ǰ��
Sunday night������������ģʽ��ϣ�����ܾͿ��Բ���ô��ˮ��hhhh
Kafka�������ճ�����������������Ϊ���õ�����Դ֮һ�������������ͺ�����������������Ҫ�����µ�Kafka topic������Ϊ���е�topic���Ӹ���partition����ô��Kafka������Ϊ�����ߵ�ʵʱ������������θ�֪��topic��partition�仯���أ�������Spark Streaming��FlinkΪ������̽��һ�¡�
Spark Streaming�ij���
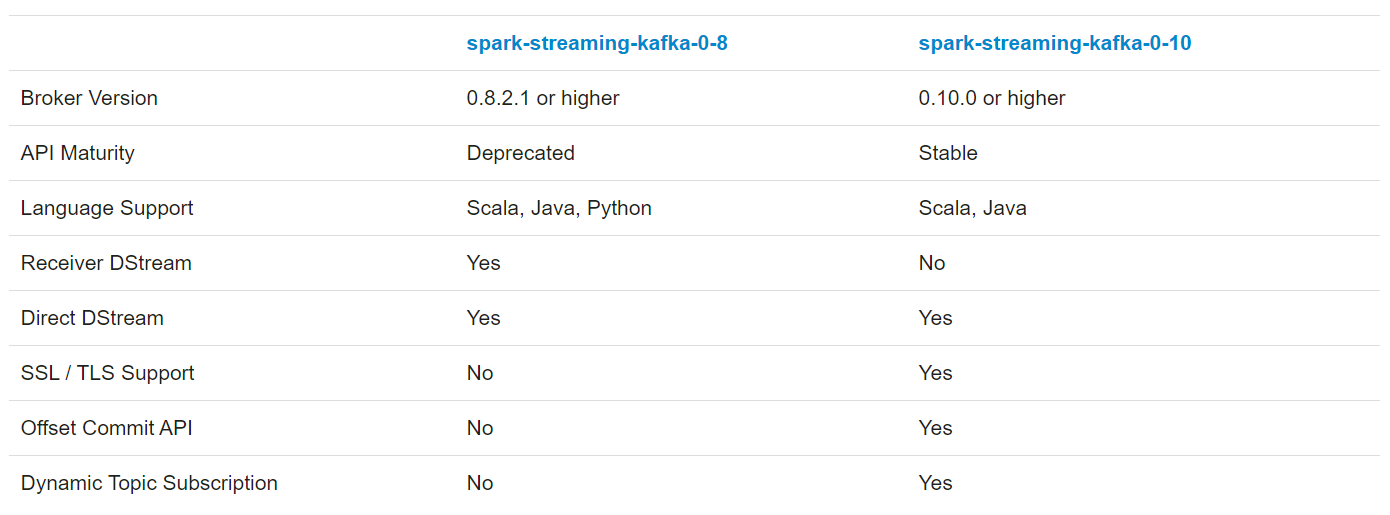
���ݹٷ��ĵ�������ͼ����spark-streaming-kafka-0-10��֧��Kafka�Ķ�̬��֪����Dynamic Topic Subscription��������Դ�룬����o.a.s.streaming.kafka010.DirectKafkaInputDStream�࣬ÿ�����ζ�����õ�compute()�����ĵ�һ�С�
val untilOffsets = clamp(latestOffsets())����˼�壬clamp()���������������ݵ����������ﲻ�ᡣ��latestOffsets()�������ظ���partition��ǰ�����offsetֵ�������ʵ�����£����������õ�paranoidPoll()��������
/*** Returns the latest (highest) available offsets, taking new partitions into account.*/
protected def latestOffsets(): Map[TopicPartition, Long] = {val c = consumerparanoidPoll(c)val parts = c.assignment().asScala// make sure new partitions are reflected in currentOffsetsval newPartitions = parts.diff(currentOffsets.keySet)// Check if there's any partition been revoked because of consumer rebalance.val revokedPartitions = currentOffsets.keySet.diff(parts)if (revokedPartitions.nonEmpty) {throw new IllegalStateException(s"Previously tracked partitions " +s"${revokedPartitions.mkString("[", ",", "]")} been revoked by Kafka because of consumer " +s"rebalance. This is mostly due to another stream with same group id joined, " +s"please check if there're different streaming application misconfigure to use same " +s"group id. Fundamentally different stream should use different group id")}// position for new partitions determined by auto.offset.reset if no commitcurrentOffsets = currentOffsets ++ newPartitions.map(tp => tp -> c.position(tp)).toMap// find latest available offsetsc.seekToEnd(currentOffsets.keySet.asJava)parts.map(tp => tp -> c.position(tp)).toMap
}/*** The concern here is that poll might consume messages despite being paused,* which would throw off consumer position. Fix position if this happens.*/
private def paranoidPoll(c: Consumer[K, V]): Unit = {// don't actually want to consume any messages, so pause all partitionsc.pause(c.assignment())val msgs = c.poll(0)if (!msgs.isEmpty) {// position should be minimum offset per topicpartitionmsgs.asScala.foldLeft(Map[TopicPartition, Long]()) { (acc, m) =>val tp = new TopicPartition(m.topic, m.partition)val off = acc.get(tp).map(o => Math.min(o, m.offset)).getOrElse(m.offset)acc + (tp -> off)}.foreach { case (tp, off) =>logInfo(s"poll(0) returned messages, seeking $tp to $off to compensate")c.seek(tp, off)}}
}�ɼ�����ÿ��compute()����ִ��ʱ������ͨ��paranoidPoll()������seek��ÿ��TopicPartition��Ӧ��offsetλ�ã�����ͨ��latestOffsets()�����ҳ���Щ�¼����partition����ά�����ǵ�offset��ʵ���˶�̬��֪��
����Ҳ���Կ�����Spark Streaming������Kafka Consumer��Rebalance��֮ǰ������������һ��ҪΪ��ͬ��Streaming App���ò�ͬ��group.id��
Flink�ij���
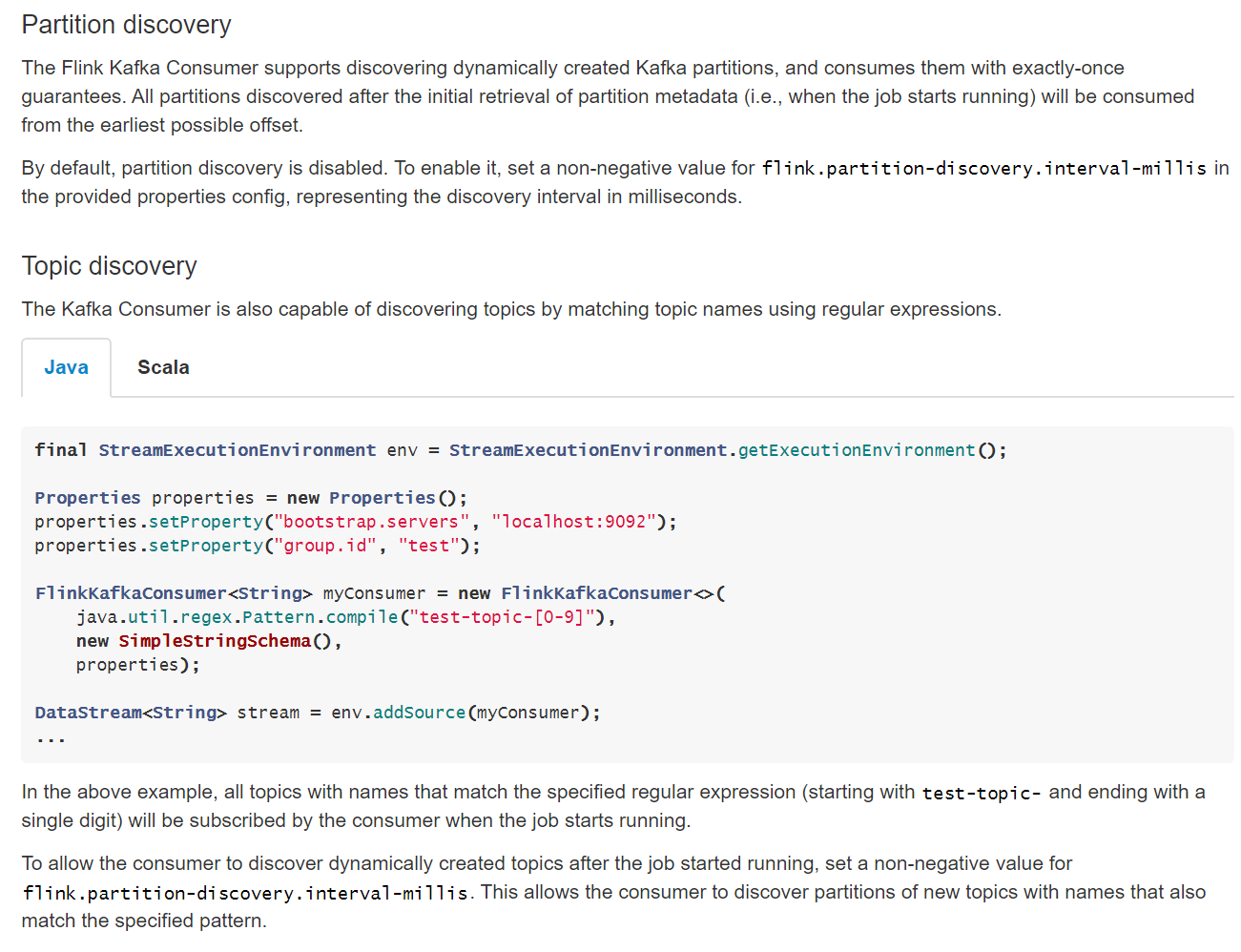
���ݹٷ��ĵ�������ͼ����Flink��֧��Topic/Partition Discovery�ģ�����Ĭ�ϲ�δ��������Ҫ�ֶ�����flink.partition-discovery.interval-millis����������̬��֪��topic/partition�ļ������λ���롣
Flink Kafka Source�Ļ���ʱo.a.f.streaming.connectors.kafka.FlinkKafkaConsumerBase�����࣬����run()�����У����ȴ�����ȡ���ݵ�KafkaFetcher�����ж��Ƿ������˶�̬��֪��
this.kafkaFetcher = createFetcher(sourceContext,subscribedPartitionsToStartOffsets,watermarkStrategy,(StreamingRuntimeContext) getRuntimeContext(),offsetCommitMode,getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),useMetrics);if (!running) {return;
}// depending on whether we were restored with the current state version (1.3),
// remaining logic branches off into 2 paths:
// 1) New state - partition discovery loop executed as separate thread, with this
// thread running the main fetcher loop
// 2) Old state - partition discovery is disabled and only the main fetcher loop is executed
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {kafkaFetcher.runFetchLoop();
} else {runWithPartitionDiscovery();
}��������ˣ����ջ����createAndStartDiscoveryLoop()����������һ���������̣߳�������discoveryIntervalMillisΪ���ڷ����µ�topic/partition�������ݸ�KafkaFetcher��
private void createAndStartDiscoveryLoop(AtomicReference<Exception> discoveryLoopErrorRef) {discoveryLoopThread = new Thread(() -> {try {// --------------------- partition discovery loop ---------------------// throughout the loop, we always eagerly check if we are still running before// performing the next operation, so that we can escape the loop as soon as possiblewhile (running) {if (LOG.isDebugEnabled()) {LOG.debug("Consumer subtask {} is trying to discover new partitions ...", getRuntimeContext().getIndexOfThisSubtask());}final List<KafkaTopicPartition> discoveredPartitions;try {discoveredPartitions = partitionDiscoverer.discoverPartitions();} catch (AbstractPartitionDiscoverer.WakeupException | AbstractPartitionDiscoverer.ClosedException e) {// the partition discoverer may have been closed or woken up before or during the discovery;// this would only happen if the consumer was canceled; simply escape the loopbreak;}// no need to add the discovered partitions if we were closed during the meantimeif (running && !discoveredPartitions.isEmpty()) {kafkaFetcher.addDiscoveredPartitions(discoveredPartitions);}// do not waste any time sleeping if we're not running anymoreif (running && discoveryIntervalMillis != 0) {try {Thread.sleep(discoveryIntervalMillis);} catch (InterruptedException iex) {// may be interrupted if the consumer was canceled midway; simply escape the loopbreak;}}}} catch (Exception e) {discoveryLoopErrorRef.set(e);} finally {// calling cancel will also let the fetcher loop escape// (if not running, cancel() was already called)if (running) {cancel();}}}, "Kafka Partition Discovery for " + getRuntimeContext().getTaskNameWithSubtasks());discoveryLoopThread.start();
}�ɼ���Flinkͨ����ΪPartitionDiscoverer�������ʵ�ֶ�̬��֪������Ĵ����е�����discoverPartitions()��������Դ�����¡�
public List<KafkaTopicPartition> discoverPartitions() throws WakeupException, ClosedException {if (!closed && !wakeup) {try {List<KafkaTopicPartition> newDiscoveredPartitions;// (1) get all possible partitions, based on whether we are subscribed to fixed topics or a topic patternif (topicsDescriptor.isFixedTopics()) {newDiscoveredPartitions = getAllPartitionsForTopics(topicsDescriptor.getFixedTopics());} else {List<String> matchedTopics = getAllTopics();// retain topics that match the patternIterator<String> iter = matchedTopics.iterator();while (iter.hasNext()) {if (!topicsDescriptor.isMatchingTopic(iter.next())) {iter.remove();}}if (matchedTopics.size() != 0) {// get partitions only for matched topicsnewDiscoveredPartitions = getAllPartitionsForTopics(matchedTopics);} else {newDiscoveredPartitions = null;}}// (2) eliminate partition that are old partitions or should not be subscribed by this subtaskif (newDiscoveredPartitions == null || newDiscoveredPartitions.isEmpty()) {throw new RuntimeException("Unable to retrieve any partitions with KafkaTopicsDescriptor: " + topicsDescriptor);} else {Iterator<KafkaTopicPartition> iter = newDiscoveredPartitions.iterator();KafkaTopicPartition nextPartition;while (iter.hasNext()) {nextPartition = iter.next();if (!setAndCheckDiscoveredPartition(nextPartition)) {iter.remove();}}}return newDiscoveredPartitions;} catch (WakeupException e) {// the actual topic / partition metadata fetching methods// may be woken up midway; reset the wakeup flag and rethrowwakeup = false;throw e;}} else if (!closed && wakeup) {// may have been woken up before the method callwakeup = false;throw new WakeupException();} else {throw new ClosedException();}���ȣ�����ݴ�����ǵ����̶���topic�������������ʽָ���Ķ��topics���ֱ��������ն�����getAllPartitionsForTopics()��������ȡ��Щtopic������partition����������ɳ�����AbstractPartitionDiscoverer�ĸ�������ʵ�֣��ܼ���Ȼ��������Щpartition��������setAndCheckDiscoveredPartition()���������֮ǰ�Ƿ����ѹ����ǣ�����ǣ����Ƴ�֮����֤�������ص����¼����partition��
The End
���������ש����������������