浅谈 Android MVVM 需要用 Flow 代替 LiveData 吗?
- 前言
- LiveData
- 为什么要用 Flow 代替 LiveData
- Flow 是什么?
- Flow 的操作符
-
-
- map() filter() zip()
- 背压操作
-
- Flow 如何代替 LiveData
- 最后
前言
Android开发:我刚学会的 LiveData 这么快就要被代替了?

先说结论:个人认为当前项目的架构正在使用 LiveData 并不需要完全用 Flow 代替,部分 LiveData 无法完美解决的场景,亦或是当 Flow 能有效解决实际开发中的问题时,可以接入 Flow 来更好的完成。
Flow 是协程的一部分,如果你的项目还在使用 Java语言开发那 LiveData 仍然是比较好的选择因为 协程需要 Kotlin 语言支持。
再高大上的框架,不能解决实际业务中的痛点也没必要强行整合,不是吗?
LiveData
2017年 Google 官方推出了 LiveData。如果让我来简单说说 LiveData 是什么,我只有一句话:LiveData 实现了变量可以被订阅,且数据更新发生在主线程(非常适合刷新UI界面)。当然,在 LiveData 出现之前,RxJava 可以完全胜任这项功能。LiveData 的推出简化了大部分简单场景的开发成本、学习成本,简单易用。复杂的场景:背压等等,还是需要使用 RxJava 来实现。
LiveData 推出的同时 Google 官方也推出了一系列的架构组件,比如 Lifecycle。结合 Lifecycle 组件 LiveData 可以感知 View 的生命周期从而非常简单的自动取消订阅,相比于 RxJava 省去了大量模版代码。但同时也比 RxJava 缺少了方便的操作符。
LiveData 对于MVVM来说,就是包装了 ViewModel 中的数据,使其可以被订阅,方便更新UI。LiveData 说他简单吧,他上手特别快,但是又很难完全代替 RxJava(甚至 RxJava 可以完全胜任 LiveData 的工作),所以 Flow 出现了。
为什么要用 Flow 代替 LiveData
首先我要说明,LiveData 并不是一个不好的组件,他只是不够强大,你用 LiveData 搭建响应式编程架构是可以的,但是会有一些场景需要注意:
- LiveData 的设计会缓存最后一次接受的 value,当有新订阅者时会触发一次 onChange 方法,Google 这么设计很大程度方便了 View 层重建的场景,当 Activity 旋转时我们无需重新调用 api 即可获取到屏幕旋转之前的最新数据,但是不是所有的场景都适合这样设计。想象这样一个场景:Ui中发送一个网络请求根据其返回结果弹窗,当用户竖屏进入且主动触发弹窗后关闭,LiveData 中仍然缓存着网络请求的结果,此时当用户旋转屏幕后,Activity 重建会重新订阅 LiveData,此时 LiveData 会再一次主动出发 onChange 方法导致重复显示弹窗。
- LiveData 的操作符不够强大,大多数场景我们从数据源取到的数据需要过滤等操作,Google 可从来没有想要用 LiveData 来实现,这可不是我瞎说,Google 在 19年的 AndroidDevSummit 分享上就提到了这样的场景。(视频链接,13分钟左右提到过)
综上所述,我们并不用着急从当前项目中摘除 LiveData,他仍然可以作为响应式编程的架构组件,只是更复杂的场景(数据处理,多个请求合并等等)使用 Flow 来实现更合适。
Flow 是什么?
Flow 是属于 Kotlin 协程中的一部分,和 RxJava 十分相似同样是响应式编程模型,同样可以切换线程,支持背压操作,拥有很多强大的操作符,配合 JetPack 系列组件使得 Flow 的上手相比于 RxJava 就容易多了。
一段代码就能让你认识到 Flow 和 RxJava 的相似:
val producer = flow {
println("我要开始生产了")for (i in 1..5) {
println("正在生产第 $i 个")emit(i)}
}
fun main() {
runBlocking {
producer.collect{
delay(2000)println("${Date()} 消费 : $it")}}
}
输出结果:
从这段代码可以很明显的看出,这是一个生产者消费者模式,和当初入坑 RxJava 的 Demo 如出一辙。同时根据打印的时间也能看出 Flow 是冷流,只有下游开始 collect 时才会运行,点进去 collect 的源码便可以看出:

collect 后面的代码块被当作参数传递给了 FlowCollector 的 emit 方法;我们在回过头看生产者 producer 的创建 flow {} ,点进去 flow {} 的源码:

flow{} 返回的是一个 SafeFlow,并且我们生产者的代码块被当作参数传递到了 SafeFlow 的构造方法中,当 SafeFlow 的 collectSafely 执行时会调用到我们所写的代码块 block,那么 collectSafely 何时才会被调用?
SafeFlow 时 AbstractFlow 的子类,AbstractFlow的源码如下:

从源码这么一看,绕了这么一圈,当 Flow 的 collect 调用时就会触发 caollectSafely,而 collectSafely 的实现就是调用我们所写的 block 代码块。回过头来总结下这段简单的代码:

由这部分的源码分析我们也可以看出来 Flow 是一个冷流。本质上 你调用了 collect 方法 你构建 flow{} 时的代码块才会被调用,emit 方法对应的就是下游处理代码块。
更多关于 Flow 的源码分析在此处不多做分析,后续随缘更新关于 Flow 的相关博客。
Flow 的操作符
了解了 Flow 是什么之后 就该看看他强大的操作符了,这里举例几个比较经典的操作符。
map() filter() zip()
flow {for (i in 1..5){emit(i)}
}.map { i ->i + 1
}.collect {Log.e("收集:", "$it")
}
输出结果:

map() filter() zip() 和 RxJava 中的操作是一模一样的,就不再赘述了重点看下背压。
背压操作
消费者模式中,上下游的速率不同时,当上游生产过快但消费者消费慢时,就会出现数据的积压。
首先看这样一段代码:
flow {for (i in 1..100){emit(i)}
}.collect {delay(2000)Log.e("${Date()}", "收集:$it")
}
输出结果:

其实并没有造成数据积压,因为 Flow 默认是冷流,通过上面的源码分析我们也可以得知,当调用 emit 时就是调用 collect 的代码块。
那么如何将 Flow 转换为 热流?shareIn() 方法
flow {for (i in 1..5){Log.e("Flow", "生产:$i")emit(i)}
}.shareIn(lifecycleScope, //协程作用域SharingStarted.Eagerly //共享方式 Eagerly 立即共享,Lazily 当有观察者时开始共享
).collect{delay(2000)Log.e("Flow", "收集:$it")
}
输出结果:

根据打印日志明显可以看出已经变更为 热流;
当上游生产大量数据 会发生什么情况?
将循环次数改变:
flow {for (i in 1..1000000){Log.e("Flow", "生产:$i")emit(i)}
}.shareIn(lifecycleScope,SharingStarted.Eagerly
).collect{delay(2000)Log.e("Flow", "收集:$it")
}
输出结果:

发现貌似是默认积压 64 个 然后消费一个生产一个。那么如何改变这种背压策略呢? buffer 操作符登场了:
看一下buffer源码
public fun <T> Flow<T>.buffer(capacity: Int = BUFFERED, onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND): Flow<T> {...
}
一共接受两个参数,第一个参数 capacity 是调整积压容量的,默认值 BUFFERED 我们点进去源码看一下:

源码里的注释很清楚的写着 默认容量 64,capacity 一共提供了四个值:

看完 capacity 再来看看第二个参数 onBufferOverflow,同样点进去源码查看:

利用 buffer 操作符可以很简单的调整 背压的策略,来测试一波:
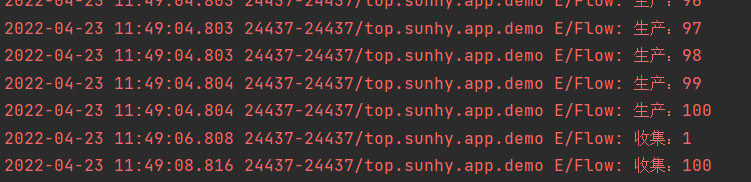
flow {for (i in 1..100){Log.e("Flow", "生产:$i")emit(i)}
}.buffer(onBufferOverflow = BufferOverflow.DROP_OLDEST //溢出时丢弃最旧的值
).collect{delay(2000)Log.e("Flow", "收集:$it")
}
Flow 如何代替 LiveData
想比于 LiveData ,Flow 欠缺了声明周期感知,那当界面不可见(切换页面,app进入后台等)仍然在订阅上游数据就造成了性能、电量等问题。Flow 如何感知生命周期呢?Flow是属于 Kotlin 协程的一部分,Google 为了让我们使用携程更顺手退出了一系列 KTX扩展库,Lifecycle 提供的一系列协程启动的方法就包括 lifecycleScope.launchWhenX:

那么有没有更好的办法?肯定有!Google 在 lifecycle-runtime-ktx:2.4.0 版本增加了 repeatOnLifecycle 方法可以让你的 Flow 感知生命周期。用法如下:
//在 Activity 中
override fun initObserver() {lifecycleScope.launch {repeatOnLifecycle(Lifecycle.State.RESUMED){producer.collect {println("消费 : $it")}}}
}
Flow 也提供了 asLiveData 方法将 Flow 转化为一个 LiveData
fun fetchData(): String{//耗时操作 比如 网络请求获取数据
}
private val _data = MutableLiveData<String>()
val data: LiveData<String> = _data
fun loadData(){viewModelScope.launch {//耗时操作_data.postValue(fetchData())}_data.value = "Live Data !"
}//这种写法 flowData 和 上面的 data 是一样的
private val _flowData = flow {emit(fetchData())
}
val flowData: LiveData<String> = _flowData.asLiveData()
最后
这篇博客主要对 Flow 进行了一点入门的了解,下篇博客讲用实战中的代码(Flow + Retrofit)搭建一套 MVVM 规范的网络请求模块。