前言
在之前的这篇文章中,笔者介绍了用时序数据库InfluxDB作为Flink监控存储的方法,并且提到为了防止磁盘爆掉,要设置保留策略来使数据自动过期。经过一点探究之后,发现“Retention Policy”这个词在InfluxDB里并不只是字面意思那么简单,本文做个简要记录。
InfluxDB的存储体系
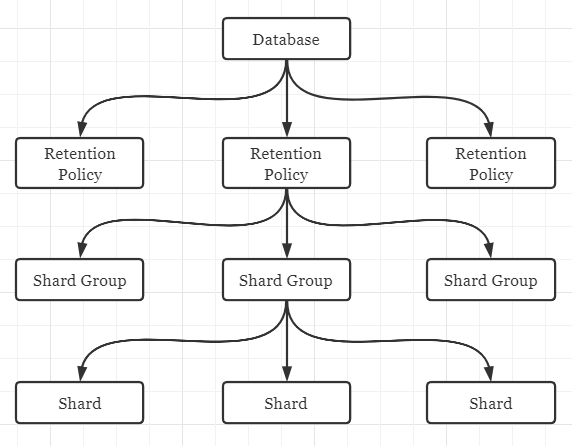
之前说过,InfluxDB的存储引擎是由LSM Tree改进而来的TSM(Time-Structured Merge)Tree引擎,所以它和LSM Tree有一些相似之处。hierarchy图示如下。
Shard
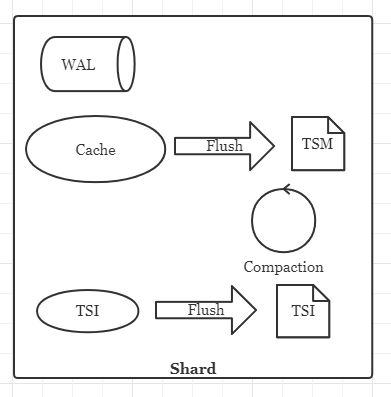
Shard类似于HBase的Region和Kudu的Tablet,是数据编码、存储、写入和读取的交互单元。它由如下几部分组成:
- WAL(预写日志,相当于HLog)
- Cache(写缓存,相当于MemStore)
- TSM File(数据存储文件,相当于HFile)
- TSI/TSI File(内存中的倒排索引及磁盘上的索引文件,方便查询)
另外当然也有负责Flush、Compaction的逻辑。
需要注意,InfluxDB在存储数据时,是根据series(即measurement与tag set的一个唯一组合)的哈希值来决定落在哪个Shard中的,哈希分桶数――即Shard的数目――在商用版中可以调整。这样就使得series相同的数据落在相同的Shard里,有利于提高查询效率。同时也会使一个Shard中可能包含多个measurement的数据(相对地,一个HBase Region只会包含一张表的数据),有利于负载均衡。
Shard Group
Shard Group是一个逻辑概念,顾名思义,它就是包含多个Shard的组合。Shard Group的重要特性是时间分区性,即每个Shard Group只会存储一段时间内的数据,各个Shard Group对应的时间区间不会交叉。时序数据库上的查询几乎全都会带有时间维度的过滤条件,Shard Group按时间区间的组织形式可以很高效地实现partition pruning,另外也方便下文所说的数据过期。
Retention Policy (RP)
在官方文档的Glossary中,对Retention Policy一词的定义如下:
The part of InfluxDB’s data structure that describes for how long InfluxDB keeps data (duration), how many copies of those data are stored in the cluster (replication factor), and the time range covered by shard groups (shard group duration). RPs are unique per database and along with the measurement and tag set define a series.
可见,InfluxDB的保留策略除了描述数据的TTL duration之外,还包含数据的副本数(replication factor),以及每个Shard Group的时间区间长度,信息量很大。注意InfluxDB的保留策略不是定义在表上的,而是定义在数据库上的,并且以Shard Group为单位做批量过期。
另外,每个数据库可以配置多种不同的保留策略,但是默认的只能有一个,数据写入时也只能选择一个保留策略(其实是保留策略下面的Shard Group)作为目的地。下面简单介绍一下保留策略的配置。
保留策略的配置
在数据库上创建保留策略的语法如下。
CREATE RETENTION POLICY <retention_policy_name> ON <database_name>
DURATION <duration>
REPLICATION <replication_num>
[SHARD DURATION <shard_duration>] [DEFAULT]其中:
- <retention_policy_name>是保留策略的名称;
- <database_name>是数据库的名称;
- <duration>是数据的TTL;
- <replication_num>是数据的副本数;
- <shard_duration>是可选项,表示每个Shard Group的时间区间长度;
- DEFAULT也是可选项,如果指定,表示将此策略顺便设为默认。
如果不指定shard duration的话,当duration小于2天时,shard duration默认为1小时;duration介于2天和6个月之间时,shard duration默认为1天;duration大于6个月时,shard duration默认为7天。
创建数据库时,默认会随着创建一个名为autogen的保留策略,shard duration为7天,而duration为0秒(即永远不过期)。
> USE flink_metrics
Using database flink_metrics
> SHOW RETENTION POLICIES
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 true接下来创建一个新的TTL为一周的保留策略,并设为默认,再观察一下。
> CREATE RETENTION POLICY "one_week" ON "flink_metrics" DURATION 7d REPLICATION 1 DEFAULT> SHOW RETENTION POLICIES
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
one_week 168h0m0s 24h0m0s 1 true如果需要修改或者删除保留策略,可以采用ALTER RETENTION POLICY和DROP RETENTION POLICY语法,不再赘述。