CopyOnWriteArrayList
官方定义
CopyOnWriteArrayList是ArrayList的线程安全变体,其中通过创建底层数组的新副本来实现所有可变操作(添加,设置等)。
这通常成本太高,但是当遍历操作大大超过突变时,它可能比替代方法更有效,并且当您不能或不想同步遍历但需要排除并发线程之间的干扰时非常有用。
“快照”样式迭代器方法在创建迭代器时使用对数组状态的引用。
这个数组在迭代器的生命周期中永远不会改变,所以干扰是不可能的,并且保证迭代器不会抛出ConcurrentModificationException。自迭代器创建以来,迭代器不会反映列表的添加,删除或更改。不支持对迭代器本身进行元素更改操作(删除,设置和添加)。这些方法抛出UnsupportedOperationException。
允许所有元素,包括null。
内存一致性效果:与其他并发集合一样,在将对象放入CopyOnWriteArrayList之前,线程中的操作发生在从另一个线程中的CopyOnWriteArrayList访问或删除该元素之后的操作之前。
使用例子
网上这种代码大同小异。
ArrayList 版本
下面来看一个列子:两个线程一个线程循环读取,一个线程修改list的值。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class CopyOnWriteArrayListDemo {
/*** 读线程*/private static class ReadTask implements Runnable {
List<String> list;public ReadTask(List<String> list) {
this.list = list;}public void run() {
for (String str : list) {
System.out.println(str);}}}/*** 写线程*/private static class WriteTask implements Runnable {
List<String> list;int index;public WriteTask(List<String> list, int index) {
this.list = list;this.index = index;}public void run() {
list.remove(index);list.add(index, "write_" + index);}}public void run() {
final int NUM = 10;List<String> list = new ArrayList<String>();for (int i = 0; i < NUM; i++) {
list.add("main_" + i);}ExecutorService executorService = Executors.newFixedThreadPool(NUM);for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));executorService.execute(new WriteTask(list, i));}executorService.shutdown();}public static void main(String[] args) {
new CopyOnWriteArrayListDemo().run();}
}
这个运行结果会报错。
因为我们在读取的时候,对列表进行了修改。
CopyOnWriteArrayList 版本
直接列表创建替换即可:
List<String> list = new CopyOnWriteArrayList<String>();
则运行结果正常。
CopyOnWriteArrayList 优缺点
优点
- 保证多线程的并发读写的线程安全
缺点
内存消耗
有数组拷贝自然有内存问题。如果实际应用数据比较多,而且比较大的情况下,占用内存会比较大,这个可以用ConcurrentHashMap来代替。
- 如何避免
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
数据一致性
CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器
使用场景
CopyOnWrite并发容器用于读多写少的并发场景。
比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。
实现代码如下:
/*** 黑名单服务*/
public class BlackListServiceImpl {
private static CopyOnWriteMap<String, Boolean> blackListMap = new CopyOnWriteMap<String, Boolean>(1000);public static boolean isBlackList(String id) {
return blackListMap.get(id) == null ? false : true;}public static void addBlackList(String id) {
blackListMap.put(id, Boolean.TRUE);}/*** 批量添加黑名单** @param ids*/public static void addBlackList(Map<String,Boolean> ids) {
blackListMap.putAll(ids);}
}
代码很简单,但是使用CopyOnWriteMap需要注意两件事情:
-
减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
-
使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用上面代码里的addBlackList方法。
为什么没有并发列表?
问:JDK 5在java.util.concurrent里引入了ConcurrentHashMap,在需要支持高并发的场景,我们可以使用它代替HashMap。
但是为什么没有ArrayList的并发实现呢?
难道在多线程场景下我们只有Vector这一种线程安全的数组实现可以选择么?为什么在java.util.concurrent 没有一个类可以代替Vector呢?
- 别人的理解
ConcurrentHashMap的出现更多的在于保证并发,从它采用了锁分段技术和弱一致性的Map迭代器去避免并发瓶颈可知。(jdk7 及其以前)
而ArrayList中很多操作很难避免锁整表,就如contains()、随机取get()等,进行查询搜索时都是要整张表操作的,那多线程时数据的实时一致性就只能通过锁来保证,这就限制了并发。
- 个人的理解
这里说的并不确切。
如果没有数组的长度变化,那么可以通过下标进行分段,不同的范围进行锁。但是这种有个问题,如果数组出现删除,增加就会不行。
说到底,还是性能和安全的平衡。
- 比较中肯的回答
在java.util.concurrent包中没有加入并发的ArrayList实现的主要原因是:很难去开发一个通用并且没有并发瓶颈的线程安全的List。
像ConcurrentHashMap这样的类的真正价值(The real point/value of classes)并不是它们保证了线程安全。而在于它们在保证线程安全的同时不存在并发瓶颈。
举个例子,ConcurrentHashMap采用了锁分段技术和弱一致性的Map迭代器去规避并发瓶颈。
所以问题在于,像“Array List”这样的数据结构,你不知道如何去规避并发的瓶颈。拿contains() 这样一个操作来说,当你进行搜索的时候如何避免锁住整个list?
另一方面,Queue 和Deque (基于Linked List)有并发的实现是因为他们的接口相比List的接口有更多的限制,这些限制使得实现并发成为可能。
CopyOnWriteArrayList是一个有趣的例子,它规避了只读操作(如get/contains)并发的瓶颈,但是它为了做到这点,在修改操作中做了很多工作和修改可见性规则。
此外,修改操作还会锁住整个List,因此这也是一个并发瓶颈。
所以从理论上来说,CopyOnWriteArrayList并不算是一个通用的并发List。
源码解读
类定义
public class CopyOnWriteArrayList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;}
实现了最基本的 List 接口。
属性
我们看到前几次反复提及的 ReentrantLock 可重入锁。
array 比较好理解,以前的 List 也是通过数组实现的。
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/*** Gets the array. Non-private so as to also be accessible* from CopyOnWriteArraySet class.*/
final Object[] getArray() {
return array;
}
/*** Sets the array.*/
final void setArray(Object[] a) {
array = a;
}
构造器
/*** Creates an empty list.*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}/*** Creates a list containing the elements of the specified* collection, in the order they are returned by the collection's* iterator.** @param c the collection of initially held elements* @throws NullPointerException if the specified collection is null*/
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;if (c.getClass() == CopyOnWriteArrayList.class)elements = ((CopyOnWriteArrayList<?>)c).getArray();else {
elements = c.toArray();// c.toArray might (incorrectly) not return Object[] (see 6260652)if (elements.getClass() != Object[].class)elements = Arrays.copyOf(elements, elements.length, Object[].class);}setArray(elements);
}/*** Creates a list holding a copy of the given array.** @param toCopyIn the array (a copy of this array is used as the* internal array)* @throws NullPointerException if the specified array is null*/
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
这几种构造器都是统一调用的 setArray 方法:
/*** Sets the array.*/
final void setArray(Object[] a) {
array = a;
}
这个方法非常简单,就是初始化对应的数组信息。
核心方法
我大概看了下,很多方法和以前大同小异,我们来重点关注下几个修改元素值的方法:
set
方法通过 ReentrantLock 可重入锁控制加锁和解锁。
这里最巧妙的地方在于,首先会判断指定 index 的值是否和预期值相同。
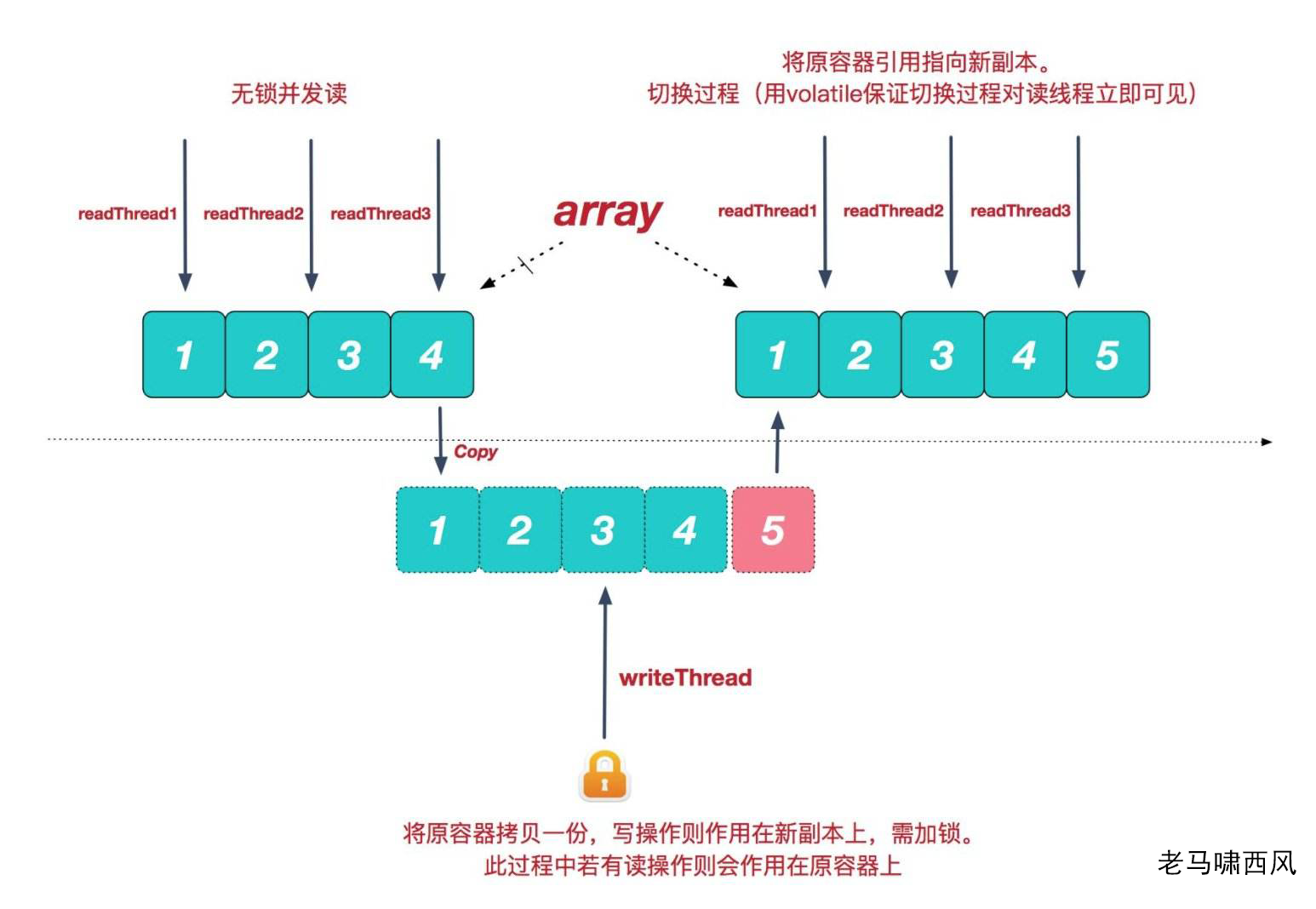
按理说相同,是可以不进行更新的,这样性能更好;不过 jdk 中还是会进行一次设置。
如果值不同,则会对原来的 array 进行拷贝,然后更新,最后重新设置。
这样做的好处就是写是不阻塞读的,缺点就是比较浪费内存,拷贝数组也是要花时间的。
/*** Replaces the element at the specified position in this list with the* specified element.** @throws IndexOutOfBoundsException {@inheritDoc}*/
public E set(int index, E element) {
final ReentrantLock lock = this.lock;lock.lock();try {
Object[] elements = getArray();E oldValue = get(elements, index);if (oldValue != element) {
int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len);newElements[index] = element;setArray(newElements);} else {
// 不是完全禁止操作; 确保可变的写语义// Not quite a no-op; ensures volatile write semanticssetArray(elements);}return oldValue;} finally {
lock.unlock();}
}
ps: 这里的所有变更操作是互斥的。
add
/*** Appends the specified element to the end of this list.** @param e element to be appended to this list* @return {@code true} (as specified by {@link Collection#add})*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;lock.lock();try {
Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;setArray(newElements);return true;} finally {
lock.unlock();}
}
也是通过 ReentrantLock 进行加锁。
这里比起更新更加简单直接,因为是添加元素,所以新数组的长度直接+1。
jdk 中数组的这种复制都是使用的 Arrays.copy 方法,这个以前实测,性能还是不错的。
add(int, E)
/*** Inserts the specified element at the specified position in this* list. Shifts the element currently at that position (if any) and* any subsequent elements to the right (adds one to their indices).** @throws IndexOutOfBoundsException {@inheritDoc}*/
public void add(int index, E element) {
final ReentrantLock lock = this.lock;lock.lock();try {
Object[] elements = getArray();int len = elements.length;// 越界校验if (index > len || index < 0)throw new IndexOutOfBoundsException("Index: "+index+", Size: "+len);Object[] newElements;int numMoved = len - index;// 如果是放在数组的最后,其实就等价于上面的 add 方法了。if (numMoved == 0)newElements = Arrays.copyOf(elements, len + 1);else {
// 如果元素不是在最后,就从两边开始复制即可://0...index-1//index+1..lennewElements = new Object[len + 1];System.arraycopy(elements, 0, newElements, 0, index);System.arraycopy(elements, index, newElements, index + 1,numMoved);}// 统一设置 index 位置的元素信息newElements[index] = element;setArray(newElements);} finally {
lock.unlock();}
}
remove 删除元素
/*** Removes the element at the specified position in this list.* Shifts any subsequent elements to the left (subtracts one from their* indices). Returns the element that was removed from the list.** @throws IndexOutOfBoundsException {@inheritDoc}*/
public E remove(int index) {
final ReentrantLock lock = this.lock;lock.lock();try {
Object[] elements = getArray();int len = elements.length;E oldValue = get(elements, index);int numMoved = len - index - 1;// 如果删除最后一个元素,直接从 0..len-1 进行拷贝即可。if (numMoved == 0)setArray(Arrays.copyOf(elements, len - 1));else {
// 新的数组比原来长度-1Object[] newElements = new Object[len - 1];//0...index-1 拷贝//indx+1...len-1 拷贝System.arraycopy(elements, 0, newElements, 0, index);System.arraycopy(elements, index + 1, newElements, index,numMoved);setArray(newElements);}return oldValue;} finally {
lock.unlock();}
}
删除元素实际上和添加元素的流程是类似的。
不过很奇怪,没有做越界判断?
迭代器
说明
COWList 的迭代器和常规的 ArrayList 迭代器还是有差异的,我们以前可能会被问过,一边遍历一边删除如何实现?
答案可能就是 Iterator。
但是 COW 的 Iterator 恰恰是不能支持变更的,个人理解是为了保证并发只在上面提及的几个变更中控制。
实现
迭代器定义
static final class COWIterator<E> implements ListIterator<E> {
/** Snapshot of the array */private final Object[] snapshot;/** Index of element to be returned by subsequent call to next. */private int cursor;private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;snapshot = elements;}
}
基础方法
这里提供了一些基础的最常用的方法。
public boolean hasNext() {
return cursor < snapshot.length;
}
public boolean hasPrevious() {
return cursor > 0;
}
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext())throw new NoSuchElementException();return (E) snapshot[cursor++];
}
@SuppressWarnings("unchecked")
public E previous() {
if (! hasPrevious())throw new NoSuchElementException();return (E) snapshot[--cursor];
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
不支持的操作
public void remove() {
throw new UnsupportedOperationException();
}
public void set(E e) {
throw new UnsupportedOperationException();
}
public void add(E e) {
throw new UnsupportedOperationException();
}@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);Object[] elements = snapshot;final int size = elements.length;for (int i = cursor; i < size; i++) {
@SuppressWarnings("unchecked") E e = (E) elements[i];action.accept(e);}cursor = size;
}
小结
COW 这种思想是非常有优秀的,在写少读多的场景,可以通过空间换取时间。
希望本文对你有帮助,如果有其他想法的话,也可以评论区和大家分享哦。
各位极客的点赞收藏转发,是老马持续写作的最大动力!
