参数VS超参数(Parameters vs Hyperparameters)
想要你的深度神经网络起很好的效果,你还需要规划好你的参数以及超参数。
什么是超参数?
比如算法中的learning rate (学习率)、iterations(梯度下降法循环的数量)、 (隐藏层数目)、 (隐藏层单元数目)、choice of activation function(激活函数的选择)都需要你来设置,这些数字实际上控制了最后的参数 和 的值,所以它们被称作超参数。
实际上深度学习有很多不同的超参数,之后我们也会介绍一些其他的超参数,如momentum、mini batch size、regularization parameters等等。
如何寻找超参数的最优值?
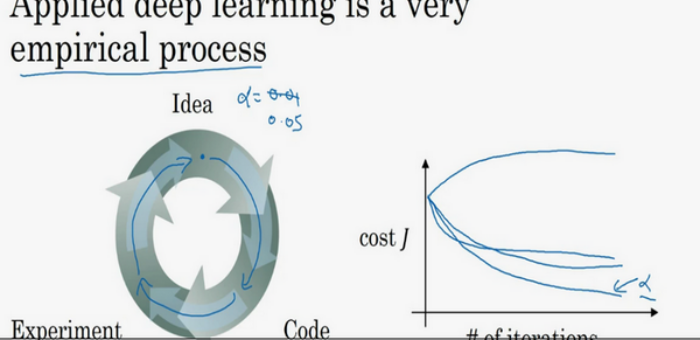
走Idea―Code―Experiment―Idea这个循环,尝试各种不同的参数,实现模型并观察是否成功,然后再迭代。
??今天的深度学习应用领域,还是很经验性的过程,通常你有个想法,比如你可能大致知道一个最好的学习率值,可能说 最好,我会想先试试看,然后你可以实际试一下,训练一下看看效果如何。然后基于尝试的结果你会发现,你觉得学习率设定再提高到0.05会比较好。如果你不确定什么值是最好的,你大可以先试试一个学习率 ,再看看损失函数J的值有没有下降。然后你可以试一试大一些的值,然后发现损失函数的值增加并发散了。然后可能试试其他数,看结果是否下降的很快或者收敛到在更高的位置。你可能尝试不同的 并观察损失函数 这么变了,试试一组值,然后可能损失函数变成这样,这个 值会加快学习过程,并且收敛在更低的损失函数值上(箭头标识),我就用这个 值了。
??在编写一个神经网络的程序时,会有很多不同的超参数。然而,当你开始开发新应用时,预先很难确切知道,究竟超参数的最优值应该是什么。所以通常,你必须尝试很多不同的值,并走这个循环,试试各种参数。试试看5个隐藏层,这个数目的隐藏单元,实现模型并观察是否成功,然后再迭代。应用深度学习领域,这是一个很大程度基于经验的过程,凭经验的过程通俗来说,就是试,直到你找到合适的数值。
??另一个近来深度学习的影响是它用于解决很多问题,从计算机视觉到语音识别,到自然语言处理,到很多结构化的数据应用,比如网络广告或是网页搜索或产品推荐等等。在这建议人们,特别是刚开始应用于新问题的人们,去试一定范围的值看看结果如何。然后其次,甚至是你已经用了很久的模型,可能你在做网络广告应用,在你开发途中,很有可能学习率的最优数值或是其他超参数的最优值是会变的,所以即使你每天都在用当前最优的参数调试你的系统,你还是会发现,最优值过一年就会变化,因为电脑的基础设施,CPU或是GPU可能会变化很大。所以有一条经验规律可能每几个月就会变。如果你所解决的问题需要很多年时间,只要经常试试不同的超参数,勤于检验结果,看看有没有更好的超参数数值,相信你慢慢会得到设定超参数的直觉,知道你的问题最好用什么数值。
??这可能的确是深度学习比较让人不满的一部分,也就是你必须尝试很多次不同可能性。但参数设定这个领域,深度学习研究还在进步中,所以可能过段时间就会有更好的方法决定超参数的值,也很有可能由于CPU、GPU、网络和数据都在变化,这样的指南可能只会在一段时间内起作用,只要你不断尝试,并且尝试保留交叉检验或类似的检验方法,然后挑一个对你的问题效果比较好的数值。