org/apache/spark/examples/streaming/DirectKafkaWordCount.scala
IDEA������
������һ�Σ�Ȼ����IDEA���Ͻǵ��Edit ���ò�����
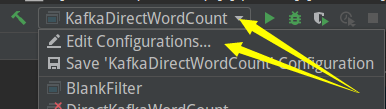
�Կո�ָ������broker����������id���������ƣ������Լ���

���룺KafkaDirectWordCount.scala
package com.gyt.sparkstreamimport org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._object KafkaDirectWordCount {def main(args: Array[String]) {if (args.length < 3) {System.err.println("Usage: KafkaDirectWordCount <brokers> <groupId> <topics>")System.exit(1)}val Array(brokers, groupId, topics) = args// Create context with 2 second batch intervalval sparkConf = new SparkConf().setAppName("KafkaDirectWordCount").setMaster("local[2]")val ssc = new StreamingContext(sparkConf, Seconds(5))// Create direct kafka stream with brokers and topicsval topicsSet = topics.split(",").toSetval kafkaParams = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,ConsumerConfig.GROUP_ID_CONFIG -> groupId,ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])// Create direct inputStreamval messages = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))// Get the lines, split them into words, count the words and printval lines = messages.map(_.value)val wordCount = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)wordCount.print()// Start the computationssc.start()ssc.awaitTermination()}
}����

6. ����spark������
ʹ��Maven �����Ŀ��������Ŀ·���£�
ִ�����mvn clean package -DskipTests
������ִ�е�������mvn install����Ϊ֮ǰִ�й�����������������ִ��install��ִ��clean���ɣ�

���� JAR����
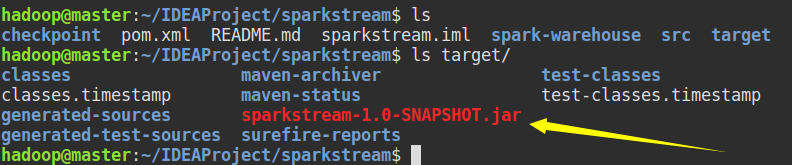
�ύ����������
�Cclass ָ��main�࣬��������Ŀ�е�·��
�Cpackages һ������
�������jar��·������������
spark-submit \
--class com.gyt.sparkstream.KafkaDirectWordCount \
--master local[2] \
--name KafkaDirectWordCount \
--packages org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.0 \
/home/hadoop/lib/sparkstream-1.0-SNAPSHOT.jar \
slave1:9092 kafka_streaming_group3 kafka_streaming
���Ȼ�����һЩ������Ȼ��ʼִ�У�


������ĿGitHub��
https://github.com/GYT0313/Spark-Learning