述
上文中分析了JDK1.7和1.8中的 HashMap 的数据结构以及一些重要的方法,本文同样从这两个版本,分析一下 ConcurrentHashMap
JDK1.7 中的 ConcurrentHashMap
数据结构
如图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jESmkgHJ-1587203684708)(http://r.photo.store.qq.com/psc?/V10eEnSd0rz4Am/2aGbA7qLSN6GeC6g0ZsuRXCp8*B*9t1XrUNtIxcW9Di0dHkI0fAxI7.oBKLyYTTLdxwczPFLZXAz6PJe7SnGGQUgKVk.wjDcHVlDzNy6kUs!/r)]](https://img-blog.csdnimg.cn/20200418175543557.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MDgzNTQ1,size_16,color_FFFFFF,t_70)
Java 7 中的 ConcurrentHashMap 最外层是多个 segment, 每个 segment 的底层数据结构和 HashMap 类似的,仍然是数组和链表结构, segment 默认有16个,初始化完成之后就无法扩容,存放数据的时候,首先要先定位到具体的 segment 中
每个 Segment 都有独立的 ReentrantLock 锁,每个 Segment 之间互不干扰,挺高并发效率, 比如初始化的16个 Segment ,就可以有16个线程同时在这个 ConcurrentHashMap 进行读写
JDK1.8 中的 ConcurrentHashMap
数据结构
1.8 中数据结构如图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7MgOaHPh-1587203684710)(http://r.photo.store.qq.com/psc?/V10eEnSd0rz4Am/2aGbA7qLSN6GeC6g0ZsuRbJjRdUbyE5vcEQQd6Kpe0*0NhffvJ*ZJD8BZfBpgGS5V8KzlsIhzjK4GIV9yOD282JmQVb1HW46LffUs9n0.bk!/r)]](https://img-blog.csdnimg.cn/202004181755527.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MDgzNTQ1,size_16,color_FFFFFF,t_70)
跟 HashMap 是一样的,1.7 的版本虽然是解决了并发的问题,但是 HashMap 在 1.7 版本中的问题还是存在,就是遍历链表效率太低了,1.8版本中的 ConcurrentHashMap 抛弃了 Segment ,采用 CAS + synchronized 的方式保证并发安全
存放数据也是用1.8中的 Node ,代码如下
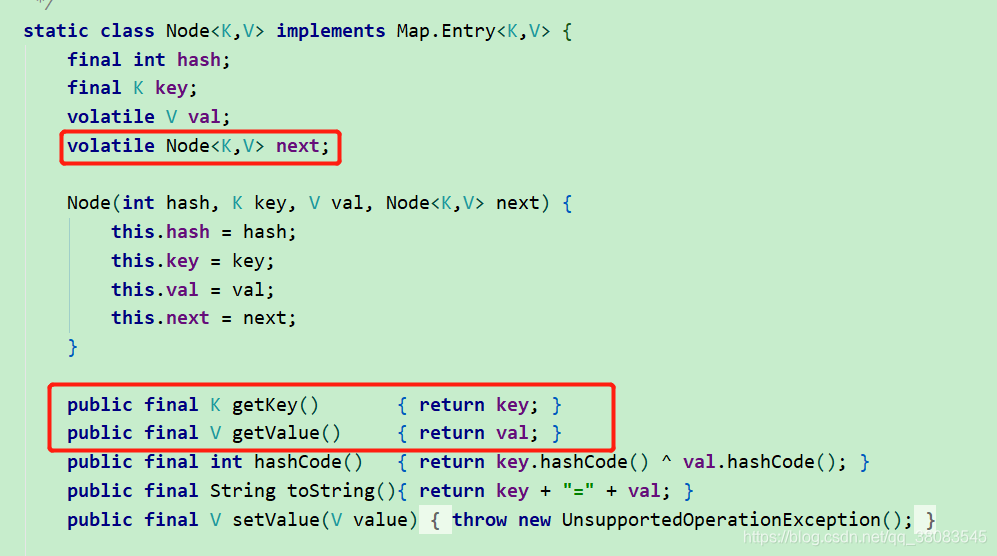
这里可以看到,value和next都是用了 volatile 修饰,保证可见性
重点方法介绍
首先看一下 put() 方法
final V putVal(K key, V value, boolean onlyIfAbsent) {// key或value为空直接抛异常if (key == null || value == null) throw new NullPointerException();// 计算hashint hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 判断是否需要初始化if (tab == null || (n = tab.length) == 0)// 空的话先去初始化tab = initTable();// 计算当前key定位出来的node即代码中的 f ,为空,表示可以写入数据else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 利用CAS写入if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// 如果当前位置是 MOVED == -1 ,表示这个槽点正在进行扩容else if ((fh = f.hash) == MOVED)// 调用帮助扩容的方法tab = helpTransfer(tab, f);else {// 这个槽里有值了,就会进入下面的代码V oldVal = null;// 把当前的node锁住synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {// 链表操作binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;// 如果链表中有了这个key了,就覆盖然后breakif (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;// 如果没有的话,放个新的,加到链表最后if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {// 如果不是链表.这里进行红黑树的操作Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 添加完成之后,判断是不是需要将链表转成红黑树 if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}
以上就是 put() 方法的一个大致流程,下面再看看 get() 方法,代码如下
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// 计算hash值int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 如果在桶上,就直接返回if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// 如果是红黑树,就按树的方式获取值else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;// 最后是按链表的方式遍历while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}
总结
最后总结一下 ConcurrentHashMap 中的 put() get() 流程
首先 put() 流程
- 判断key-value都不为空
- 计算hash值
- 根据对应位置的节点的类型赋值(利用cas),或者是
helpTransfer,或者增长链表,或者增加红黑树节点(利用synchronized个节点加锁 ) - 检查是否满足转红黑树阈值,如果满足就转成红黑树
- 返回 oldValue
get() 方法流程
6. 计算hash值
7. 找到对应位置,不同情况做不同处理, 直接取值/红黑树里找/遍历链表取值
8. 返回找到的结果