因为
P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)
所以得到贝叶斯公式:
给定事件B的基础上,计算A发生的概率:
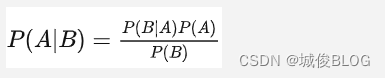
术语(真能造):
- P(A|B)称为后验概率(posterior),这是我们需要结合先验概率和证据计算之后才能知道的。
- P(B|A)称为似然(likelihood),在事件A发生的情况下,事件B(或evidence)的概率有多大
- P(A)称为先验概率(prior), 事件A发生的概率有多大
- P(B)称为证据(evidence),即无论事件如何,事件B(或evidence)的可能性有多大
1,贝叶斯统计的关键特点:人们根据新的观测改变了对一个事件发生概率的信念(belief)
举例:
假设某天太阳没有升起,那么你很有可能觉得第二天太阳也不会升起。但如果第二天太阳又正常升起了,你对太阳会再次罢工的概率预期也会比之前高很多。这就是基于对事件的观测改变了自己对事件发生概率的信念。
大体的过程是:前期我们认为的一个事件发生的概率(先验概率,事件还未发生)-》新的观测-》我们更新了自己认为的这个事件发生的概率(更新之后的概率叫后验概率,事件已经发生)
回到例子:
观测太阳-》太阳升起-》对太阳第二天还会升起更确定了一点-》观测太阳-》太阳升起-》对太阳第二天还会升起又更确定了一点。。。-》观测太阳-》太阳不升起了(new evidence)-》对太阳第二天还会升起没那么确定了(后验概率受到大幅影响)
================================================================================================
2,什么是似然(likelihood)
似然不是概率,但是与概率成正比。
在给定一些数据D的情况下,一个假设H的似然正比于给定H为真的情况下观察到D的概率,乘以一个任意正常数K。即:
L(H|D)=P(D|H)* K。似然不是概率,所以不遵守概率的各种规则,例如加和不为1。
似然和概率的最大不同是:各自的可变部分和不可变部分不同。在概率P(D|H)中假设H固定,数据D可变。似然正好相反,数据给定,假设可变。
似然定律(Edwards (1992, p. 30) ):在统计模型的框架内,基于一个特定的数据集合D,如果一个统计假设H1的似然大于另一个假设H2的似然,则认为这个数据集合更支持前一个统计假设。
也就是说,在假设H1条件下数据D的概率大于假设H2条件下数据D的概率,也就是说如果P(D|H1)>P(D|H2),则数据D是H1优于H2的证据。如果两个概率相等,则没有证据表明一个假设优于另一个。
另外,假设H1优于H2的统计证据强度通过似然的比率(似然比)来量化,即L(H1|D)/L(H2|D)。(同样正比于P(D|H1)/P(D|H2))
似然原则:似然函数包含与统计证据评估相关的所有信息。其他与评估统计证据强度无关的部分数据,在似然函数中不考虑。它们可能对规划研究或决策分析有意义,但与统计证据强度是分开的。
和概率不同,由于任意常数的存在,似然本身没有实际意义。只有对似然进行比较时才变得可解释(因为这时候常数抵消了)。以二项分布为例解释最简单:
抛硬币10次,6正4反,如果硬币材质均匀,正面朝上概率应该为0.5,用二项分布定义硬币正面朝上的概率:
这个公式计算的是抛硬币n次,正面朝上出现x次的概率。每次正面朝上的概率为p。
所以正面朝上6次的概率计算为约等于0.21;
如果硬币有问题,比如它正面朝上的概率为0.75,则6正4反的概率为约等于0.15;
为了量化假设H1对比假设H2的统计证据,将概率相除,得到的比率就是数据对两个假设的支持度的比较。在(数据为)6正4反的情况下,正常硬币 vs 异常硬币的似然率为0.21/0.15约等于1.4。也就是说,这个数据(6正4反)在正常硬币假设情况下出现的可能性是异常硬币假设下出现可能性的1.4倍。注意到计算时前面的分数部分二者相同,在计算似然率时抵消。
原因是:相同的数据,相同的常数,抵消。
分数部分包含了从10次抛硬币中得到6正的细节过程,如果改变这个过程(如改变采样方式),这会改变这部分的值,但因为在求似然率时分子分母都相同,所以总是抵消。也就是说,包含数据获取方式的信息从函数中消失了。因此,停止规则与统计证据评估无关,这就使得贝叶斯和似然方法具有价值和灵活性。
单个似然的值没有意义,只有对似然进行比较时才有意义。
======================================================================================
多个似然值
似然值可能看起来非常有使用限制,因为一个似然率只能比较两个似然值。但如果我们想要同时比较多个假设怎么办?如果想要一次性比较所有可能的假设呢?
这种情况下可以画出基于数据的似然曲线,然后整体去“看”统计证据。通过画出整体似然函数的曲线,可以同时比较所有可能的假设。似然原则表明似然函数包含了我们的数据可以提供的所有统计证据,所以我们应该经常将似然函数和计算得到的似然率一起绘制出来。
根据Birnbaum (1962),实验结果的证据意义完全由似然函数表征。
以下是抛10次硬币出现6正的似然函数,似然曲线上蓝色的点标记的是两个假设。由于似然函数只有在任意常数下才有意义,图上已经按照惯例进行了缩放,最佳支持值(最大值)对应的似然值是1。

垂直虚线指示的是数据支持的最佳假设。任何两个假设对应的似然率就是它们在曲线上对应高度的比值。从图中可以看出正常硬币的似然值比异常硬币要大。
如果抛掷100次,获得60正,曲线怎么变化?
曲线变得更窄!正常硬币的证据强度对比异常硬币怎么变化?新的似然率为

==================================================================================
贝叶斯因子
贝叶斯因子是似然率的简单扩展。贝叶斯因子是基于假设的先验分布的似然率的加权平均。当假设是简单点估计的时候,贝叶斯因子等于似然率。