导入包
import pandas as pd
import jieba
from gensim.models import word2vec
分词
# 分词
def tokenizer(text): # zh_pattern = re.compile(u'[^\u4e00-\u9fa5]+')# text = re.sub(zh_pattern,"", text)return [word for word in jieba.lcut(text) if word not in stop_words]
注释部分是用正则表达式筛选汉字的,但我想想又不对,数字也是有语义的,所以没用了。
去停用词
# 去停用词
def get_stop_words():file_object = open('data/stopwords.txt',encoding='utf-8')stop_words = []for line in file_object.readlines():line = line[:-1]line = line.strip()stop_words.append(line)return stop_words
首先看一下数据结构。
traindata.to_csv('data/text.tsv', columns=['text'], index=0)
text = pd.read_csv('data/text.tsv')
text.head()

这是一个中文文本的评论数据集。现在我们调用分词和去停用词的函数对它进行处理。
stop_words = get_stop_words()
text_cut = []
for row in text.itertuples():seg = tokenizer(row[1])text_cut.append(seg)
text_concat=[]
for seg in text_cut:seg_concat=[" ".join(word for word in seg)]text_concat.append(seg_concat)
将处理好的文本保存为 corpus.tsv。
corpus = pd.DataFrame(data=text_concat)
corpus.to_csv('data/corpus.tsv', header=0, index=0)
可能有人要说为什么不直接存,还要用pandas转化那么麻烦。其实就是我先百度到这种方法的,懒得再搞了。
这是保存的corpus.tsv。

接下来主角word2vec登场,就两句代码,很简洁。
sentences = word2vec.LineSentence('data/corpus.tsv')
model = Word2Vec(sentences, min_count=1)
数据量比较大的时候用linesentence读取文件比较好,因为它是一段段处理的,如果用list一次性读入比较占内存。
训练好的词向量保存在model.wv里。我们来测试一下。
vector = model.wv['车']
print(vector)

这是100维的词向量,参数是默认的,可以修改。
然后来看一下词语相似度。
pairs = [('备胎', '硬伤'), ('车', '用处'), ('百万', '空调'),
]
for w1, w2 in pairs:print('%r\t%r\t%.2f' % (w1, w2,model.wv.similarity(w1, w2)))
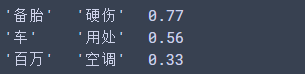
输出差不多符合我们的判断。
最后将模型保存。
model.save("comment.model")
# 对应的加载方式
# model_2 = word2vec.Word2Vec.load("comment.model")