0x00 ǰ��
ʹ��API���ԺܼĻ�ȡ����Ҫ�����ݣ��������ڹ���API������Ƚ����ѣ���������ƹ�APIֱ��������һ��������Ҫ��������⡣Github�ϵĵ���ղ����ߵIJ��������涼�Ѿ���twitter�����
��������İ汾���ʼд����ʱ���ֵ�һ���汾������ʵ�ֵıȽϴֲ�
0x01 �������
ʵ���˸����û�ID��ÿ���Զ���ȡ�û����ģ��൱�ڼ��ӣ�����������൱������Ը����Լ���������и��ģ�����ͷ���һ�´��롣
- �ô���Ϊͨ��
screen name��ȡ���ģ�������ͨ��screen name��ȡ��id����ȡ����id���ճ��бȽ���Ѱ�������������ͨ��screen name������ȡ��Ҳ�����и���Ϊʹ��id��ȡ
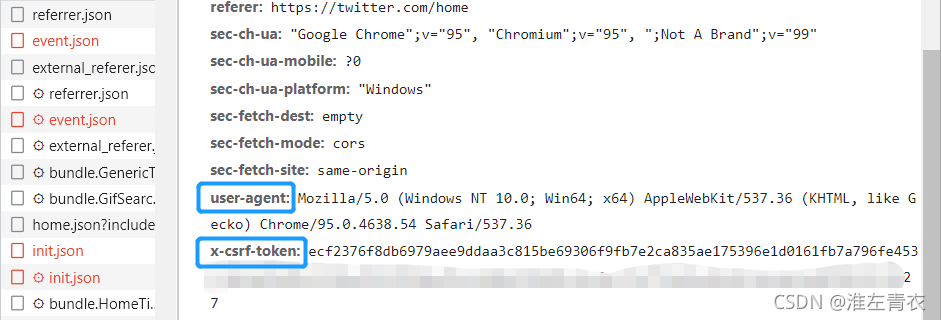
headers�в������ҷ�������twitter�û����� ��F12,�ٰ�F5ˢ��

0x03 �������
# -*- codeing =utf-8 -*-
# @Time : 2020/10/21 16:43
# @Author:yuchuan
# @File : crawl_tweets_by_id.py
# @Software : PyCharm
import requests
import json
import urllib.parse
import csv
import pandas as pd
from itertools import chain
import numpy as np
from datetime import datetime, timedelta
import time
import calendar
#getuserID��ͨ��user screenname��ȡID�������˹�ȥ��ȡ
def main():#��װheader��αװ���������#*******************Ϊ��Ҫ�滻����headers = {
"cookie": '*******************',"user-agent": "*******************","x-csrf-token": "*******************","authorization": "*******************",}#Ҳ��ֱ�ӻ�ȡid ��ȡusername = pd.read_csv('*******************.csv')for i in range(0, len(username['username'])):print(str(username['username'][i]))csv_username=str(username['username'][i])userID=getuserID(csv_username,headers)twitterURL = "https://twitter.com/i/api/2/timeline/profile/" + userID + ".json?include_profile_interstitial_type=1&include_blocking=1&include_blocked_by=1&include_followed_by=1&include_want_retweets=1&include_mute_edge=1&include_can_dm=1&include_can_media_tag=1&skip_status=1&cards_platform=Web-12&include_cards=1&include_ext_alt_text=true&include_quote_count=true&include_reply_count=1&tweet_mode=extended&include_entities=true&include_user_entities=true&include_ext_media_color=true&include_ext_media_availability=true&send_error_codes=true&simple_quoted_tweet=true&include_tweet_replies=false&count=20&userId=" + userID + "&ext=mediaStats%2ChighlightedLabel"flag=Truecontent = []full_content=[]response = connect(headers, twitterURL)#flag �൱��ȷ����ȡ���������Ƿ��ڵ����flag = false ֹͣ��ȡwhile (flag):# ��������response = connect(headers, twitterURL)# formatRes��Դ�������responseJson = formatRes(response.content)# ��ȡÿ��json�� ���������Լ�ʱ�䣬ת�ƣ�����content = parsetweets(responseJson)# ��ÿ��json�е��������ӵ�һ���б���full_content.extend(content)#��ȡ��һҳ���ĵ�json��twitterURL = getNewURL(responseJson,userID)flag=CtrlFlag(content)# n = n - 1print("------------------------------------------------------------------------------------------------\n------------------------------------------------------------------------------------------------")# ��ȡֻҪ���������everydaytweet=todaytweet(full_content)# �����ݱ��浽CSV�У�ÿ���û�һ��CSVsaveData(everydaytweet, csv_username)time.sleep(30)# ��ȡ��������ģ������뷨��ֱ����CSV�н�������Ȼ���ȡ�������ġ�ʱ������û�ɹ�����������ֱ�����б��н�ȡ��������ģ��ٱ�����CSV�ļ��п��ԡ�
def CtrlFlag(content):flag=Truetime = (todaytime() + timedelta(hours=-8)).strftime("%Y-%m-%d")count=0for i in range(0,len(content)):if content[i][0][0:10] not in str(time):count=count+1if count==len(content):flag=Falsereturn flag
def getuserID(username,headers):connectURL = "https://twitter.com/i/api/graphql/jMaTS-_Ea8vh9rpKggJbCQ/UserByScreenName?variables=%7B%22screen_name%22%3A%22" + username + "%22%2C%22withHighlightedLabel%22%3Atrue%7D"print(connectURL)response=connect(headers,connectURL)responseJson= formatRes(response.content)# print(responseJson)data=responseJson['data']['user']# print(data)userID=find('rest_id',data)return userIDdef todaytweet(full_content):content=[]#todaytime�����ʱ�䣬-8���UTCʱ�䣬����ȡ��created_atʱ��ͳһtime=(todaytime()+ timedelta(hours=-8)).strftime("%Y-%m-%d")for i in range(0,len(full_content)):if full_content[i][0][0:10] in str(time):content.append(full_content[i])return content# ��ȡ���ģ���ʱ��ȣ���ʱ����и�ʽ��****/**/**
def parsetweets(dict):dict = dict['globalObjects']['tweets']full_text=findAll('full_text',dict)created_at=findAll('created_at',dict)favorite_count=findAll('favorite_count',dict)quote_count=findAll('quote_count',dict)reply_count=findAll('reply_count',dict)retweet_count=findAll('retweet_count',dict)formatcreated_at=[]time1=[]time2=[]utc_time1=[]for i in range(0,len(created_at)):#��twitter��������ʱ����UTCʱ�䣬ͳһΪUTCʱ�䣬������ʱ�䣨��ۣ�-8Сʱ������ʱ��+5Сʱtime1.append(datetime.strptime(created_at[i],"%a %b %d %H:%M:%S +0000 %Y"))time2.append(datetime.strftime(time1[i],'%Y-%m-%d %H:%M:%S')) #datatimeתstrtweetData = []#tweetData = list(chain.from_iterable(zip( created_at,full_text))) # �ϲ������б�# print(tweetData)for i in range(0,len(full_text)):tweetData.append([time2[i],full_text[i],favorite_count[i],quote_count[i],reply_count[i],retweet_count[i]])return tweetData# ��ǰ���� 20201029��ʽ����ʱʱ��type��datetime,���ÿ�����Ҫת����str
def todaytime():today=datetime.today()return today#���浽CSV��,ÿ���˱�����һ��CSV�ļ��С�
def saveData(content,filename):filetime = todaytime().strftime('%y%y%m%d')filename=filetime+" "+filenamefilepath = 'D:/twitterdata/'+filename+'.csv'name=['Time', 'Tweet','Favorite','Quote','Reply','Retweet']Data=pd.DataFrame(columns=name,data=content)Data.to_csv(filepath,encoding='utf-8-sig')# ֱ�Ӳ��Ҽ�ֵ find
def find(target, dictData, notFound='û�ҵ�'):queue = [dictData]while len(queue) > 0:data = queue.pop()for key, value in data.items():if key == target: return valueelif type(value) == dict: queue.append(value)return notFound
def findAll(target, dictData, notFound=[]):#print(dictData)result = []for key, values in dictData.items():content = values[target]result.append(content)#print(result)return result# ��ȡ��cursor��������µ�url
def getNewURL(responseJson,userID):responseJsonCursor1 = responseJson['timeline']['instructions'][0]['addEntries']['entries'][-1]#�����ֵ䣬���б��е����һ��Ԫ��cursorASCII=find('cursor',responseJsonCursor1)cursorASCII2 = find('value', cursorASCII)cursor=urllib.parse.quote(cursorASCII2)newURL="https://twitter.com/i/api/2/timeline/profile/"+userID+".json?include_profile_interstitial_type=1&include_blocking=1&include_blocked_by=1&include_followed_by=1&include_want_retweets=1&include_mute_edge=1&include_can_dm=1&include_can_media_tag=1&skip_status=1&cards_platform=Web-12&include_cards=1&include_ext_alt_text=true&include_quote_count=true&include_reply_count=1&tweet_mode=extended&include_entities=true&include_user_entities=true&include_ext_media_color=true&include_ext_media_availability=true&send_error_codes=true&simple_quoted_tweet=true&include_tweet_replies=false&count=20&cursor="+cursor+"&userId="+userID+"&ext=mediaStats%2ChighlightedLabel"return newURL#��ʽ����ȡ����json//bytesתstring loads()��string�����ֵ���
def formatRes(res):strRes = str(res, 'utf-8')dictRes = json.loads(strRes)return dictRes#���ô���proxies�����ӻ�ȡ��ҳ���ݡ�����������Ҫ�Լ�����
def connect(headers,twitterURL):proxies = {
"http": "http://127.0.0.1:7890", "https": "http://127.0.0.1:7890", }response = requests.get(twitterURL,headers = headers, proxies=proxies)return responseif __name__=="__main__": #������ִ��ʱmain()
0x04 һЩ�л�
���˴�����һ�����ںţ���������·�ϵ�С���⣬�·��֣���ӭ��ע���ںţ��������ԣ�����
һ��ܷ����ϣ����������~~
