前言
因为《Spark-快速大数据分析》使用Spark 版本较老,并且1.1 下的Streaming 并未支持Python,所以书上并没有相应的Python 版本的代码。
因此,博主这节参考官网手册学习:
http://spark.apache.org/docs/latest/streaming-programming-guide.html
如果,你的浏览器不支持翻译,这里提供了翻译的版本:
链接:https://pan.baidu.com/s/113LVfghzF7UZen260u1ZPg
提取码:wg1f
这里就不详写Spark Streaming的各种功能和特点了。看官网即可。
博主在这里仅写出一些运行示例,和一些认为重要的点吧。所以,文章的顺序比较乱,但顺序是按照官网的顺序排列
博主使用Spark 版本:2.4.0 (前面的文章博主使用的是2.0.2)
示例代码见GitHub:
https://github.com/GYT0313/Spark-Learning
1. 示例
博主这里仍然使用的是Spark 集群运行。
假设从侦听TCP套接字的数据服务器接收的文本数据的运行字数。
NetworkWordCount.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext# 创建一个sc(使用本地2个core) 和时间间隔为4s 的ssc
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 4)# 创建DStream,并读取套接字
lines = ssc.socketTextStream("master", 9999)# 单词计数
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)# 将每个RDD的前10个元素打印
wordCounts.pprint()ssc.start() # 启动计算
ssc.awaitTermination() # 等待终止
先运行发送套节字:

提交应用:master 和 9999可以不用写,这里写了相当于命令行参数,后面知道

输入套节字内容:

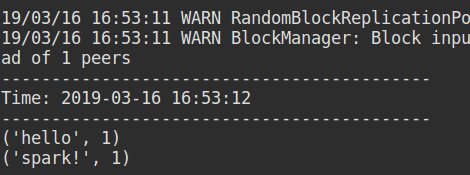
Ctrl + c 结束应用。
剖析运行流程:
- 创建StreamingContext,设置batch interval(批次间隔)
ssc = StreamingContext(sc, 4) - 读取流数据,如套接字、文件、Kafka等
lines = ssc.socketTextStream(“master”, 9999) - 输出操作,如输出到控制台、文件、数据库等
wordCounts.pprint()
可以说,Spark Streaming的大多数应用都将遵循上述的三个步骤。
官网解释(机器翻译可能存在语句问题):

2. 输入DStreams和Receivers

红框的内容非常重要:

基本来源
- 套接字
上述示例展示了从套接字读取。 - 文件
代码:
ReadFromFile.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext# 创建一个sc(使用集群) 和时间间隔为5 的ssc
sc = SparkContext("spark://master:7077", "ReadFromFile")
ssc = StreamingContext(sc, 5)lines = ssc.textFileStream("hdfs://master:9000/user/hadoop/spark_data/")
lines.pprint()ssc.start() # 启动计算
ssc.awaitTermination() # 等待终止
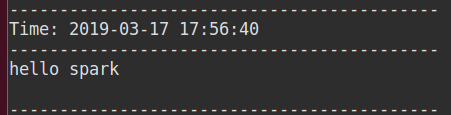
运行:

上传文件:

结果:
3.自定义来源,需要用户自定义接收器
4. RDD作为流的队列
5. 等等,有兴趣可以查看官网。
3. reduceByKeyAndWindow 和 checkpoint 示例
窗口操作有很多,这里以reduceByKeyAndWindow 为例。值得一提的是:不能单独使用reduceByKeyAndWindow,必须同时设置checkpoint
官网也有相应的代码示例(reduceByKey,checkpoint、累加器、广播变量),不过博主看过源代码之后,觉得可以写一个简单的示例(毕竟自己构思过,理解和印象会更深刻)。所以,自己尝试写出一个示例来验证reduceByKeyAndWindow 和 checkpoint 的运行结果是如何,以此来理解运行原理。
官网
https://github.com/apache/spark/blob/master/examples/src/main/python/streaming/recoverable_network_wordcount.py
Spark安装包:
Spark-2.4.0/examples/src/main/python/streaming/recoverable_network_wordcount.py
编写脚本:
和第一个示例一样,同样使用套接字作为数据源。
NetworkWordCountAndWindow.py
由于博主使用的是 HDFS 为存储系统,所以先再HDFS 上创建了目录 /tmp/spark/checkpoint,如果是使用本地我文件系统,进行相应改变即可(博主没尝试过)。
from pyspark import SparkContext
from pyspark.streaming import StreamingContextdef functionToCreateContext():# 创建一个sc 和批处理时间间隔为2s 的sscsc = SparkContext("spark://master:7077", "NetworkWordCountAndWindow")ssc = StreamingContext(sc, 2)# 设置检查的目录ssc.checkpoint("hdfs://master:9000/tmp/spark/checkpoint")# 创建DStream,并读取套接字lines = ssc.socketTextStream("master", 9999)# 单词计数words = lines.flatMap(lambda line: line.split(" "))pairs = words.map(lambda word: (word, 1))# 设置逆函数(如 + 对应 -。作用是提升应用处理效率等等。逆函数博主也很迷糊,如果想要深入了解的# 可搜索其他详解讲解这部分的博客),窗口时间=12和滑动时间=4(必须为批处理间隔的倍数)wordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 12, 4)# 设置检查点的间隔(比如待会出现的报错就可能是因为某些# 数据未来得及被检查点保存,将会导致数据的丢失)# 官网建议:DStream的5-10个滑动间隔的检查点间隔是一个很好的设置。wordCounts.checkpoint(16)# 将每个RDD的前10个元素打印wordCounts.pprint()return ssc# 如果存在检查的目录则读取,没有则新建
ssc = StreamingContext.getOrCreate("hdfs://master:9000/tmp/spark/checkpoint", functionToCreateContext)ssc.start() # 启动计算
ssc.awaitTermination() # 等待终止
先启动nc ,再启动应用:

master 和9999 可以不写:

在套接字中输入连续很多的数字(时间应该够长保证检查点能够存储 并且数据应该尽量多样化,能够在下次启动时明显看到变化):

窗口和滑动的理解:
比如,下图中’1’的次数在第一个窗口中偏多,'2’的次数偏少。
但是,在第二个窗口中’1’的偏少,'2’偏多。
输出的数据示例:

修改官网的图片,以此解释:
从下图中就可以理解,如果套接字的输入顺序为:1、1、1、1、1、2、2、2、2。。。那么,第二个窗口的的’2’比第一个窗口多,'1’比第一个窗口少。

这时使用Ctrl + C 终止应用:

可以在 /tmp/spark/checkpoint 下看到存在很多文件,这些文件即为元数据检查点或数据检查点文件(元数据检查点用于恢复应用程序的配置如 sc、ssc等。数据检查点用于恢复如RDD等数据):
hdfs dfs -ls /tmp/spark/checkpoint
再次启动应用,并在未终止的nc 程序中输入 50 50 50 …:
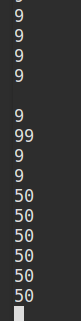
在控制台中可以看到如下输出:
3、36、6、9等数据是检查点保存的数据,因为特殊原因被终止,并且在代码中设置了如果存在检查点目录将读取已有的配置,而不是创建新的sc、ssc等。
所以,在上次应用程序中保存的数据能够在这一次的应用中出现。

下面报错为上图的报错信息(对应代码中的注释):
Some blocks could not be recovered as they were not found in memory. To prevent such data loss, enable Write Ahead Log (see programming guide for more details.
有些块无法恢复,因为它们在内存中找不到。要防止此类数据丢失,请启用“预写日志”(有关详细信息,请参阅编程指南)。
当然,这里也说了可以启用“预写日志”来防止数据丢失。
4. foreachRDD
博主认为官网的foreeachRDD 比较重要,而且讲解也让人深刻。推荐阅读。
小节的标题如下:

下图的解释即RDD 的惰性操作,没有行为操作的话是不会进行求值计算的:

5. 累加器,广播变量和检查点
代码:
AccumulatorsBroadcastCheckpoint.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext# 创建一个sc 和时间间隔为4s 的ssc
sc = SparkContext("spark://master:7077", "AccumulatorsBroadcastCheckpoint")
ssc = StreamingContext(sc, 4)# 广播变量,用与筛选列表
def getWordBlacklist(sparkContext):if ("wordBlacklist" not in globals()): # 全局变量是否包含globals()["wordBlacklist"] = sparkContext.broadcast(["a", "b", "c"])return globals()["wordBlacklist"]# 累加器用于计数筛选掉的数量
def getDroppedWordsCounter(sparkContext):if ("droppedWordCounter" not in globals()):globals()["droppedWordCounter"] = sparkContext.accumulator(0)return globals()["droppedWordCounter"]def echo(time, rdd):# 创建或获取广播变量blacklist = getWordBlacklist(rdd.context)# 创建或获取累加器droppedWordCounter = getDroppedWordsCounter(rdd.context)def filterFunc(wordCount):# 如果该单词在筛选列表中,则累加器求和if wordCount[0] in blacklist.value:droppedWordCounter.add(wordCount[1])Falseelse:True# 过滤,必须调用collect() 行为操作rdd.filter(filterFunc).collect()# 输出累加器print('droppedWordCounter = %s' % droppedWordCounter)# 创建DStream,并读取套接字
lines = ssc.socketTextStream("master", 9999)# 单词计数
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)# 将每个RDD的前10个元素打印
wordCounts.foreachRDD(echo)ssc.start() # 启动计算
ssc.awaitTermination() # 等待终止
启动nc :

启动应用:

nc 中输入:

结果:
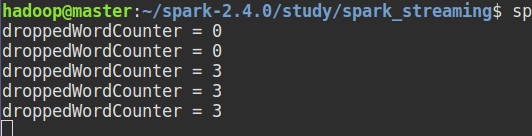
可以看到, a b c 被拦截,并且累加器做了计数。
所以,如果访问将访问日志作为数据源,不断发送。将 ERROR、WARNING等作为广播变量,就可以从日志中提取出自己想要的信息。