Ŀ¼
һ��Skip-gram ģ�͵Ľṹ
1 ʲô��Word2Vec��Embeddings��
2 Word2Vecģ��
3 The Fake Task
4 ģ�͵ľ���ϸ��
5 ���ز�
6 �����
7 ����
����Skip-gram ģ�͵�ѵ��
1 Word pairs and "phases"
2 �Ը�Ƶ�ʳ���
3 ������
4 ��������negative sampling��
5 ���ѡ��negative words
6 ��������
����Skip-gram ģ�͵�ʵ��
1 ���˵��
2 ���߽���
3 ���IJ���
3.1 ����Ԥ����
3.2 ѵ����������
3.2.1 ����
3.2.2 ����batch
3.3 ģ����
3.3.1 ����㵽Ƕ���
3.3.2 Ƕ��㵽�����
3.4 ģ����֤
4 ��¼��
һ��Skip-gram ģ�͵Ľṹ
1 ʲô��Word2Vec��Embeddings��
Word2Vec�ǴӴ����ı����������ල�ķ�ʽѧϰ����֪ʶ��һ��ģ�ͣ�����������������Ȼ���Դ�����NLP���С���ô������ΰ�����������Ȼ���Դ����أ�Word2Vec��ʵ����ͨ��ѧϰ�ı����ô������ķ�ʽ�����ʵ�������Ϣ����ͨ��һ��Ƕ��ռ�ʹ�����������Ƶĵ����ڸÿռ��ھ���ܽ���Embedding��ʵ����һ��ӳ�䣬�����ʴ�ԭ�������Ŀռ�ӳ�䵽�µĶ�ά�ռ��У�Ҳ���ǰ�ԭ�ȴ����ڿռ�Ƕ�뵽һ���µĿռ���ȥ��
���Ǵ�ֱ�۽Ƕ���������һ�£�cat������ʺ�kitten���������Ϻ�����Ĵʣ���dog��kitten������ô�����iphone������ʺ�kitten������Ͳ�ĸ�Զ�ˡ�ͨ���Դʻ���е��ʽ���������ֵ��ʾ��ʽ��ѧϰ��Ҳ���ǽ�����ת��Ϊ�����������ܹ������ǻ�����������ֵ�����������IJ����Ӷ��õ�һЩ��Ȥ�Ľ��ۡ�����˵��������ǶԴ�����kitten��cat�Լ�dogִ�������IJ�����kitten - cat + dog����ô���յõ���Ƕ��������embedded vector������puppy���������ʮ�������
2 Word2Vecģ��
Word2Vecģ���У���Ҫ��Skip-Gram��CBOW����ģ�ͣ���ֱ�������⣬Skip-Gram�Ǹ���input word��Ԥ��������,��CBOW�Ǹ�����������Ԥ��input word����ƪ���½�����Skip-Gramģ�͡�
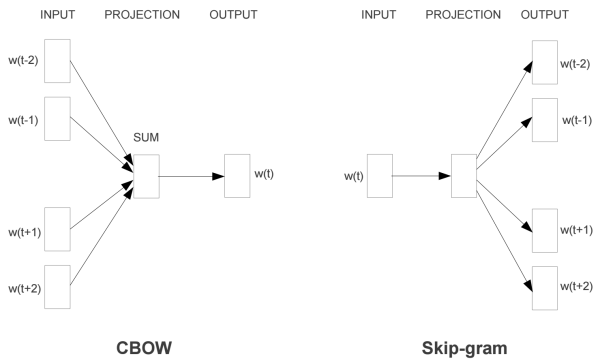
Skip-Gramģ�͵Ļ�����ʽ�dz���Ϊ�˸�����ؽ���ģ�ͣ������ȴ���һ��Ļ���ģ������Word2Vec�����������е�Word2Vec����ָSkip-Gramģ�ͣ���
Word2Vecģ��ʵ���Ϸ�Ϊ���������֣���һ����Ϊ����ģ�ͣ��ڶ�������ͨ��ģ�ͻ�ȡǶ���������Word2Vec��������ģ����ʵ�������Ա�������auto-encoder����˼������ƣ����Ȼ���ѵ�����ݹ���һ�������磬�����ģ��ѵ�����Ժ����Dz����������ѵ���õ�ģ�ʹ����µ���������������Ҫ�������ģ��ͨ��ѵ��������ѧ�õIJ��������������Ȩ�ؾ����������ǽ��ῴ����ЩȨ����Word2Vec��ʵ���Ͼ���������ͼȥѧϰ�ġ�word vectors��������ѵ�����ݽ�ģ�Ĺ��̣����Ǹ���һ�����ֽС�Fake Task������ζ�Ž�ģ�������������յ�Ŀ�ġ�
�����ᵽ�����ַ���ʵ���ϻ����ල����ѧϰ��unsupervised feature learning���м���������ľ����Ա�������auto-encoder����ͨ�������㽫������б���ѹ�����̶�������㽫���ݽ���ָ���ʼ״̬��ѵ����ɺ����ǻὫ����㡰�����������������㡣
3 The Fake Task
�����������ᵽ��ѵ��ģ�͵�����Ŀ���ǻ��ģ�ͻ���ѵ������ѧ�õ�����Ȩ�ء�Ϊ�˵õ���ЩȨ�أ���������Ҫ����һ����������������Ϊ���ǵġ�Fake Task���������ٷ�������ͨ����Fake Task��������μ�ӵصõ���Щ��������
�������������������ѵ�����ǵ������硣����������һ��������The dog barked at the mailman����
-
��������ѡ�����м��һ������Ϊ���ǵ�����ʣ���������ѡȡ��dog����Ϊinput word��
- ����input word�Ժ������ٶ���һ������skip_window�IJ����������������Ǵӵ�ǰinput word��һ�ࣨ����ұߣ�ѡȡ�ʵ������������������skip_window=2����ô�������ջ�ô����еĴʣ�����input word���ڣ�����['The', 'dog'��'barked', 'at']��skip_window=2������ѡȡ��input word���2���ʺ��Ҳ�2���ʽ������ǵĴ��ڣ������������ڴ�Сspan=2x2=4����һ��������num_skips�������������Ǵ�����������ѡȡ���ٸ���ͬ�Ĵ���Ϊ���ǵ�output word����skip_window=2��num_skips=2ʱ�����ǽ���õ����� (input word, output word) ��ʽ��ѵ�����ݣ��� ('dog', 'barked')��('dog', 'the').
-
�����������Щѵ�����ݽ������һ�����ʷֲ���������ʴ��������ǵĴʵ��е�ÿ������output word�Ŀ����ԡ���仰�е��ƣ��������������ӡ��ڶ���������������skip_window��num_skips=2������»��������ѵ�����ݡ�������������һ������ ('dog', 'barked') ��ѵ�������磬��ôģ��ͨ��ѧϰ���ѵ����������������Ǵʻ����ÿ�������ǡ�barked���ĸ��ʴ�С��
ģ�͵�������ʴ����ŵ����Ǵʵ���ÿ�����ж������Ը�input wordͬʱ���֡��ٸ����ӣ����������������ģ��������һ�����ʡ�Soviet������ô����ģ�͵���������У���Union���� ��Russia��������شʵĸ��ʽ�Զ������watermelon������kangaroo������شʵĸ��ʡ���Ϊ��Union������Russia�����ı��и�������ڡ�Soviet���Ĵ����г��֡����ǽ�ͨ���������������ı��гɶԵĵ�����ѵ�������������˵�ĸ��ʼ��㡣�����ͼ�и�����һЩ���ǵ�ѵ�����������ӡ�����ѡ��������The quick brown fox jumps over lazy dog�����趨���ǵĴ��ڴ�СΪ2��window_size=2����Ҳ����˵���ǽ�ѡ�����ǰ��������ʺ�����ʽ�����ϡ���ͼ�У���ɫ����input word�������ڴ���λ�ڴ����ڵĵ��ʡ�

���ǵ�ģ�ͽ����ÿ�Ե��ʳ��ֵĴ�����ϰ��ͳ�ƽ�������磬���ǵ���������ܻ�õ��������ƣ���Soviet������Union����������ѵ�������ԣ������ڣ���Soviet������Sasquatch�������������ȴ�����ĺ��١���ˣ������ǵ�ģ�����ѵ������һ�����ʡ�Soviet����Ϊ���룬����Ľ���С�Union�����ߡ�Russia��Ҫ�ȡ�Sasquatch����������ߵĸ��ʡ�
4 ģ�͵ľ���ϸ��
�����������ʾ��Щ�����أ����ȣ����Ƕ�֪��������ֻ�ܽ�����ֵ���룬���Dz����ܰ�һ�������ַ�����Ϊ���룬������ǵ�����취����ʾ��Щ���ʡ���õİ취���ǻ���ѵ���ĵ������������Լ��Ĵʻ����vocabulary���ٶԵ��ʽ���one-hot���롣
��������ǵ�ѵ���ĵ��г�ȡ��10000��Ψһ���ظ��ĵ�����ɴʻ�������Ƕ���10000�����ʽ���one-hot���룬�õ���ÿ�����ʶ���һ��10000ά������������ÿ��ά�ȵ�ֵֻ��0����1�����絥��ants�ڴʻ���еij���λ��Ϊ��3������ôants����������һ������ά��ȡֵΪ1������ά��Ϊ0��10000ά��������ants=[0, 0, 1, 0, ..., 0]����
������������ӣ���The dog barked at the mailman������ô���ǻ���������ӣ����Թ���һ����СΪ5�Ĵʻ�������Դ�Сд�ͱ����ţ���("the", "dog", "barked", "at", "mailman")�����Ƕ�����ʻ���ĵ��ʽ��б��0-4����ô��dog���Ϳ��Ա���ʾΪһ��5ά����[0, 1, 0, 0, 0]��
ģ�͵��������Ϊһ��10000ά����������ô���Ҳ��һ��10000ά�ȣ��ʻ���Ĵ�С������������������10000�����ʣ�ÿһ�����ʴ����ŵ�ǰ��������������output word�ĸ��ʴ�С��
��ͼ������������Ľṹ��
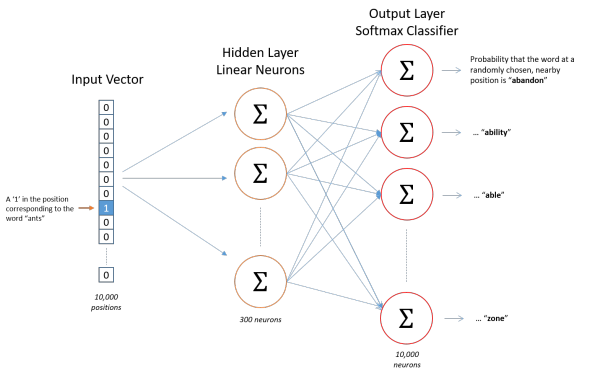
����û��ʹ���κμ���������������ʹ����sotfmax��
���ǻ��ڳɶԵĵ����������������ѵ����ѵ�������� ( input word, output word ) �����ĵ��ʶԣ�input word��output word����one-hot���������������ģ�͵������һ�����ʷֲ���
5 ���ز�
˵�굥�ʵı����ѵ��������ѡȡ���������������ǵ����㡣���������������300����������ʾһ�����ʣ���ÿ���ʿ��Ա���ʾΪ300ά������������ô�����Ȩ�ؾ���Ӧ��Ϊ10000�У�300�У�������300����㣩��
Google�����·����Ļ���Google news���ݼ�ѵ����ģ����ʹ�õľ���300�������Ĵ���������������ά����һ�����Ե��ڵij���������Python��gensim���з�װ��Word2Vec�ӿ�Ĭ�ϵĴ�������СΪ100�� window_sizeΪ5����
�������ͼƬ����������ͼ�ֱ�Ӳ�ͬ�Ƕȴ����������-�����Ȩ�ؾ�����ͼ��ÿһ�д���һ��10000ά�Ĵ����������㵥����Ԫ���ӵ�Ȩ�����������ұߵ�ͼ������ÿһ��ʵ���ϴ�����ÿ�����ʵĴ�������
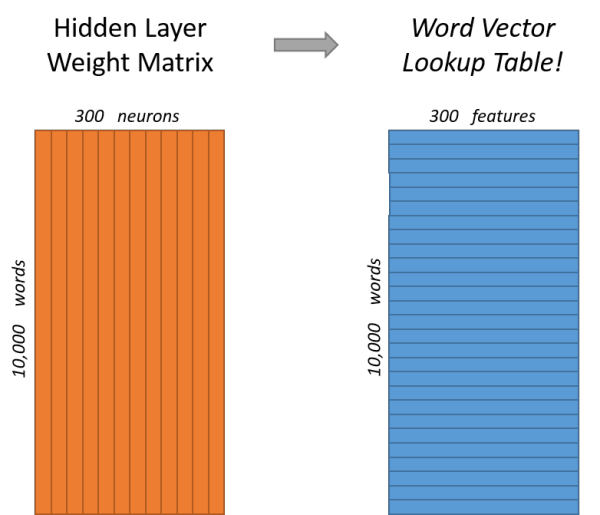
�����������յ�Ŀ�����ѧϰ��������Ȩ�ؾ���
�������ڻ�������ͨ��ģ�͵Ķ�����ѵ�����ǵ����ģ�͡�
���������ᵽ��input word��output word���ᱻ���ǽ���one-hot���롣��ϸ��һ�£����ǵ����뱻one-hot�����Ժ�����ά���϶���0��ʵ���Ͻ���һ��λ��Ϊ1����������������൱ϡ�裬��ô�����ʲô����ء�������ǽ�һ��1 x 10000��������10000 x 300�ľ�����ˣ����������൱��ļ�����Դ��Ϊ�˸�Ч���㣬��������ѡ������ж�Ӧ��������ά��ֵΪ1�������У���仰���ƣ�����ͼ�����ס�
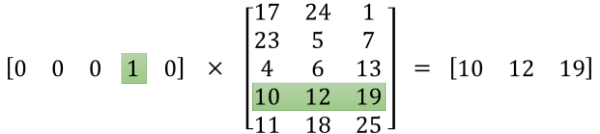
��������һ����ͼ�еľ������㣬��߷ֱ���1 x 5��5 x 3�ľ����Ӧ����1 x 3�ľ����վ���˷��Ĺ�����ĵ�һ�е�һ��Ԫ��Ϊ0 x 17 + 0 x 23 + 0 x 4 + 1 x 10 + 0 x 11 = 10��ͬ���ɵ���������Ԫ��Ϊ12��19�����10000��ά�ȵľ�����������ļ��㷽ʽ��ʮ�ֵ�Ч�ġ�
Ϊ����Ч�ؽ��м��㣬����ϡ��״̬�²�����о���˷����㣬���Կ�������ļ���Ľ��ʵ�����Ǿ����Ӧ��������ֵΪ1������������������У����������ȡֵΪ1�Ķ�Ӧά��Ϊ3���±��0��ʼ������ô���������Ǿ���ĵ�3�У��±��0��ʼ������ [10, 12, 19]������ģ���е�����Ȩ�ؾ�������һ�������ұ�����lookup table�������о������ʱ��ֱ��ȥ������������ȡֵΪ1��ά���¶�Ӧ����ЩȨ��ֵ��������������ÿ�����뵥�ʵġ�Ƕ�����������
6 �����
��������������ļ��㣬ants����ʻ��һ��1 x 10000���������1 x 300���������ٱ����뵽����㡣�������һ��softmax�ع������������ÿ����㽫�����һ��0-1֮���ֵ�����ʣ�����Щ�����������Ԫ���ĸ���֮��Ϊ1��
������һ�����ӣ�ѵ������Ϊ (input word: ��ants���� output word: ��car��) �ļ���ʾ��ͼ��
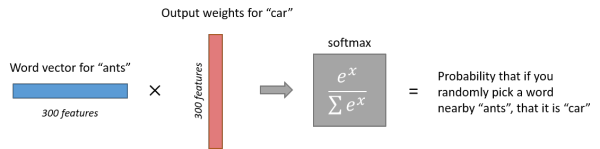
7 ����
�������ǽ�ͨ��ֱ��������һЩ˼����
���������ͬ�ĵ������ŷdz����Ƶġ������ġ���Ҳ���Ǵ��ڵ��ʺ����ƣ����硰Kitty climbed the tree���͡�Cat climbed the tree��������ôͨ�����ǵ�ģ��ѵ�������������ʵ�Ƕ���������dz����ơ�
��ô��������ӵ�����Ƶġ������ġ�������ʲô�����أ��������ͬ��ʡ�intelligent���͡�smart�������Ǿ�������������Ӧ��ӵ����ͬ�ġ������ġ��������硱engine���͡�transmission��������صĴ������Ҳӵ�������Ƶ������ġ�
ʵ���ϣ����ַ���ʵ����Ҳ����������дʸɻ���stemming�������磬������ԡ�ant���͡�ants���������ʻ�ϰ�����ƵĴ�������
�ʸɻ���stemming������ȥ�����õ��ʸ��Ĺ��̡�
����Skip-gram ģ�͵�ѵ��
ǰ�������Ѿ��˽�skip-gram������㡢���㡢����㡣�ڵڶ����֣���������뽲�����skip-gramģ���Ͻ��и�Ч��ѵ�����ڵ�һ���ֽ�����ɺ����ǻᷢ��Word2Vecģ����һ��������������磨Ȩ�ؾ����ģ�dz���
�ٸ����ӣ�����ӵ��10000�����ʵĴʻ�������������Ƕ��300ά�Ĵ���������ô���ǵ�����-����Ȩ�ؾ���������-������Ȩ�ؾ��������� 10000 x 300 = 300���Ȩ�أ�������Ӵ���������н����ݶ��½����൱���ġ��������ǣ�����Ҫ������ѵ��������������ЩȨ�ز��ұ������ϡ�������������Ȩ�ؾ����������������ѵ��������ζ��ѵ�����ģ�ͽ����Ǹ����ѡ�
Word2Vec �����������ĵڶ�ƪ������ǿ������Щ���⣬�����������ڵڶ�ƪ�����е��������£�
1. �������ĵ�����ϣ�word pairs�����ߴ�����Ϊ������words����������
2. �Ը�Ƶ�ε��ʽ��г���������ѵ�������ĸ�����
3. ���Ż�Ŀ����á�negative sampling������������ÿ��ѵ��������ѵ��ֻ�����һС���ֵ�ģ��Ȩ�أ��Ӷ����ͼ��㸺����
��ʵ֤�����Գ��ôʳ������Ҷ��Ż�Ŀ����á�negative sampling������������ѵ�������еļ��㸺�����������ѵ���Ĵ�������������
1 Word pairs and "phases"
���ĵ�����ָ����һЩ������ϣ����ߴ��飩�ĺ���Ͳ��Ժ������ȫ��ͬ�����塣���硰Boston Globe����һ�ֱ��������֣��������ġ�Boston���͡�Globe�����������ĵ���ȴ���ﲻ�������ĺ��塣��ˣ���������ֻҪ���֡�Boston Globe�������Ǿ�Ӧ�ð�����Ϊһ�������Ĵ���������������������ǽ����ͬ�������ӻ��С�New York������United Stated���ȡ�
��Google������ģ���У���������ѵ��������������Google News���ݼ��е�1000�ڵĵ��ʣ����dz��˵����������⣬������ϣ�����飩����3����֮�ࡣ
������˽����ģ����ν����ĵ��еĴ����ȡ�����Կ������С�Learning Phrases����һ�£���Ӧ�Ĵ����� word2phrase.c ������������¡�
�������ӣ�
http://t.cn/RMct1c7
http://t.cn/RMct1c7
�������ӣ�
http://t.cn/R5auFLz
2 �Ը�Ƶ�ʳ���
�ڵ�һ���ֵĽ����У�����չʾ��ѵ����������δ�ԭʼ�ĵ������ɳ����ģ����������ظ�һ�Ρ����ǵ�ԭʼ�ı�Ϊ��The quick brown fox jumps over the laze dog���������ʹ�ô�СΪ2�Ĵ��ڣ���ô���ǿ��Եõ�ͼ��չʾ����Щѵ��������

���Ƕ��ڡ�the�����ֳ��ø�Ƶ���ʣ������Ĵ�����ʽ����������������⣺
�����ǵõ��ɶԵĵ���ѵ������ʱ��("fox", "the") ������ѵ������������������ṩ���ڡ�fox�������������Ϣ����Ϊ��the����ÿ�����ʵ��������м���������֡�
�������ı��С�the�������ij��ôʳ��ָ��ʺܴ�������ǽ����д����ģ���the����...��������ѵ������������Щ��������ԶԶ����������ѧϰ��the����������������ѵ����������
Word2Vecͨ����������ģʽ��������ָ�Ƶ�����⡣���Ļ���˼�����£�����������ѵ��ԭʼ�ı���������ÿһ�����ʣ����Ƕ���һ�����ʱ����Ǵ��ı���ɾ�����������ɾ���ĸ����뵥�ʵ�Ƶ���йء�
����������ô��ڴ�С�����������Ҵ����ǵ��ı���ɾ�����еġ�the������ô��������Ľ����
1. ��������ɾ�����ı������еġ�the������ô�����ǵ�ѵ�������У���the���������ԶҲ������������ǵ������Ĵ����С�
2. ����the����Ϊinput wordʱ�����ǵ�ѵ�����������ٻ����10����
��仰Ӧ����ô���⣬�������ǵ��ı��н�������һ����the������ô�������the����Ϊinput wordʱ����������span=10����ʱ��õ�10��ѵ������ ("the", ...) �����ɾ�������the�������Ǿͻ����10��ѵ��������ʵ�������ǵ��ı��в�ֹһ����the������˵���the����Ϊinput word��ʱ�����ٻ����10��ѵ��������
�����ᵽ��������Ӱ����ʵ���ϾͰ������ǽ���˸�Ƶ�ʴ��������⡣
3 ������
word2vec��C���Դ���ʵ����һ�������ڴʻ���б���ij���ʸ��ʵĹ�ʽ��
��i ��һ�����ʣ�Z(��i) �� ��i ������������������г��ֵ�Ƶ�Ρ��ٸ����ӣ�������ʡ�peanut����10�ڹ�ģ��С�������г�����1000�Σ���ô Z(peanut) = 1000/1000000000 = 1e - 6��
�ڴ����л���һ�������С�sample���������������һ����ֵ��Ĭ��ֵΪ0.001����gensim���е�Word2Vec��˵���У��������Ĭ��Ϊ0.001���ĵ��ж���������Ľ���Ϊ�� threshold for configuring which higher-frequency words are randomly downsampled���������ֵԽС��ζ��������ʱ����������ĸ���ԽС������Խ��ĸ��ʱ�����ɾ������
P(��i) �����ű���ij�����ʵĸ��ʣ�
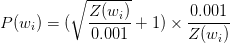
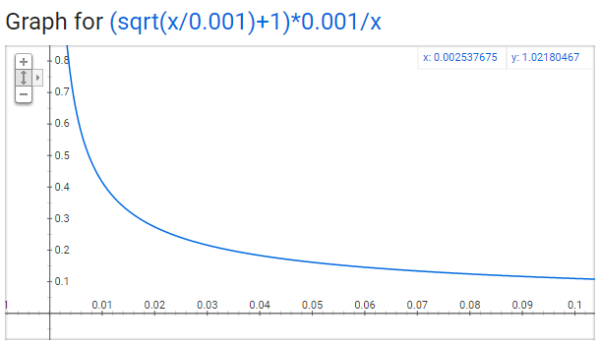
ͼ��x������� Z(��i) �������� ��i �������г���Ƶ�ʣ�y�����ij�����ʱ������ĸ��ʡ�����һ���Ӵ��������˵���������ʵij���Ƶ�ʲ���ܴ�ʹ�dz��ôʣ�Ҳ�������ر��
�����ͼ�У����ǿ��Կ��������ŵ��ʳ���Ƶ�ʵ����ߣ��������������ĸ���Խ��ԽС�����ǻ����Կ���һЩ��Ȥ�Ľ��ۣ�
�� �� Z(��i) <= 0.0026 ʱ��P(��i) = 1.0 ���������������г��ֵ�Ƶ��С�� 0.0026 ʱ������ 100% �������ģ�����ζ��ֻ����Щ�������г���Ƶ�ʳ��� 0.26% �ĵ��ʲŻᱻ������
�� ��ʱ Z(��i) = 0.00746 ʱ��P(��i) = 0.5����ζ����һ���ֵĵ����� 50% �ĸ��ʱ�������
�� �� Z(��i) = 1.0 ʱ��P(��i) = 0.033����ζ���ⲿ�ֵ����� 3.3% �ĸ��ʱ�������
�����ȥ����ƪ���ĵĻ�����ᷢ�������������жԺ�����ʽ�Ķ������C���Դ����ʵ������һЩ��𣬵�����ΪC���Դ���Ĺ�ʽʵ���Ǹ�Ȩ����һ���汾��
4 ��������negative sampling��
ѵ��һ����������ζ��Ҫ����ѵ���������Ҳ��ϵ�����Ԫ��Ȩ�أ��Ӷ�������߶�Ŀ���ȷԤ�⡣ÿ�������羭��һ��ѵ��������ѵ��������Ȩ�ؾͻ����һ�ε�����
�����������������۵ģ�vocabulary�Ĵ�С���������ǵ�Skip-Gram�����罫��ӵ�д��ģ��Ȩ�ؾ������е���ЩȨ����Ҫͨ�����������ڼƵ�ѵ�����������е��������Ƿdz����ļ�����Դ�ģ�����ʵ����ѵ��������dz�����
��������negative sampling�������������⣬�����������ѵ���ٶȲ��Ҹ������õ���������������һ�ַ�������ͬ��ԭ��ÿ��ѵ�������������е�Ȩ�أ�������ÿ����һ��ѵ��������������һС���ֵ�Ȩ�أ������ͻή���ݶ��½������еļ�������
��������ѵ������ ( input word: "fox"��output word: "quick") ��ѵ�����ǵ�������ʱ���� fox���͡�quick�����Ǿ���one-hot����ġ�������ǵ�vocabulary��СΪ10000ʱ��������㣬����������Ӧ��quick�����ʵ��Ǹ���Ԫ������1������9999����Ӧ�����0���������9999�������������Ϊ0����Ԫ�������Ӧ�ĵ������dz�Ϊ��negative�� word��
��ʹ�ø�����ʱ�����ǽ����ѡ��һС���ֵ�negative words������ѡ5��negative words�������¶�Ӧ��Ȩ�ء�����Ҳ������ǵġ�positive�� word����Ȩ�ظ��£�����������������У��������ָ���ǡ�quick������
�������У�����ָ��ָ������С��ģ���ݼ���ѡ��5-20��negative words��ȽϺã����ڴ��ģ���ݼ����Խ�ѡ��2-5��negative words��
����һ�����ǵ�����-�����ӵ��300 x 10000��Ȩ�ؾ������ʹ���˸������ķ������ǽ���ȥ�������ǵ�positive word-��quick���ĺ�����ѡ�������5��negative words�Ľ���Ӧ��Ȩ�أ�����6�������Ԫ���൱��ÿ��ֻ���� 300 x 6 = 1800 ��Ȩ�ء�����3�����Ȩ����˵���൱��ֻ������0.06%��Ȩ�أ���������Ч�ʾʹ������ߡ�
5 ���ѡ��negative words
����ʹ�á�һԪģ�ͷֲ���unigram distribution������ѡ��negative words����
Ҫע���һ���ǣ�һ�����ʱ�ѡ��negative sample�ĸ��ʸ������ֵ�Ƶ���йأ�����Ƶ��Խ�ߵĵ���Խ���ױ�ѡ��negative words��
��word2vec��C����ʵ���У�����Կ�������������ʵ�ʵ�ֹ�ʽ��ÿ�����ʱ�ѡΪ��negative words���ĸ��ʼ��㹫ʽ������ֵ�Ƶ���йء�
�����еĹ�ʽʵ�����£�
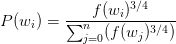
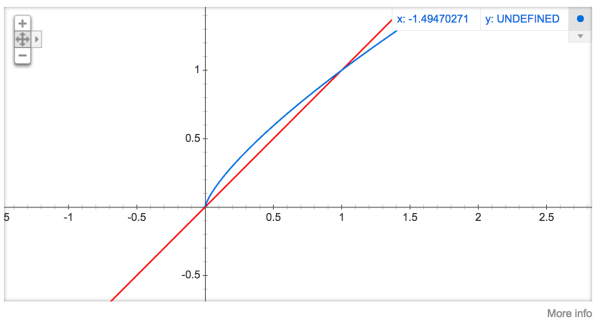
ÿ�����ʱ�����һ��Ȩ�أ��� f(��i)�� �������ŵ��ʳ��ֵ�Ƶ�Ρ�
��ʽ�п�3/4�ĸ�����ȫ�ǻ��ھ���ģ��������ᵽ�����ʽ��Ч��Ҫ��������ʽ���ӳ�ɫ���������google�������������롰plot y = x^(3/4) and y = x����Ȼ��������ͼ������ͼ������ϸ�۲�x��[0,1]������ʱy��ȡֵ��x^(3/4) ��һС�λ��Σ�ȡֵ�� y = x ����֮�ϡ�
��������C����ʵ�ַdz�����Ȥ��unigram table��һ��������һ�ڸ�Ԫ�ص����飬����������ɴʻ����ÿ�����ʵ����������ģ�����������������ظ���Ҳ����˵��Щ���ʻ���ֶ�Ρ���ôÿ�����ʵ���������������г��ֵĴ�������ξ����أ��й�ʽ��Ҳ����˵�����������������*1��=�����ڱ��г��ֵĴ�����
�������ű��Ժ�ÿ��ȥ���ǽ��и�����ʱ��ֻ��Ҫ��0-1�ڷ�Χ������һ���������Ȼ��ѡ�����������Ϊ�����������Ǹ�������Ϊ���ǵ�negative word���ɡ�һ�����ʵĸ���������Խ����ô����������г��ֵĴ�����Խ�࣬����ѡ�еĸ��ʾ�Խ��
��ĿǰΪֹ��Word2Vec�е�Skip-Gramģ�;ͽ����ˣ���������������ѧ��ʽ�Ƶ�ϸ�����ﲢû�����롣��ƪ����ֻ�Ƕ���ʵ��ϸ���ϵ�һЩ˼������˲�����
6 ��������
������˽�����ʵ��ϸ�ڣ�����ȥ�鿴C���Ե�ʵ��Դ�룺
http://t.cn/R6w6Vi7
����Word2Vec�̳���ο���
http://t.cn/R6w6ViZ
��һ���ֽ����������� TensorFlow ʵ��һ�� Word2Vec �е� Skip-Gram ģ�͡�
����Skip-gram ģ�͵�ʵ��
1 ���˵��
�����ֽ�����TensorFlow�����Skip-Gramģ�͡�������ʵս�����Ŀ����Ҫ�Ǽ����Skip-Gramģ����һЩ˼���trick�����⡣�������������Ϲ�ģ�������������㷨ϸ���Լ�ѵ���ɱ���ԭ��ѵ�����Ľ����Ȼ������gensim��װ��Word2Vec��ȵģ��������ʺ�����ȥ��������ϰSkip-Gramģ�͵�˼�롣
2 ���߽���
�� ���ԣ�Python 3
�� ����TensorFlow��1.0�汾�����������ݴ��������������У�
�� �༭����jupyter notebook
�� ����GPU��floyd (FloydHub Blog)
�� ���ݼ�������Ԥ�������ά���ٿ����£�Ӣ��)
3 ���IJ���
��������Ҫ���������ĸ����ֽ��д��빹�죺
- ����Ԥ����
- ѵ����������
- ģ����
- ģ����֤
3.1 ����Ԥ����
����Ԥ����������Ҫ������
�滻�ı���������Ų�ȥ����Ƶ��
���ı��ִ�
��������
����ӳ���
�������Ƕ���һ�����������ǰ�����������ı�����ϴ�ͷִʲ�����

����ĺ���ʵ�����滻��㼰ɾ����Ƶ�ʲ��������طִʺ���ı���
����������������������ϴ������ݣ�

���˷ִʺ���ı����Ϳ��Թ������ǵ�ӳ���������Ͳ����������Ӧ�ö��Ƚ���Ϥ��

���ǻ����Կ�һ���ı��ʹʵ�Ĺ�ģ��С��

�����ı��е��ʴ�ԼΪ1660��Ĺ�ģ���ʵ��СΪ6�����ң������ģ����ѵ���õĴ�������ʵ�Dz����ģ�������ѵ����һ���������Ե�ģ�͡�
3.2 ѵ����������
����֪��skip-gram�У�ѵ����������ʽ��(input word, output word)������output word��input word�������ġ�Ϊ�˼���ģ������������ѵ���ٶȣ������ڹ���batch֮ǰҪ���������в�������ͣ�ôʵ��������ء�
3.2.1 ����
�ڽ�ģ�����У�ѵ���ı��л���ֺܶࡰthe������a��֮��ij��ôʣ�Ҳ��ͣ�ôʣ�����Щ�ʶ������ǵ�ѵ��������ܶ�����������һƪWord2Vec��������������г���������Ƶ��ͣ�ô�������ģ�͵�������������ѵ����
���Dz������¹�ʽ������ÿ�����ʱ�ɾ���ĸ��ʴ�С��
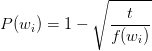
���� f(wi) �������� wi �ij���Ƶ�Ρ�tΪһ����ֵ��һ�����1e-3��1e-5֮�䡣

����Ĵ��������������ÿ�����ʱ�ɾ���ĸ��ʣ������ڸ��ʽ����˲�������������������õ��˲������ĵ����б���
3.2.2 ����batch
������������һ��skip-gram��������ʽ��skip-gram��ͬ��CBOW��CBOW�ǻ���������Ԥ�ǰinput word����skip-gram���ǻ���һ��input word��Ԥ�������ģ����һ��input word���Ӧ��������ġ��������ٸ����ӡ�The quick brown fox jumps over lazy dog����������ǹ̶�skip_window=2�Ļ�����ôfox�������ľ���[quick, brown, jumps, over]��������ǵ�batch_size=1�Ļ�����ôʵ����һ��batch�����ĸ�ѵ��������
����ķ���ת��Ϊ��������������裬��һ�����ҵ�ÿ��input word�������ģ��ڶ������ǻ��������Ĺ���batch��
�������ҵ�input word�������ĵ����б���

���Ƕ�����һ��get_targets����������һ�����������ţ��������������ȥ���ҵ��ʱ��ж�Ӧ�������ģ�Ĭ��window_size=5������ע��������һ��Сtrick������ʵ��ѡ��input word������ʱ��ʹ�õĴ��ڴ�С��һ������[1, window_size]�����������������Ŀ������ģ�����ȥ��ע��input word�����ʡ�
������������ĺ������ܹ����ɵ�ͨ��input word�ҵ����������ĵ��ʡ�������Щ�������ǾͿ��Թ������ǵ�batch������ѵ����

ע������Ĵ����batch�Ĵ���������֪������ÿ��input word��˵���ж��output word�������ģ����������ǵ������ǡ�fox������������[quick, brown, jumps, over]����ôfox��һ��batch�о����ĸ�ѵ������[fox, quick], [fox, brown], [fox, jumps], [fox, over]��
3.3 ģ����
����Ԥ������������Ҫ���������ǵ�ģ�͡���ģ����Ϊ�˼���ѵ������ߴ����������������Dz��ø�������ʽ����Ȩ�ظ��¡�
3.3.1 ����㵽Ƕ���
����㵽�����Ȩ�ؾ�����ΪǶ���Ҫ������ά�ȣ�һ��embeding_size����Ϊ50-300֮�䡣

Ƕ���� lookup ͨ�� TensorFlow �е� embedding_lookup ʵ�֣������
http://t.cn/RofvbgF![]() http://t.cn/RofvbgF
http://t.cn/RofvbgF
3.3.2 Ƕ��㵽�����
��skip-gram�У�ÿ��input word�Ķ�������ĵ���ʵ�����ǹ���һ��Ȩ�ؾ������ǽ�ÿ����input word, output word��ѵ����������Ϊ���ǵ����롣Ϊ�˼���ѵ��������ߴ����������������Dz���negative sampling�ķ���������Ȩ�ظ��¡�
TensorFlow�е�sampled_softmax_loss�����ڽ�����negative sampling������ʵ�������ǻ��ģ�͵�ѵ��loss�������http://t.cn/RofvS4t

��ע������е�softmax_w��ά����vocab_size x embedding_size��������ΪTensorFlow�е�sampled_softmax_loss�в���weights��size��[num_classes, dim]��
3.4 ģ����֤
������IJ����У������Ѿ���ģ�͵Ŀ�ܴ�������������������ѵ��ѵ��һ��ģ�͡�Ϊ���ܹ�����ֱ�۵ع۲�ѵ��ÿ���ε��������������ѡ�����ʣ�������ѵ�����������ǵ����ƴ�����ô�仯�ġ�
ѵ��ģ�ͣ�

������ע��һ�£�������Ҫ����ȥ�ô����ӡ��֤�����ƵĴʣ���Ϊ��������һ�����㲽�裬���Ǽ������ƶȣ���dz����ļ�����Դ���������Ҳ���������Դ�����������1000�ִ�ӡһ�ν����

������ѵ�����������ģ�ͻ���ѧ����һЩ�����ʵ����壬����one�ȼ������Լ�gold֮��Ľ����ʣ�animals�е����ƴ�Ҳ���ȷ��
Ϊ���ܹ���ȫ��ع۲�����ѵ����������Dz���sklearn�е�TSNE���Ը�ά���������п��ӻ��������http://t.cn/Rofvr7D![]() http://t.cn/Rofvr7D
http://t.cn/Rofvr7D
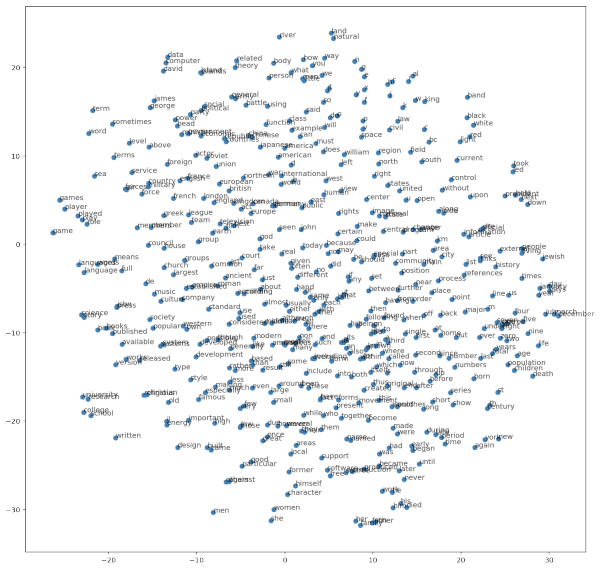
�����ͼ��ͨ��TSNE����ά�Ĵ��������վ���Զ����ʾ�ڶ�ά����ϵ�С�
��������һ��ϸ�ڣ�

��������ʾ�����Ŵ�ͼ�ľֲ������Կ���Ч����������
��������Ч���ļ��ɣ�
-
����ѵ�����������Ͽ�Խ��ģ��ѧϰ�Ŀ�ѧϰ����Ϣ��Խ�ࡣ
-
����window size�����Ի�ø������������Ϣ��
-
����embedding size���Լ�����Ϣ��ά����ʧ����Ҳ���˹�����һ�㳣�õĹ�ģΪ50-300��
4 ��¼��
git�����л��ṩ�����ĵĴ�����������롣ͬʱ�ṩ�����ĵ�һ��ѵ�����ϣ��������Ҵ�ij��Ƹ��վ����ȡ����Ƹ���ݣ����˷ִʺ�ȥ��ͣ�ôʵIJ����������Ϲ�ģ̫С��ѵ��Ч�������á�

����������ģ��ѵ�����������ݣ����Կ�����һ�������屻�ھ����������word��excel��office�ܽӽ���ppt��project�����ִ����ȣ��Լ���˼ά�����Ա���ȣ���������Ч�����Ǻܲһ�������������ϵĹ�ģ̫С��ֻ��70�����ϣ�����һ������ģ��Ҳû��ȥ���Ρ��������Ȥ��ͬѧ�����Լ����»���и��õ�Ч����
�������������
http://t.cn/RofPq2p![]() http://t.cn/RofPq2p
http://t.cn/RofPq2p
������ ���� Word2Vec ֮ Skip-Gram ģ�� - ֪��ע�����ҷ���֪����Щ��ʽ���ֻ��˲���ʾ������PC�˿���������ʾ������������һᾡ����ͼƬ���ߴ��ı�����ʾ��ʽ�������ֻ����Ķ���д��֮ǰר����������ɹ�������������������������У�����Ҫ��˼��졣�����ҡ�![]() https://zhuanlan.zhihu.com/p/27234078
https://zhuanlan.zhihu.com/p/27234078