�����ġ�Kingma D , Ba J . Adam: A Method for Stochastic Optimization[J]. Computer ence, 2014.��pdf��
�����״������ Adam �㷨��������һ����������ݶ��½��㷨
Adam �Ƕ� SGD��AdaGrad �� RMSProp �㷨���Ż�
Adam ��� AdaGrad �� RMSProp �����㷨���ŵ㣬���ݶȵ�һ�ع��ƺͶ��ع��ƶ������ۺϿ��ǣ������㷨����

�㷨���̣�
- ���� ttt ʱ��Ŀ�꺯���� ��\theta�� ���ݶ�
- �����ݶȵ�һ�أ���ǰ���ݶ��뵱ǰ�ݶȵ�ƽ��
- �����ݶȵĶ��أ���ǰ���ݶ��뵱ǰ�ݶ�ƽ����ƽ��
- ��һ�� mtm_tmt? ����У������Ϊ m0m_0m0? ��ʼ��Ϊ 000���ᵼ�� mtm_tmt? ƫ���� 000
- �Զ��� vtv_tvt? ����У������Ϊ v0v_0v0? ��ʼ��Ϊ 000���ᵼ�� vtv_tvt? ƫ���� 000
- ���²��� ��t\theta_t��t?��ע���ʱ�ɽ� ��v^t+?\frac{\alpha}{\sqrt{\hat v_t}+\epsilon}v^t??+?��? ��Ϊ���²��� ��t\theta_t��t? ��ѧϰ�ʣ�m^t\hat m_tm^t? ��Ϊ���²��� ��t\theta_t��t? ���ݶ�
ע�������㷨����ͨ���ı����˳������Ч�ʣ���ѭ��������������Ϊ����������
��t=��?1?��2t/(1?��1t)��t����t?1?��t?mt/(vt+?^)\alpha_t=\alpha\cdot\sqrt{1-\beta_2^t}/(1-\beta_1^t) \\ \theta_t\leftarrow\theta_{t-1}-\alpha_t\cdot m_t / (\sqrt{v_t}+\hat\epsilon)��t?=��?1?��2t??/(1?��1t?)��t?����t?1??��t??mt?/(vt??+?^)
����ʵ��
# ADAM
# �� y=x1+2*x2��
import math
import numpy as npdef adam():# ѵ������ÿ����������������x = np.array([(1, 1), (1, 2), (2, 2), (3, 1), (1, 3), (2, 4), (2, 3), (3,3)])y = np.array([3, 5, 6, 5, 7, 10, 8, 9])# ��ʼ��m, dim = x.shapetheta = np.zeros(dim) # ����alpha = 0.01 # ѧϰ��momentum = 0.1 # ����threshold = 0.0001 # ֹͣ�����Ĵ�����ֵiterations = 3000 # ��������error = 0 # ��ʼ����Ϊ0b1 = 0.9 # �㷨���߽����Ĭ��ֵb2 = 0.999 # �㷨���߽����Ĭ��ֵe = 0.00000001 #�㷨���߽����Ĭ��ֵmt = np.zeros(dim)vt = np.zeros(dim)for i in range(iterations):j = i % merror = 1 / (2 * m) * np.dot((np.dot(x, theta) - y).T,(np.dot(x, theta) - y))if abs(error) <= threshold:breakgradient = x[j] * (np.dot(x[j], theta) - y[j])mt = b1 * mt + (1 - b1) * gradientvt = b2 * vt + (1 - b2) * (gradient**2)mtt = mt / (1 - (b1**(i + 1)))vtt = vt / (1 - (b2**(i + 1)))vtt_sqrt = np.array([math.sqrt(vtt[0]),math.sqrt(vtt[1])]) # ��Ϊֻ�ܶԱ������п���theta = theta - alpha * mtt / (vtt_sqrt + e)print('����������%d' % (i + 1), 'theta��', theta, 'error��%f' % error)if __name__ == '__main__':adam()
mtm_tmt? �� vtv_tvt? ��ƫ������
���Խ� vt=��2?vt?1+(1?��2)?gt2v_t=\beta_2\cdot v_{t-1}+(1-\beta_2)\cdot g_t^2vt?=��2??vt?1?+(1?��2?)?gt2? ��дΪ����ʱ�䲽��ֻ�����ݶȺ�˥���ʵĺ������� vt=(1?��2)��i=1t��2t?i?gi2v_t=(1-\beta_2)\sum^t_{i=1}\beta_2^{t-i}\cdot g_i^2vt?=(1?��2?)i=1��t?��2t?i??gi2?
������������ѧ���ɷ���֤��һ��

����֪���ݶȵ���ʵһ��Ϊ E(gt)E(g_t)E(gt?)����ʵ�Ķ���Ϊ E(gt2)E(g_t^2)E(gt2?)�����ڣ�����ϣ��֪������ʱ�䲽 ttt ��ָ���ƶ���ֵ������ E(vt)E(v_t)E(vt?) ����ʵ�Ķ��� E(gt2)E(g_t^2)E(gt2?) ֮��IJ��죬�����źö���������֮���ƫ���������

���ǿ��Լ�ͨ���������ģ�⿴һ�³�ʼֵ��Ӱ��
import numpy as np
import matplotlib.pyplot as pltbeta = 0.9
num_samples = 100np.random.seed(0)
raw_data = np.random.randint(32, 38, size = num_samples)
x_index = np.arange(num_samples)v_ema = []
v_pre = 0
for i, t in enumerate(raw_data):v_t = beta * v_pre + (1 - beta) * tv_ema.append(v_t)v_pre = v_tv_ema_corr = []for i, t in enumerate(v_ema):v_ema_corr.append(t / (1 - np.power(beta, i + 1)))plt.plot(x_index, raw_data, label='raw_data') # Plot some data on the (implicit) axes.
plt.plot(x_index, v_ema, label='v_ema') # etc.
plt.plot(x_index, v_ema_corr, label='v_ema_corr')
plt.xlabel('time')
plt.ylabel('T')
plt.title("exponential moving average")
plt.legend()
plt.savefig('./ema.png')
plt.show()

���Կ���������������ָ���ƶ�ƽ��ֵ�ڳ�ʼ�νεĽ������ʵ�������кܴ��ƫ���������ƫ�����Ų��������ӻ�Խ��ԽС����Ȼ������������ָ���ƶ�ƽ��ֵ�ڿ�ʼ�Ϳ��Ժܺõĸ�����ʵ�仯����
һ�ء�����
��ǰ���֪��һ�� E(gt)E(g_t)E(gt?) ����ǰ�ݶ� gtg_tgt? ������������һ�� mtm_tmt?�������ڵ�ǰ�ݶ� gtg_tgt? ����������õ��Ĺ��ƽ������˸���ע����ͳ�������ϵ�����
���� E(gt2)E(g_t^2)E(gt2?) ����ǰ�ݶȵ�ƽ�� gt2g_t^2gt2? �����������ƶ��أ���������������Ҫ�����������
- �� vtv_tvt? �ܴ��� �O�Omt�O�O||m_t||�O�Omt?�O�O �ܴ�ʱ��˵���ݶȴ����ȶ���vtv_tvt? ���ݶ�ƽ����ָ���ƶ���ֵ��Ȼ���Ϊ������ vtv_tvt? �ܴ�˵�������ֵ��ݶ��뵱ǰ�ݶȵľ���ֵ������̫С���O�Omt�O�O||m_t||�O�Omt?�O�O ָ���ǵ�ǰ�ݶ�ָ���ƶ���ֵ�ľ���ֵ���� �O�Omt�O�O||m_t||�O�Omt?�O�O �ܴ���˵�������ݶ��뵱ǰ�ݶ����������ĺ��٣��������ݶ��뵱ǰ�ݶ�һ����ͬ�š��������ݶȸ�������ȶ�������ƽ�������Կ����ݶ��½���**���ߴ����¡�**���ݶ��½�������ȷ
- �� vtv_tvt? �ܴ�� �O�Omt�O�O||m_t||�O�Omt?�O�O ȴ��Сʱ����˵�������Ĵ��ݶȺ͵�ǰ�ݶȵľ���ֵ���ܴ��dz����˺ܶ�������������������ʱ���ݶȸ���**��������״̬��**��һ�������һ������������� gt2g_t^2gt2? ��ָ���ƶ���ֵ�ܴ�˵�������ݶȵľ���ֵ�ܴ��������¸��µ�һ���ֲ��IJ��ȣ��н���һ������
- �� �O�Omt�O�O||m_t||�O�Omt?�O�O ���� vtv_tvt? ȴ�����㣬������������ܻ����
- �� �O�Omt�O�O||m_t||�O�Omt?�O�O �������� vtv_tvt? Ҳ������ʱ�������ܴﵽ�ֲ���͵㣬Ҳ�����ߵ�һ������ƽ���ĵط������˴�Ҫ��������ƽԭ
�ݶȸ���
Adam ���¹����һ����Ҫ����ʱ�䲽���Ľ���ѡ���� ?=0\epsilon=0?=0��ʱ�䲽 ttt �²����ռ��е���Ч������ ��t=��?m^t/v^t\Delta_t=\alpha\cdot\hat m_t/\sqrt{\hat v_t}��t?=��?m^t?/v^t??
�����Ч������������ȷ���Ͻ磺
- �� (1?��1)>1?��2(1-\beta_1)>\sqrt{1-\beta_2}(1?��1?)>1?��2?? ������£���Ч��������ȷ������ �O��t�O?��?(1?��1)/1?��2|\Delta_t|\leqslant\alpha\cdot(1-\beta_1)/\sqrt{1-\beta_2}�O��t?�O?��?(1?��1?)/1?��2??
- ����������� �O��t�O<��|\Delta_t|<\alpha�O��t?�O<��
��һ�����ֻ���ڼ�ϡ�������²Żᷢ�������ݶȳ��˵�ǰʱ�䲽��Ϊ 0������ʱ�䲽���ݶȶ�Ϊ 0�����ڲ���ôϡ�������£���Ч�������ø�С
�� (1?��1)=1?��2(1-\beta_1)=\sqrt{1-\beta_2}(1?��1?)=1?��2?? ʱ�������� �Om^t/v^t�O<1|\hat m_t/\hat v_t|<1�Om^t?/v^t?�O<1����ʱ���ǿ���ȷ������ȷ�� �O���O<��|\Delta|<\alpha�O���O<��
�ڸ�ͨ�õij����У���Ϊ �OE(g)/g2�O?1|E(g)/\sqrt{g^2}|\leqslant1�OE(g)/g2?�O?1�������� m^t/v^t�֡�1\hat m_t/\sqrt{\hat v_t}\approx \pm1m^t?/v^t??����1������ÿһ��ʱ�䲽����Ч�����ڲ����ռ��е��������������ڲ������� ��\alpha���� �� �O��t�O<��or�O��t�O�֦�|\Delta_t|<\alpha\ or\ |\Delta_t| \approx\alpha�O��t?�O<�� or �O��t?�O���������������Ϊ�ڵ�ǰ����ֵ��ȷ����һ�����������䣬��������������ṩ��һЩ��ǰ�ݶȹ���û���ṩ����Ϣ�����ǣ�ͨ����ͨ���������ǰ֪����ȷ�� ��\alpha�� ȡֵ���ұ߽�
���ڶ�������ѧϰģ����˵������֪���õ�����״̬���ڲ����ռ��ڵļ����������ż��ߵĸ��ʣ����磬���ǿ����ڲ�������һ������ֲ�����\alpha�� ȷ���˲����ռ�����Ч��������ȷ�磬ͨ��Ҳ�Ϳ����ƶϳ� ��\alpha�� ����ȷ�����������Ž�Ҳ���Դ� ��0\theta_0��0? ��ʼͨ��һ�������ĵ������������ȷ������
���ǽ� m^t/v^t\hat m_t/\hat v_tm^t?/v^t? ��������ȣ�SNR������� SNR ֵ��С����ô��Ч���� ��t\Delta_t��t? ���ӽ��� 0��Ŀ�꺯��Ҳ����������ֵ������ʮ����������ģ���ΪԽС�� SNR ��ζ�ž��ж� m^t\hat m_tm^t? �ķ����Ƿ������ʵ�ݶȷ������������Խ��IJ�ȷ���ԡ����磬SNR ֵ�����Ž⸽��ͨ���������� 0����ͬʱҲ�������ڲ����ռ���ʹ�ø�С����Ч��������������һ���Զ��˻�Ļ���
���ڲ�ͬ���ݶȷ�Χ��˵����Ч���� ��t\Delta_t��t? �Dz���ģ�������ݶ� ggg ����һ��ϵ�� ccc �������ţ���ô m^t\hat m_tm^t? ҲҪ����һ��һ����ϵ������ ccc���� v^t\hat v_tv^t? �����ϵ�� c2c^2c2�������յĽ�����������仯 (c?m^t)/(c2?v^t)=m^t/v^t(c\cdot\hat m_t)/(\sqrt{c^2\cdot\hat v_t})=\hat m_t/\sqrt{\hat v_t}(c?m^t?)/(c2?v^t??)=m^t?/v^t??
Adam �㷨���ŵ�
- ���Ա���
Adam ��¼���ݶȵ�һ�أ��������ݶ��뵱ǰ�ݶȵ�ָ���ƶ�ƽ��ֵ���ǵ�ÿһ�θ���ʱ����һ�θ��µ��ݶ��뵱ǰ���µ��ݶȲ������̫���ݶ�ƽ�����ȶ��Ĺ��ȣ�������Ӧ���ȶ���Ŀ�꺯�� - ������֪��
Adam ��¼���ݶȵĶ��أ��������ݶ���ƽ���뵱ǰ�ݶ�ƽ����ƽ����Ϊ��ͬ������������Ӧ��ѧϰ���� - ����������
������1����2��?\alpha��\beta_1��\beta_2��\epsilon������1?����2?��? �������õĽ����ԣ���ͨ��������������������ٵĵ���
AdaMax
ǰ�������� vt=(1?��2)��i=1t��2t?i?gi2v_t=(1-\beta_2)\sum^t_{i=1}\beta_2^{t-i}\cdot g_i^2vt?=(1?��2?)i=1��t?��2t?i??gi2?������Կ���һ������ gig_igi? �� L2L^2L2 ���������仰˵��Ȩ�� ��t\theta_t��t? �ĸ�ά���ϵ������Ǹ��ݸ�ά���ϵ�ǰ�����ݶȵ� L2L^2L2 ���������ǿ��Դ� L2L^2L2 ��ʽ�ĸ��¹����ƹ㵽 LpL^pLp �����ĸ��¹����� ppp ֵԽ���ƹ��㷨����ֵ�Ͻ���ò��ȶ����������У������� p����p\rightarrow\inftyp���� ���Եĵõ�һ�������ȶ��Ҽ��㷨
�� LpL^pLp ����������£�vt=(1?��2p)��i=1t��2p(t?i)?�Ogi�Opv_t=(1-\beta_2^p)\sum^t_{i=1}\beta_2^{p(t-i)}\cdot| g_i|^pvt?=(1?��2p?)i=1��t?��2p(t?i)??�Ogi?�Op

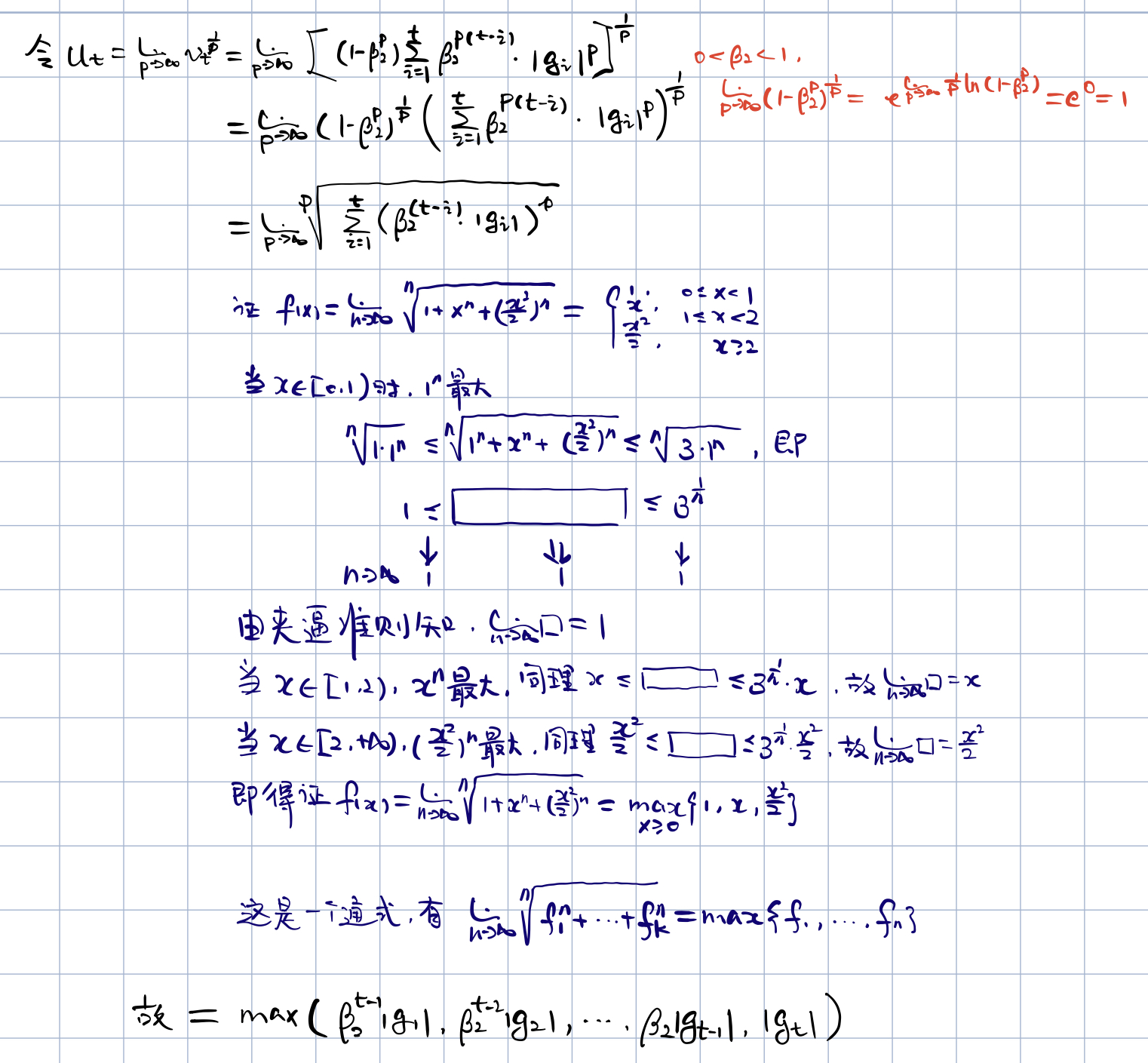
���ǣ����Ǿ͵õ����㷨 2 ����Ĺ�ʽ ut=max(��2?ut?1,�Ogt�O)u_t=max(\beta_2\cdot u_{t-1}, |g_t|)ut?=max(��2??ut?1?,�Ogt?�O)����ʼ��ʱ u0=0u_0=0u0?=0
���㷨 2 �������Dz���Ҫ�Գ�ʼ��ƫ������������ͬʱ���������µķ�ΧҲ��һ�����Ӽ��Ľ��ޣ��O��t�O?��|\Delta_t|\leqslant\alpha�O��t?�O?��