ФПТМ
pandasЕФЛљДЁгУЗЈЃК
pandas бЁдёЪ§Он
pandasЕФЛљДЁгУЗЈЃК
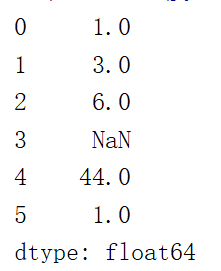
| s = pd.Series([1,3,6,np.NaN,44,1]) print(s) |
 |
dates = pd.date_range('20181203',periods=6)
print(dates) |
 |
dates = pd.date_range('20181203',periods=7)
date_df = pd.DataFrame(np.random.randn(7,4),index=dates,columns=['a','b','c','d'])
print(date_df) |
 |
df1 = pd.DataFrame(np.arange(12).reshape(3,4)) print(df1) |
 |
df = pd.DataFrame({'A':1,'B':[1,2,3],'C':'hello'})
print(df)
|
 |
df = pd.DataFrame({'A':1,'B':[1,2,3],'C':'hello'})
print(df.dtypes)
print(df.index)
print(df.columns)
print(df.values) |
 |
df = pd.DataFrame({'A':1,'B':[1,2,3],'C':'hello'})
print(df)
df = df.sort_index(axis=1,ascending=False)
print(df) |
 |
df = pd.DataFrame({'A':1,'B':[1,2,3],'C':'hello'})
print(df)
df = df.sort_values(by='B',ascending=False)
print(df) |
 |
pandas бЁдёЪ§Он
dates = pd.date_range('20180101',periods=6)
print(dates)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
print(df) |
 |
#АДСабЁдёдЊЫи print(df.A,df['A']) |
 |
| #АДаабЁдёдЊЫи print(df[0:3],df['20180103':'20180105']) |
 |
#АДееlable бЁдёдЊЫи,МШПЩвдАДееindexгжПЩвдАДееСаЪєад print(df.loc['20180102']) print(df.loc[:,['B']]) |
 |
#select by position print(df.iloc[1]) print(df.iloc[:,1]) print(df.iloc[1:3,1:3]) |
 |
#mixed selection,МШПЩвдАДееБъЧЉЃЌгжПЩвдАДееposition print(df.ix[:,'B']) |
 |
#boolean indexing print(df.A>8) print(df[df.A>8]) print(df.loc[df.A>8]) |
 |
pandas ЩшжУжЕКЭДІРэЖЊЪЇжЕ
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df.A[df.A>12] = 5
print(df) |
 |
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df[df.A>12] = 5
print(df) |
 |
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df.iloc[0,1] = np.NaN
df.iloc[1,2] = np.NaN
print(df)
#АДааЖЊЕєЃЌhow={'any','all'} 'all' ЮЊжЛгаИУааШЋВПЮЊnanВХЖЊЕєИУаа
print(df.dropna(axis=0,how='any')) |
 |
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df.iloc[0,1] = np.NaN
df.iloc[1,2] = np.NaN
print(df)
col_mean = df.mean()
#mean ЮЊЃКИУСаЕФКЭ/ИУСаВЛЮЊnanЕФзмЪ§
print(col_mean)
print(df.fillna(value=col_mean))
|
 |
print(np.any(df.isnull())==True) |
ШчЙћdf РяУцУЛгаNANжЕСЫЃЌЪфГіЮЊfalseЃЌжЛвЊгавЛИіNAN,ЪфГіОЭЪЧTrue |
| df дкfillna КѓвЛЖЈвЊжиаТИГжЕ df = df.fillna(value=col_mean) |
|